SIMD processing focuses on distributing data across parallel processors. The body of the loop in the sin function, for example, was essentially using the same logic every iteration, just on a different piece of data. In this idea, we take our ALU unit, and make eight of them. This lets us have our same processor that processes one instruction per clock, but actually executes it on eight pieces of data at once.
This comment was marked helpful 2 times.
martin
a typical example would be C[i] = A[i] + B[i]. Assume this requires a lot of memory access, but this could be vectorized. And hence SIMD processing can executes on multiple (8 pieces of data in this case) at the same time. SIMD processing is more popular in GPU because images can easily have a million pixels and it is common that you may need to perform the same algorithm/operations on each (when you zoom in a picture for example). So it is very useful for GPU to have SIMD processing.
This comment was marked helpful 0 times.
jedavis
To provide an even more concrete example of the applicability of SIMD instructions and vectorization, I spent last summer working at Microsoft adding auto-vectorization for averaging to their C++ compiler (getting the compiler to safely emit PAVGW and PAVGB instructions). Our main demo case was blurring image filters on bitmaps, where we got speedups of around 10-15x, which while below the theoretical maximum (16x if averaging 16 pairs of 8-bit chars in a 128-bit XMM register) was still appreciable.
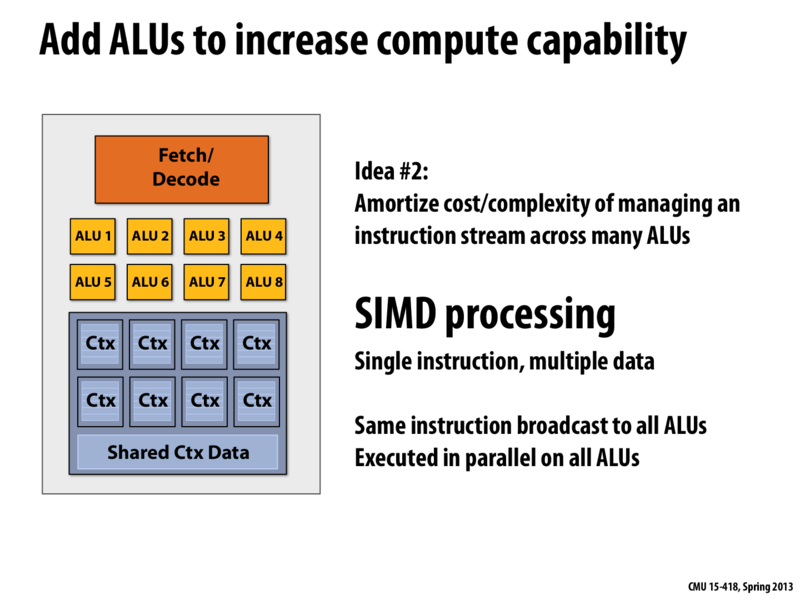
SIMD processing focuses on distributing data across parallel processors. The body of the loop in the sin function, for example, was essentially using the same logic every iteration, just on a different piece of data. In this idea, we take our ALU unit, and make eight of them. This lets us have our same processor that processes one instruction per clock, but actually executes it on eight pieces of data at once.
This comment was marked helpful 2 times.
a typical example would be
C[i] = A[i] + B[i]. Assume this requires a lot of memory access, but this could be vectorized. And hence SIMD processing can executes on multiple (8 pieces of data in this case) at the same time. SIMD processing is more popular in GPU because images can easily have a million pixels and it is common that you may need to perform the same algorithm/operations on each (when you zoom in a picture for example). So it is very useful for GPU to have SIMD processing.This comment was marked helpful 0 times.
To provide an even more concrete example of the applicability of SIMD instructions and vectorization, I spent last summer working at Microsoft adding auto-vectorization for averaging to their C++ compiler (getting the compiler to safely emit PAVGW and PAVGB instructions). Our main demo case was blurring image filters on bitmaps, where we got speedups of around 10-15x, which while below the theoretical maximum (16x if averaging 16 pairs of 8-bit chars in a 128-bit XMM register) was still appreciable.
This comment was marked helpful 1 times.