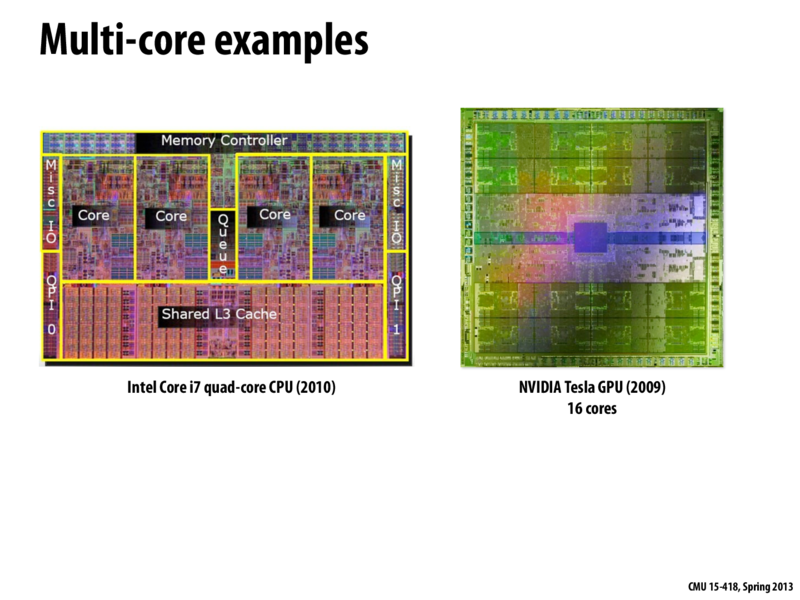
We should be careful how we count cores with all the company-specific terminology out there. As we'll discuss in a future GPU architecture lecture, NVIDIA's "CUDA cores" can't be thought of as 1-to-1 with CPU-style processor cores. The best analogy for a CUDA core, in the language of this lecture, is a single ALU/execution unit (one of my yellow boxes).
The GK110 chip that the K20 is based on has thirteen SMX blocks (SMX block ~ "core"). Each block as 192 single-precision execution units (we'll ignore the double-precision ones for now), which execute in a SIMD manner in groups of 32 (so for each SMX block there are six groups of 32 ALUs, each group executes in SIMD lockstep). Each SMX block interleaves execution of up to 64 warps (warp ~ "hardware thread"). Each clock, the SMX block selects up to four different runnable warps, and runs up to two independent instructions per each warp, so there's a total of up to eight instructions issued per SMX block per clock. As I said before, each instruction governs the behavior of 32 SIMD ALUs.
Complicated eh? So let's break it down:
There's thirteen SMX blocks (think cores). The unit of scaling the chip up or down is this block.
We're going to interleave processing of up to 64 independent instruction streams (warps) on each of these blocks. Instructions in the instruction stream execute 32-wide using what I previously called implicit SIMD execution.
The SMX employs both simultaneous multi-threading (four warps can be run at once) and interleaved multi-threading (scheduling for a total of 64 warps are managed by the SMX block). The chip also exploits ILP within the instruction stream of a warp: up to two instructions can be dispatched per cycle for each of the scheduled warps.
Where does the number 2,496 come from?
13 SMX blocks * (6 * 32-wide SIMD ALUs per SMX) = 2,496 single-precision ALUs clocked at 705 MHz.
What's peak single-precision performance, assume we count a multiply-add (MAD) as two floating point ops?
13 SMX blocks * 6 * 32 * 705 MHz * 2 = 3.5 TFlops
So the right comparison with a 3 GHz quad-core Intel Core i7 chip would be:
4 cores * 8 * 3 GHz * 2 = 192 GFlops
So for a workload that only performed multiply-add operations on a bunch of independent pieces of data, the K20 would be about 18 times faster than the quad-core Core i7. Would it be more power efficient as well? Likely so, but as @lkung points out, it's hard to compare TDPs reported by manufactures. Not only are there differences between reporting TDP as peak draw or average draw, the K20 TPD of 285 watts probably includes power expended by GPU memory, whereas the Intel Core i7 TDP of 80-100 watts likely does not. (Someone should correct me if I'm wrong on this.)
In a subsequent slide in this lecture about the older NVIDIA GTX 480 GPU, I draw similar comparisons between the generic terminology I like to use with the terminology NVIDIA uses.
The gates machines have 4 cores, which in theory, should reach their maximum speedup when we have 4 threads. However, in the problem 1 of the homework, the speedup of the program is even boosted when I create more than 4 threads. Can someone explain why that happens? Is it because of the hyper-threading? And can anyone give me a detailed explanation of what is hyper-threading please?
This comment was marked helpful 0 times.
Xiao
@bosher, Gates' 5201/5205 machines don't have hyper-threading enabled. So you should reason that question using 4 cores, and you will have to come up with the explanation yourself :)
For a more detailed explanation of hyper-threading, slide 47 describes more or less how hyper-threading works. This is another interesting reading for hyper-threading.
This comment was marked helpful 2 times.
bourne
Some general stuff I read about the Xbox 360: It has 3 cores that have hyper threading. According to wikipedia the SIMD vector processor was modified to include dot product. According to this article the Xenon processor doesn't have any out of order execution and is short on branch prediction. The processor is slower in many ways in favor of having multiple cores and purposefully puts more of a burden on the programmer.
This comment was marked helpful 0 times.
aakashr
@bosher, it happens because if the workload is not evenly distributed, then some threads could be sitting idle waiting for the one that takes the longest time to finish. Having more threads counteracts this. But having too many threads can be a bad thing as well because then a lot of time can be spent handling the assignment of work to the threads.
This comment was marked helpful 0 times.
kayvonf
@bosher and @aakashr. I want to make sure you understand that in assignment 1, many students decomposed the problem into many more ISPC tasks than machine processors. In your answer you said thread. If you are writing "thread" because you are thinking of pthread-style parallel execution (or thread execution context in the processors) you should take a moment to consider how many ISPC tasks are distributed to processors by the ISPC runtime.
Recently released NVIDIA Tesla GPU K20 has 2496 cores. For more information, visit http://www.nvidia.com/object/workstation-solutions-tesla.html
This comment was marked helpful 0 times.
We should be careful how we count cores with all the company-specific terminology out there. As we'll discuss in a future GPU architecture lecture, NVIDIA's "CUDA cores" can't be thought of as 1-to-1 with CPU-style processor cores. The best analogy for a CUDA core, in the language of this lecture, is a single ALU/execution unit (one of my yellow boxes).
The GK110 chip that the K20 is based on has thirteen SMX blocks (SMX block ~ "core"). Each block as 192 single-precision execution units (we'll ignore the double-precision ones for now), which execute in a SIMD manner in groups of 32 (so for each SMX block there are six groups of 32 ALUs, each group executes in SIMD lockstep). Each SMX block interleaves execution of up to 64 warps (warp ~ "hardware thread"). Each clock, the SMX block selects up to four different runnable warps, and runs up to two independent instructions per each warp, so there's a total of up to eight instructions issued per SMX block per clock. As I said before, each instruction governs the behavior of 32 SIMD ALUs.
Complicated eh? So let's break it down:
There's thirteen SMX blocks (think cores). The unit of scaling the chip up or down is this block.
We're going to interleave processing of up to 64 independent instruction streams (warps) on each of these blocks. Instructions in the instruction stream execute 32-wide using what I previously called implicit SIMD execution.
The SMX employs both simultaneous multi-threading (four warps can be run at once) and interleaved multi-threading (scheduling for a total of 64 warps are managed by the SMX block). The chip also exploits ILP within the instruction stream of a warp: up to two instructions can be dispatched per cycle for each of the scheduled warps.
Where does the number 2,496 come from?
13 SMX blocks * (6 * 32-wide SIMD ALUs per SMX) = 2,496 single-precision ALUs clocked at 705 MHz.
What's peak single-precision performance, assume we count a multiply-add (MAD) as two floating point ops?
13 SMX blocks * 6 * 32 * 705 MHz * 2 = 3.5 TFlops
So the right comparison with a 3 GHz quad-core Intel Core i7 chip would be:
4 cores * 8 * 3 GHz * 2 = 192 GFlops
So for a workload that only performed multiply-add operations on a bunch of independent pieces of data, the K20 would be about 18 times faster than the quad-core Core i7. Would it be more power efficient as well? Likely so, but as @lkung points out, it's hard to compare TDPs reported by manufactures. Not only are there differences between reporting TDP as peak draw or average draw, the K20 TPD of 285 watts probably includes power expended by GPU memory, whereas the Intel Core i7 TDP of 80-100 watts likely does not. (Someone should correct me if I'm wrong on this.)
In a subsequent slide in this lecture about the older NVIDIA GTX 480 GPU, I draw similar comparisons between the generic terminology I like to use with the terminology NVIDIA uses.
Source: NVIDIA Kepler Compute Architecture Whitepaper
This comment was marked helpful 0 times.
The gates machines have 4 cores, which in theory, should reach their maximum speedup when we have 4 threads. However, in the problem 1 of the homework, the speedup of the program is even boosted when I create more than 4 threads. Can someone explain why that happens? Is it because of the hyper-threading? And can anyone give me a detailed explanation of what is hyper-threading please?
This comment was marked helpful 0 times.
@bosher, Gates' 5201/5205 machines don't have hyper-threading enabled. So you should reason that question using 4 cores, and you will have to come up with the explanation yourself :)
For a more detailed explanation of hyper-threading, slide 47 describes more or less how hyper-threading works. This is another interesting reading for hyper-threading.
This comment was marked helpful 2 times.
Some general stuff I read about the Xbox 360: It has 3 cores that have hyper threading. According to wikipedia the SIMD vector processor was modified to include dot product. According to this article the Xenon processor doesn't have any out of order execution and is short on branch prediction. The processor is slower in many ways in favor of having multiple cores and purposefully puts more of a burden on the programmer.
This comment was marked helpful 0 times.
@bosher, it happens because if the workload is not evenly distributed, then some threads could be sitting idle waiting for the one that takes the longest time to finish. Having more threads counteracts this. But having too many threads can be a bad thing as well because then a lot of time can be spent handling the assignment of work to the threads.
This comment was marked helpful 0 times.
@bosher and @aakashr. I want to make sure you understand that in assignment 1, many students decomposed the problem into many more ISPC tasks than machine processors. In your answer you said thread. If you are writing "thread" because you are thinking of pthread-style parallel execution (or thread execution context in the processors) you should take a moment to consider how many ISPC tasks are distributed to processors by the ISPC runtime.
This comment was marked helpful 0 times.