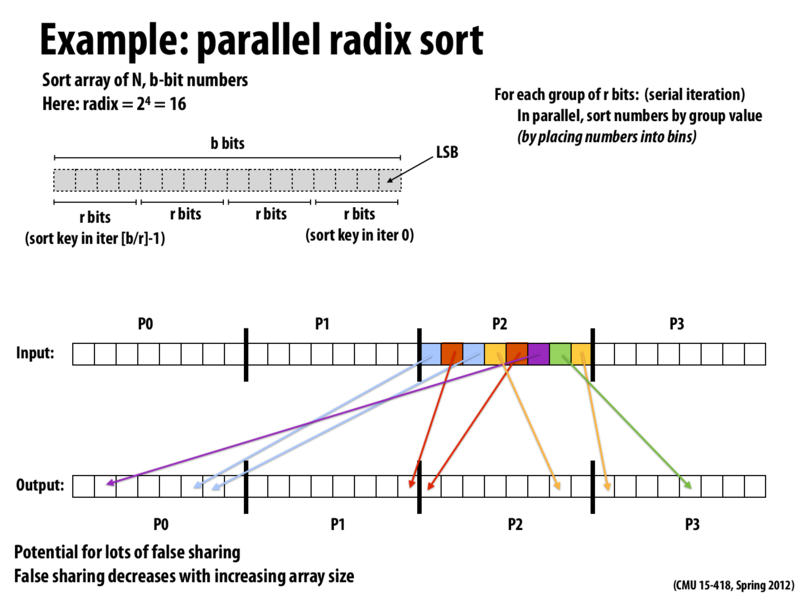
Parallel radix sort is prone to the false sharing problem because the edge of one processor's assigned block of data could be in the same cache line as the adjacent edge of another processor's assigned block of data. For example, the two red blocks will with high likelihood be in the same cache line because they are right next to each other (even though different processors are responsible for them), and this will cause a false sharing problem.
Increasing the array size decreases false sharing because a smaller portion of the data will be on shared cache lines. On the other hand, increasing the number of processors will divide the array further and will thus aggravate the false sharing problem.
This comment was marked helpful 0 times.
kayvonf
I'd like to clarify why false sharing occurs in this example. The figure illustrates how, in each round of the radix sort, each processor will compute the bin in the output array that its input array elements should be moved to (elements assigned to P2 are colored according to their bin). Given the mapping of elements to bins, the algorithm then computes the precise output location each element should be moved to. Each processor then scatters its elements to the appropriate location in the output array (as shown by the arrows in the figure).
By the nature of a stable radix sort, each process P writes its elements that belong to the same bin to a contiguous region of the output array. In this example, P2 never writes more than two consecutive elements to the output, since it is not assigned more than two elements mapping to the same bin. Noe remember that P0, P1, and P3 are also scattering their elements into the output. The result is an access pattern where each processor is scattering data all over memory.
Now recall that to perform a write, a processor must first obtain exclusive access to the cache line containing the address. In the case of radix sort above, many processors might end up writing to the same cache line (since it's likely all processors have elements falling in each bin). This will cause the cache line to bounce all around the machine. There is no inherent communication between the processors in the scatter step of the algorithm, so the extra cache invalidations during the scatter are due to false sharing.
Notice that if the array to sort is very large, each processor is responsible for more data, and it is more likely that each processor will write larger ranges of contiguous elements to the output array. This decreases false sharing by dropping the likelihood multiple processors write to the same line. Conversely, if the number of processors is large, the number of elements per processor decreases, leading again to few contiguous writes per processor, and thus more false sharing.
Parallel radix sort is prone to the false sharing problem because the edge of one processor's assigned block of data could be in the same cache line as the adjacent edge of another processor's assigned block of data. For example, the two red blocks will with high likelihood be in the same cache line because they are right next to each other (even though different processors are responsible for them), and this will cause a false sharing problem.
Increasing the array size decreases false sharing because a smaller portion of the data will be on shared cache lines. On the other hand, increasing the number of processors will divide the array further and will thus aggravate the false sharing problem.
This comment was marked helpful 0 times.
I'd like to clarify why false sharing occurs in this example. The figure illustrates how, in each round of the radix sort, each processor will compute the bin in the output array that its input array elements should be moved to (elements assigned to P2 are colored according to their bin). Given the mapping of elements to bins, the algorithm then computes the precise output location each element should be moved to. Each processor then scatters its elements to the appropriate location in the output array (as shown by the arrows in the figure).
By the nature of a stable radix sort, each process P writes its elements that belong to the same bin to a contiguous region of the output array. In this example, P2 never writes more than two consecutive elements to the output, since it is not assigned more than two elements mapping to the same bin. Noe remember that P0, P1, and P3 are also scattering their elements into the output. The result is an access pattern where each processor is scattering data all over memory.
Now recall that to perform a write, a processor must first obtain exclusive access to the cache line containing the address. In the case of radix sort above, many processors might end up writing to the same cache line (since it's likely all processors have elements falling in each bin). This will cause the cache line to bounce all around the machine. There is no inherent communication between the processors in the scatter step of the algorithm, so the extra cache invalidations during the scatter are due to false sharing.
Notice that if the array to sort is very large, each processor is responsible for more data, and it is more likely that each processor will write larger ranges of contiguous elements to the output array. This decreases false sharing by dropping the likelihood multiple processors write to the same line. Conversely, if the number of processors is large, the number of elements per processor decreases, leading again to few contiguous writes per processor, and thus more false sharing.
This comment was marked helpful 1 times.