Examples of worst case: Switch statement with 8 branches (only one "lane" does useful work at once), or an if-else statement where one ALU does a lot of work in one case, and the other 7 get almost full parallelism out of the other case but is very short. In this case, one ALU does almost all the work.
This comment was marked helpful 0 times.
mschervi
Are processors smart enough not to execute a branch if none of the "lanes" need it? Otherwise it seems like worst case could be arbitrarily bad.
This comment was marked helpful 0 times.
kayvonf
@mschervi: There's a critical point about this slide that I want to make, and it should be more clear once you write a bit of ISPC code in Assignment 1: The code on the right is a single sequential sequence of control. The variable x is meant to be single floating-point value (e.g., 'float x'). Now assume that this code might be the body of a loop with independent iterations, such as the forall loop I showed on slide 17. So let's say we're running this code for each element in an array 'A', and for each iteration of the loop x is initialized to A[i].
Now, we know we have SIMD execution capabilities on a processor and we'd like to make use of them to run faster. However, we have a program that's written against an abstraction where each iteration of the loop has it's own control flow. No notion of SIMD execution is present at the programming language level.
The problem at hand is how to map a program written against this abstraction onto the actual execution resources, which have constraints not exposed at the language level. (For example, the mapping would become trivial if if statements were not allowed in the language, forcing all iterations to have the same instruction sequence.)
On slide 33 I point out that the act of mapping such a program into an efficient SIMD implementation can be responsibility of a compiler or it could be the responsibility of the hardware itself (as in slide 34, and as you allude to in your comment about whether the processor is "smart enough" to perform this mapping intelligently). One example of the former case is the ISPC compiler. It emits SSE or AVX instructions into its compiled programs that generate lane masks, use the lane masks to prevent certain writes, and also generates code that handles the branching logic in the manner we discussed in class. The processor (e.g., the CPU in the case of ISPC) just executes the instructions it's told. There's no smarts needed. All the smarts are in the compiler.
If you really want to internalize what it means for a compiler to emit such code, you'll need to try doing it by hand once. That just happens to be the Program 4 extra credit on Assignment 1.
On the other side of the design spectrum, the compiler can be largely oblivious to SIMD capabilities of hardware, and most of the smarts can go into the hardware itself. To date, this has been the GPU-style way of doing things. Although we'll talk about GPUs in detail later in the course, here's a good way to think about it for now: The GPU will accept a mini-program written to process a single data item (e.g., you can think of the mini-program as a loop body) as well as a number of times the mini-program should be run. It's like the interface to the hardware itself is a foreach loop.
This comment was marked helpful 0 times.
ghotz
@mschervi: Probably not, though conditional execution is usually only used for short sequences. Depends on how it's implemented. ARM for example would still "run" through the instructions, as the idea is to avoid control flow entirely.
This comment was marked helpful 0 times.
kuity
Can someone explain why is it that not all ALUs are doing useful work? So for this case, the ALUs in lanes 3, 5, 6, 7, 8 are not doing useful work? If that is so, is it because they run the computation for the 'true' case which is wasted in the end?
This comment was marked helpful 0 times.
alex
@kuity That is exactly right - the ALUs 3,5,6,7, and 8 all 'do work' that is discarded for the 'true' case.
This comment was marked helpful 0 times.
ToBeContinued
@kayvonf Can you clarify a bit how GPU compilers are "largely oblivious to SIMD capabilities of hardware"? And how is GPU parallelism different from SIMD except the number of computing cores? From what I know, CUDA use the concept of "kernel", which is similar to "mini-program" we are talking about here. And the same kernel code is mapped on to many different CUDA cores. This seem to me very similar to SIMD, except NVIDIA GPUs usually have hundreds of CUDA cores.
This comment was marked helpful 0 times.
Arnie
Remember that in divergent execution, SIMD can actually be slower than regular serial execution if the compiler compiles for SIMD at a higher width than the hardware can handle. We saw this in Assignment 1. For example, let's say the vector width of the hardware is 2 and the compiler is using a width of 4. If the first 3 elements take 1 cycle and the last one takes 8, then we will be using 9 cycles on the first two elements and 9 cycles on the last two elements, because for the purposes of divergence, the width is 4, even if the hardware can only do 2 elements at a time. So, it takes 18 cycles this way. But if we did it sequentially, it would only take 11.
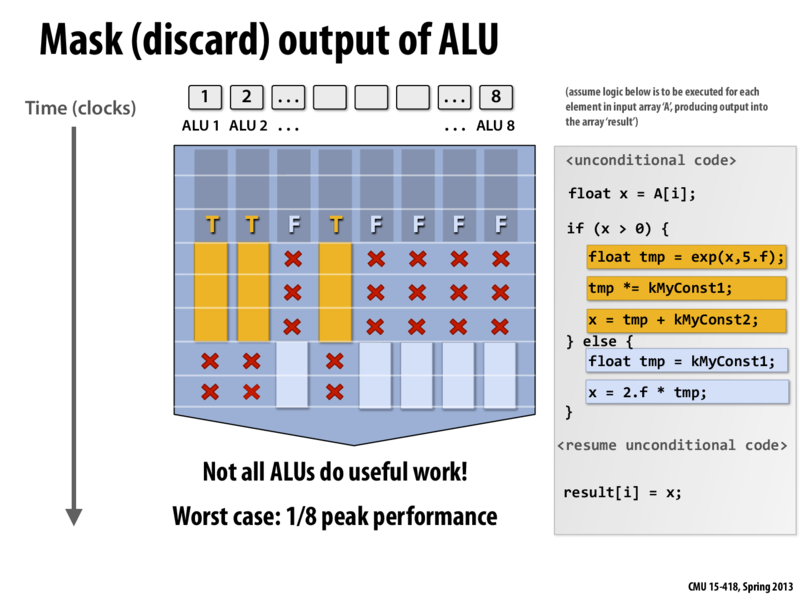
Examples of worst case: Switch statement with 8 branches (only one "lane" does useful work at once), or an if-else statement where one ALU does a lot of work in one case, and the other 7 get almost full parallelism out of the other case but is very short. In this case, one ALU does almost all the work.
This comment was marked helpful 0 times.
Are processors smart enough not to execute a branch if none of the "lanes" need it? Otherwise it seems like worst case could be arbitrarily bad.
This comment was marked helpful 0 times.
@mschervi: There's a critical point about this slide that I want to make, and it should be more clear once you write a bit of ISPC code in Assignment 1: The code on the right is a single sequential sequence of control. The variable
xis meant to be single floating-point value (e.g., 'float x'). Now assume that this code might be the body of a loop with independent iterations, such as theforallloop I showed on slide 17. So let's say we're running this code for each element in an array 'A', and for each iteration of the loopxis initialized toA[i].Now, we know we have SIMD execution capabilities on a processor and we'd like to make use of them to run faster. However, we have a program that's written against an abstraction where each iteration of the loop has it's own control flow. No notion of SIMD execution is present at the programming language level.
The problem at hand is how to map a program written against this abstraction onto the actual execution resources, which have constraints not exposed at the language level. (For example, the mapping would become trivial if
ifstatements were not allowed in the language, forcing all iterations to have the same instruction sequence.)On slide 33 I point out that the act of mapping such a program into an efficient SIMD implementation can be responsibility of a compiler or it could be the responsibility of the hardware itself (as in slide 34, and as you allude to in your comment about whether the processor is "smart enough" to perform this mapping intelligently). One example of the former case is the ISPC compiler. It emits SSE or AVX instructions into its compiled programs that generate lane masks, use the lane masks to prevent certain writes, and also generates code that handles the branching logic in the manner we discussed in class. The processor (e.g., the CPU in the case of ISPC) just executes the instructions it's told. There's no smarts needed. All the smarts are in the compiler.
If you really want to internalize what it means for a compiler to emit such code, you'll need to try doing it by hand once. That just happens to be the Program 4 extra credit on Assignment 1.
On the other side of the design spectrum, the compiler can be largely oblivious to SIMD capabilities of hardware, and most of the smarts can go into the hardware itself. To date, this has been the GPU-style way of doing things. Although we'll talk about GPUs in detail later in the course, here's a good way to think about it for now: The GPU will accept a mini-program written to process a single data item (e.g., you can think of the mini-program as a loop body) as well as a number of times the mini-program should be run. It's like the interface to the hardware itself is a
foreachloop.This comment was marked helpful 0 times.
@mschervi: Probably not, though conditional execution is usually only used for short sequences. Depends on how it's implemented. ARM for example would still "run" through the instructions, as the idea is to avoid control flow entirely.
This comment was marked helpful 0 times.
Can someone explain why is it that not all ALUs are doing useful work? So for this case, the ALUs in lanes 3, 5, 6, 7, 8 are not doing useful work? If that is so, is it because they run the computation for the 'true' case which is wasted in the end?
This comment was marked helpful 0 times.
@kuity That is exactly right - the ALUs 3,5,6,7, and 8 all 'do work' that is discarded for the 'true' case.
This comment was marked helpful 0 times.
@kayvonf Can you clarify a bit how GPU compilers are "largely oblivious to SIMD capabilities of hardware"? And how is GPU parallelism different from SIMD except the number of computing cores? From what I know, CUDA use the concept of "kernel", which is similar to "mini-program" we are talking about here. And the same kernel code is mapped on to many different CUDA cores. This seem to me very similar to SIMD, except NVIDIA GPUs usually have hundreds of CUDA cores.
This comment was marked helpful 0 times.
Remember that in divergent execution, SIMD can actually be slower than regular serial execution if the compiler compiles for SIMD at a higher width than the hardware can handle. We saw this in Assignment 1. For example, let's say the vector width of the hardware is 2 and the compiler is using a width of 4. If the first 3 elements take 1 cycle and the last one takes 8, then we will be using 9 cycles on the first two elements and 9 cycles on the last two elements, because for the purposes of divergence, the width is 4, even if the hardware can only do 2 elements at a time. So, it takes 18 cycles this way. But if we did it sequentially, it would only take 11.
This comment was marked helpful 0 times.