


Question: Can you describe the difference between the MSI and MESI protocols?
Question: Messi or Ronaldo, who is better?
This comment was marked helpful 0 times.

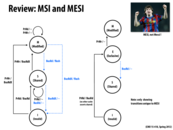
The difference between MSI and MESI is the extra state "exclusive" in the MESI protocol. The intuition behind making this change is that if a cache is the only one to contain a certain line, X, in the Shared state then it should not have to tell all other processors that it is about to write to X. To remove the need to issue this BusRdX, MESI adds another state, "exclusive." If a cache contains a line in the E state, then it is the only cache to contain that line. This means that if the processor wants to write to that line, no bus operations need to occur.
This comment was marked helpful 1 times.

So, at peak performance, Ronaldo will achieve a maximum of 15 goals in a single FIFA tournament, while Messi's maximum is only 11. However, after looking over total goals scored over years 2009-2011, it can be noted that Messi sees a more efficient increase in performance than Ronaldo, as well as the better performance at 2011. It may also be worth noting that Messi bottlenecks at 2010, while Ronaldo observes a consistent performance increase.
We can also consider the performance of the two players with maximum available resources: So far in the 2012-2013 year, Messi has averaged 1.53 goals/game, while Ronaldo averages only .83. We can also consider the rate of ball transfer (sending direction only). Messi achieves on average 58.1 BL/m (balls per match) with 85.9% utilisation, while Ronaldo sees only 33.1 BL/m and 77.6% util.
Finally, let's consider the overall monetary cost of either player: Messi requires 12.7 million Euro in the 2012/2013 year, while Ronaldo requires 12 million Euro.
While I admit this data inevitably presents a narrow portrait of the two players and performance can be measured in a variety of other ways, given the stats above, I see Messi as a more reliable choice in the average case; I also believe Messi to be the more cost-effective option, as a difference of .7 million euro (5.8%) is not enough to justify the dip in performance.
(sources: google, mostly. And yes, I do think I'm cute)
This comment was marked helpful 2 times.
@Amanda. I'm not sure what you mean by "bottlenecked", as Messi's Barcelona goal total has monotonically increased his entire career, with the exception of a one-goal step back from the 06/07 to 07/08 seasons. It's pretty clear this season that with David Villa out and Tito away for cancer treatment, Barcelona goes only as far as Messi takes them, so I'd consider Barcelona "Messi bound".
I could see a plausible argument that Ronaldo's performance is presently bottlenecked on the subpar play of his Real teammates or the recent lackluster coaching of Mourinho (as he flirts with a move to other clubs), but I don't see how it applies to Messi.
source: http://en.wikipedia.org/wiki/Lionel_Messi
This comment was marked helpful 2 times.

Speaking of Ronaldo and Messi, Real Madrid plays Barca this Tuesday at 15:00 (EST). Also, did you see Ronaldo's header against United two weeks ago? No way Messi can jump that high.
And, yes, Mourinho needs to stop being a grumpy old man.
This comment was marked helpful 0 times.

I cannot believe I missed a discussion about Messi vs. Cristiano. I could have gotten, like, 10 comments out of the way just on this.
For the record: Messi. Cristiano will be remembered as one of the best players of his generation, Messi will be remembered as a top 3-5 player of all time. It's not even a question.
By the way @kayvonf, Villa is back this year.
This comment was marked helpful 0 times.
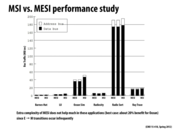

There just doesn't happen to be a lot of instances where a processor reads data that no other processor has and then decides to write to it. Maybe this means there is good data reuse.
This comment was marked helpful 0 times.
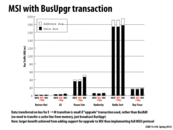
Question: How is the result shown on this slide a good example of workload-driven design? (Note: modern workloads must have different results than that shown above, as both modern Intel and AMD choose to implement extensions of the MESI coherence protocol.)
This comment was marked helpful 0 times.

Assumed that you are going to write chip strategy on how to handle share memory problem. MSI protocol comes to your head easily. You implement it and want it to be more efficient. Then you will propose all kinds of methods to improve it. But how can you decide on which version to be used as the final one?
Considering that analysis cannot help you much because of complicated hardware environment, workload-driven design is used widely. Some classical data sets, which are expected to run on it often, are generated and processed by different methods to test the performance. The method that has the best overall performance is selected to be your standard one.
From the above graph, MESI method and MSI+Upg method reach the same improvement on naive MSI way. To decide which one to use, more detailed tests may be used to compare between them. Depend on what you care more about, one will be chosen. But due to the similar performance, it will easily lead to different conclusions.
So workload-driven design sometimes leads designers to different conclusions.
This comment was marked helpful 0 times.
I'm a little bit confused about what the +Upg thing is.
From what I can tell, it's that a move from Shared to Modified need only send out a BusUpgr command and use what's in its cache as opposed to reading from main memory (which is what it does in standard MSI program?).
However, the slide says the "Data transferred on bus for E -> M transition is small if 'upgrade' transaction used." There is no E state in MSI, did you mean S -> M?
This comment was marked helpful 0 times.
@zwei: your understanding is correct on all accounts.
This comment was marked helpful 0 times.



Another reason that a larger line size might hurt is that if your program has poor locality increasing cache line size effectively makes your cache smaller by reducing the number of items that can be stored in your cache.
This comment was marked helpful 0 times.

Here is an example of how increasing line size can reduce the number of true sharing coherence misses when spatial locality is present:
Lets assume processors P1 and P2 share an array X[8]. Also, assume a cache line can store 4 elements of X. P1 writes to all elements of X[8] (spatial locality assumption). This leads P2 to invalidate 2 cache lines. Now when P2 wishes to read elements of X, there will be 2 "true sharing coherence misses".
If the cache line was double (could store 8 instances of X), then P2 would have just incurred one "true sharing coherence miss".
This comment was marked helpful 2 times.
Question: although "false sharing" was defined in the previous lecture, I don't recall seeing the terminology "true sharing". I presume this just means that the processors are writing to the same memory addresses (as opposed to false sharing where the processors write to different memory addresses)?
This comment was marked helpful 0 times.

@markwongsk Yeah, true sharing refers to when actual sharing of data is necessary. I believe we mentioned it in class.
This comment was marked helpful 0 times.

Would prefetching be considered an improvement to decrease the cache miss rate? I think this would fall under the compilers job, it still might be useful. Also, having too small of cache lines can lead to more misses. For instance, if you are iterating through an array of integers, and your cache line only has room for 2 contiguous integers. Each time you have an integer list larger than 2, you incur a cache miss on every third integer.
This comment was marked helpful 0 times.

Increasing the size of the entire cache would only decrease capacity misses, which would really only help Ocean Sim.
Cold misses decrease with cache line size because of spatial locality. Loading one value in the line gets you the rest of the line, which you don't have to load again.
Conflict misses decrease with cache line size for the same reason as cold misses; there's a smaller chance that we have to load another line.
True sharing decreases with cache line size since when lots of contiguous data must be written and read, it can fit in fewer cache lines.
False sharing increases with cache line size because there's a greater chance of artifactual communication.
This comment was marked helpful 3 times.
Increasing cache line size reduces true sharing because the same amount of data fits in fewer cache lines, and you take one miss per cache line.
This comment was marked helpful 0 times.

False sharing isn't really an issue with a program like Ocean Sim because almost all of the memory it needs will be in the same cache lines due to locality. Something like radix sort requires accessing memory from many different areas in memory but only need a few elements at a time, so it will bring in an entire cache line for one piece of data and result in false sharing.
This comment was marked helpful 0 times.
@Xelblade: A correction to your comment (which was otherwise great). The graph plots conflict + capacity misses in the same bar. Capacity misses will decrease with increasing cache line size when high spatial locality is present. Conflict misses however are increase with cache line size since the bigger lines will result in fewer sets and thus the potential for more conflicts. Overall (capacity+conflict) misses are going down here with increasing cache line size, presumably because of a combination of effects.
The true sharing and false sharing results on this graph are the really important ones in the context of this lecture.
This comment was marked helpful 0 times.
@bourne: False sharing can indeed by a problem in applications like Ocean, for the reason given in this slide. However this graph clearly shows that in this experiment, most of the coherence misses are true sharing and not false shading misses. This means that most of the data in cache lines that are communicated is in fact used by the application.
This comment was marked helpful 0 times.

A question about true sharing and increased cache line size: My understanding is that since shared data now fits on fewer cache lines, processors invalidate less cache lines due to true sharing. However, the cost of eviction is now higher because of increased cache line size. Overall, does this lead to a worse or better result?
This comment was marked helpful 0 times.

@kuity: I think per this later slide, it depends, but the latency is okay if you have a way to handle it like multi-threading.
This comment was marked helpful 0 times.


Parallel radix sort is prone to the false sharing problem because the edge of one processor's assigned block of data could be in the same cache line as the adjacent edge of another processor's assigned block of data. For example, the two red blocks will with high likelihood be in the same cache line because they are right next to each other (even though different processors are responsible for them), and this will cause a false sharing problem.
Increasing the array size decreases false sharing because a smaller portion of the data will be on shared cache lines. On the other hand, increasing the number of processors will divide the array further and will thus aggravate the false sharing problem.
This comment was marked helpful 0 times.
I'd like to clarify why false sharing occurs in this example. The figure illustrates how, in each round of the radix sort, each processor will compute the bin in the output array that its input array elements should be moved to (elements assigned to P2 are colored according to their bin). Given the mapping of elements to bins, the algorithm then computes the precise output location each element should be moved to. Each processor then scatters its elements to the appropriate location in the output array (as shown by the arrows in the figure).
By the nature of a stable radix sort, each process P writes its elements that belong to the same bin to a contiguous region of the output array. In this example, P2 never writes more than two consecutive elements to the output, since it is not assigned more than two elements mapping to the same bin. Noe remember that P0, P1, and P3 are also scattering their elements into the output. The result is an access pattern where each processor is scattering data all over memory.
Now recall that to perform a write, a processor must first obtain exclusive access to the cache line containing the address. In the case of radix sort above, many processors might end up writing to the same cache line (since it's likely all processors have elements falling in each bin). This will cause the cache line to bounce all around the machine. There is no inherent communication between the processors in the scatter step of the algorithm, so the extra cache invalidations during the scatter are due to false sharing.
Notice that if the array to sort is very large, each processor is responsible for more data, and it is more likely that each processor will write larger ranges of contiguous elements to the output array. This decreases false sharing by dropping the likelihood multiple processors write to the same line. Conversely, if the number of processors is large, the number of elements per processor decreases, leading again to few contiguous writes per processor, and thus more false sharing.
This comment was marked helpful 1 times.

Although we miss the cache less with larger cache lines, larger lines also result in more traffic since the cache must load more data per miss (and we don't use all the data in the line).
This comment was marked helpful 0 times.
There is an optimization for caching where the critical word is brought into a cache line first, then the rest of the data is loaded some time later. I wonder if there is a version of this where the bus traffic would happen to each processor a bit at a time, rather than in one large chunk.
This comment was marked helpful 0 times.


Decide the right cache line size in important but hard task. Different applications need different cache line sizes. I found this paper "What Every Programmer Should Know About Memory"(http://www.akkadia.org/drepper/cpumemory.pdf) pretty interesting and it talks about this in detail in section 3.
This comment was marked helpful 0 times.




There is only one processor in the SM state or M state for a given cache line. This one processor is the "owner" of the data, and is responsible for telling the other processors to update their local lines when it writes to the cache line. As the state diagram shows, a processor with the line in the SC state cannot write to its cache line. It then goes to the SM state processor with the line in the SM state goes to the SC state (so the "owner" is switched). If a processor is in the exclusive state or modified state, it doesn't have to worry about the other processors having that cache line.
This comment was marked helpful 0 times.

Let's take the situation where two processors have the same cache line in their caches, and after they both modify it once, one processor leaves the data alone (I call this processor "idle") while the other (I call this processor "active") continues to work on it. In an invalidation-based protocol, the "idle" processor would simply invalidate the line and not have to worry about it any more, but in an update protocol, there'd be a lot of traffic as the "active" processor must keep sending line updates to the "idle" processor, which in this case would be useless updates.
This comment was marked helpful 2 times.



As with many programming decisions, improving performance in one area results in a tradeoff in another. With invalidate vs update cache coherence protocols, the tradeoff of having lower miss rates is having higher traffic on the interconnect.
This comment was marked helpful 0 times.
Question: So is this an example of workload-driven design? We compare two designs and choose the one which perform better on the standard datasets.
This comment was marked helpful 0 times.



Question: If the processor accesses A many times (I'm assuming B is not accessed), shouldn't B be the one evicted by the L1 Cache in this example? (if the cache is using an LRU policy) But for the L2 Cache since A was the least recently used address (the L1 hits avoided the need for L2 checks), shouldn't A be evicted instead?
This comment was marked helpful 0 times.
@markwongsk: Yes. Good catch. Thanks.
This comment was marked helpful 0 times.
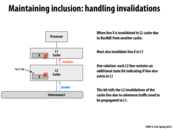
Question: Can someone describe a sequence of operations that could cause coherence to be violated if the L2 cache did not take special care to invalidate the appropriate line in the L1 upon receiving a BusRdX message over the interconnect?
This comment was marked helpful 0 times.

@kayvonf, here is a sequence which violate the coherence:
Proc 1: Store 0 -> X
Proc 0: Load X
Proc 1: Load X
Proc 0: Store 1 -> X
(proc 1 only invalid X cache line in L2 but not in L1)
Proc 1: Load X
(proc 1 will read X from L1 which is a wrong value)
This comment was marked helpful 0 times.


Not wanting to be a grammar/spelling nazi, but effect -> affect. (Hey if we care about ambiguous pronouns we shouldn't show partiality towards other language constructs :P).
This comment was marked helpful 0 times.
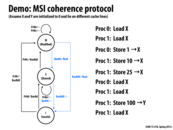
By following the given commands above, I would assume that X and Y would be as follows:
X = 1 (Proc 0)
X = 10 (Proc 1)
X = 25 (Proc 1)
Proc 0 loads X as 1
Proc 1 loads X as 25
Y = 100 (Proc 1)
Proc 1 loads X as 25
However, since X is a shared variable does the value of it change among processors?
This comment was marked helpful 0 times.
@mitraraman: Let me try and clear up your confusion. Here,
XandYrefer addresses. Both Proc 0 and Proc 1 perform loads and stores to these addresses. As discussed in the demo in class, the coherence protocol will result in the following behavior:(Assume the original values at address
Xand addressYare 0. Also, below I'll useXloosely to mean the line containingX. Ditto forY.)P0 load X:
P0 triggers BusRd for
XP0 loads
X(value=0) into S stateP0 receives data (value=0) from its cache
P1 load X:
P1 triggers BusRd for
XP1 loads
X(value=0) into S stateP1 receives data (value=0) from its cache
P0 store 1 to X:
P0 triggers BusRdX for
XP1 invalidates
XP0 loads
X(value=0) to M stateP0 writes 1 to
XP1 store 10 to X:
P1 triggers BusRdX for
XP0 flushes
X, memory now contains value 1 at addressXP0 invalidates
XP1 loads
X(value=1) into M stateP1 writes 10 to
XP1 store 25 to X:
P1 writes 25 to
XP0 load X:
P0 triggers BusRd for
XP1 flushes
X, memory now contains value 25 at addressXP1 transitions
Xto S stateP0 loads
X(value=25) into S stateP0 receives data (value=25) from its cache
P1 load X:
P1 receives data (value=25) from its cache
P1 store 100 to Y:
P1 triggers BusRdX for
YP1 loads
Y(value=0) into M stateP1 writes 100 to
YP0 load Y:
P0 triggers BusRd for
YP1 flushes
Y, memory now contains value 100 at addressYP1 transitions
Yto S stateP0 loads
Y(value=100) into S stateP0 receives data (value=100) from its cache
This comment was marked helpful 0 times.
When P1 loads X at the end, I am guessing P1 was at modified state because it just stored 100 to Y cache line. Then, how does P1 go back to Shared state (sharing X=25) from modified state, cache holding Y=100? Does it hear BusRdx somewhere to go to Invalid state and read X?
This comment was marked helpful 0 times.
@raphaelk: X and Y are assumed to be on different cache lines. (or you can just think of X and Y as cache lines, not addresses)
This comment was marked helpful 0 times.
I am confused regarding the last line of the slide:
Proc 1: Load X
but the explanation given by @kayvonf seems to indicate that the last instruction should be
Proc 0: Load Y
I'm pretty sure that the intended instruction should be Proc 0: Load Y as that makes more pedagogical sense. However, if the instruction was Proc 1: Load X, the following should be what would happen:
P1 load X: P1 receives data (value=25) from its cache
as P1 was already in the M state for the address X.
This comment was marked helpful 0 times.
@markwongsk I believe you are correct; it was noticed in class but the slide hasn't been corrected yet.
This comment was marked helpful 0 times.