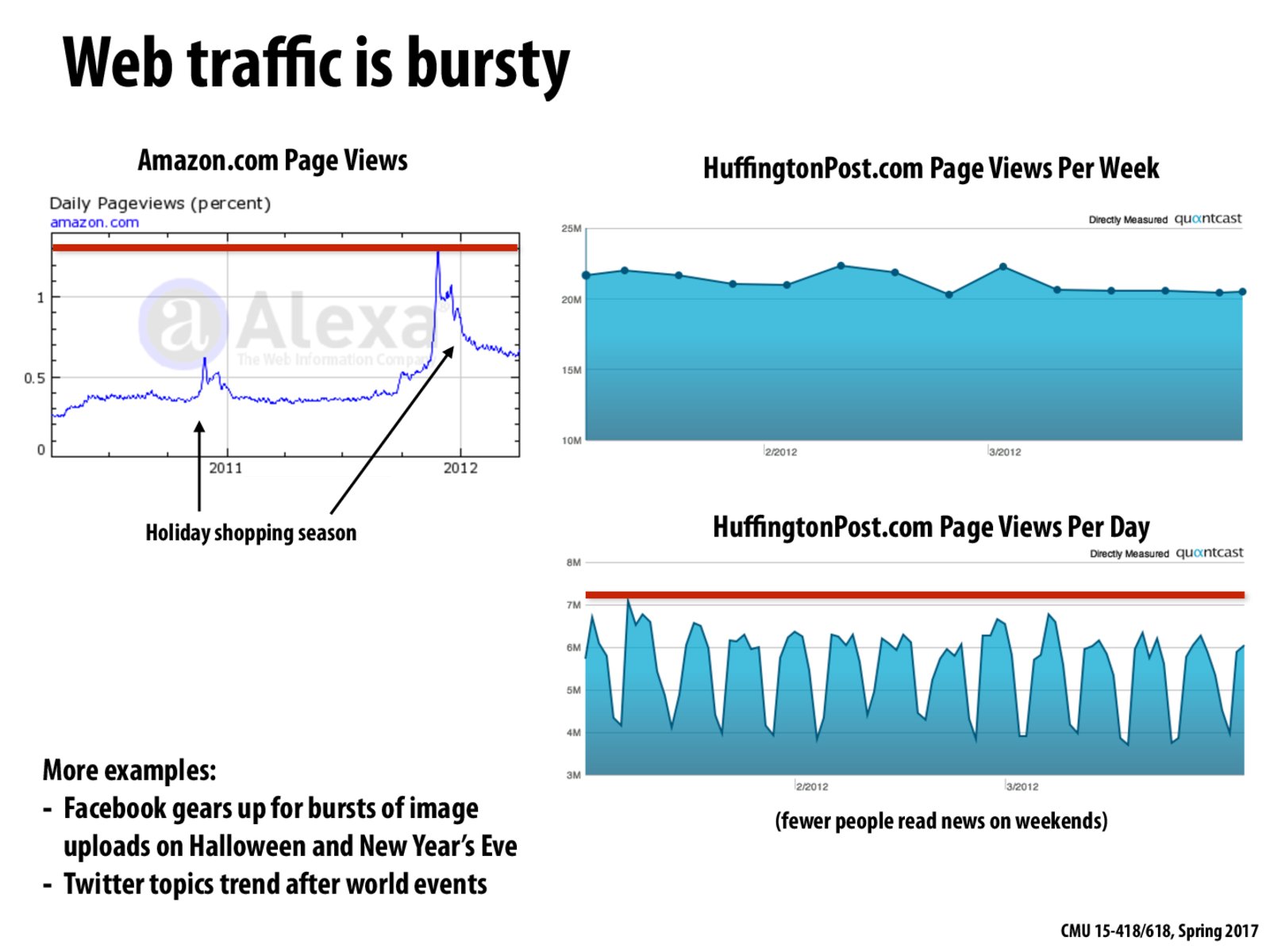
We also had to deal with this problem in Assignment 4, where we had to be able to anticipate an incoming spike in request load, and preemptively spawn new worker nodes, such that the time it takes for them to boot up is a non issue, and it can start servicing requests right away. We also watched for times of low load, and killed any worker nodes that were inactive for too long.
dyzz
For large bursts or cases where startup costs/time of resources are slow, it would be an interesting field of study to predict when bursts will happen so resources can be provisioned and unprovisioned ahead of time. I can imagine the cost savings would be dramatic in predictable but extremely bursty environments.
We also had to deal with this problem in Assignment 4, where we had to be able to anticipate an incoming spike in request load, and preemptively spawn new worker nodes, such that the time it takes for them to boot up is a non issue, and it can start servicing requests right away. We also watched for times of low load, and killed any worker nodes that were inactive for too long.
For large bursts or cases where startup costs/time of resources are slow, it would be an interesting field of study to predict when bursts will happen so resources can be provisioned and unprovisioned ahead of time. I can imagine the cost savings would be dramatic in predictable but extremely bursty environments.