

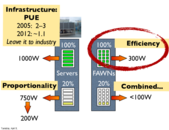


Notice that even while idle, the amount of power consumption is very large. It is extremely difficult to reduce the power of things like CPU, DRAM, and disk since they need to be ready to go when the user needs them again. We also need to make sure that memory does not drop any information while going idle.
This comment was marked helpful 0 times.


DVFS = Dynamic Voltage and Frequency Scaling
This comment was marked helpful 0 times.




Xeon7350 works at 2.93GHz and it has 4 cores. This is how the instructions/sec in millions reached beyond 10^6, which is un-realistic in single core CPU.
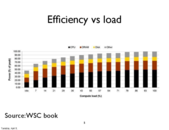
Question: what does the red line mean? There seems be some processors (dots in the graph) working at around 10^9 instructions/sec with relatively small instruction joule. But the line is high above these.
This comment was marked helpful 0 times.

I guess the red line is the upper bound of the instruction per J we can get for a given frequency.
This comment was marked helpful 0 times.

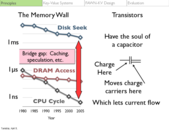
The reason why Ghz is not free (in terms of power) is that we have reached a limit with continued Dennard scaling, the idea that as transistors get smaller the power density stays the same.
Interestingly, many people are also of the opinion that parallelism is also not free - nowhere close to free. Because of limited parallelism, these people predict another so-called wall: dark silicon, where much of a multi-core chip is powered off (due to lack in parallelism, excessive heterogeneity, or even due to power limitations) at any given point, and the percent that is powered off increases with the increase in number of cores.
This comment was marked helpful 0 times.



most programs for parallel computing are written for a specific amount of processors. Because of this, many domain specific languages are invented so that when parallelism increases, code do not need to be re-written.
This comment was marked helpful 0 times.
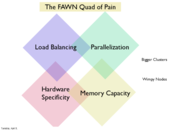

Unfortunately, the ideas we've discussed in previous lectures about the issues that arise with parallelisn are only amplified in the context of minimizing energy usage. In order to handle the same workload with wimpy nodes, you need a bigger cluster. Now, for example, there is a lower tolerance for error in the load balancing because a single node gets overwhelmed more easily. Any amount of communication between nodes becomes a more likely cause for a bottleneck. Since, in the context of a webserver, there's really no acceptable relaxation in the required latency, the software needs to be smarter.
This comment was marked helpful 0 times.




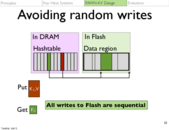

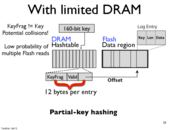
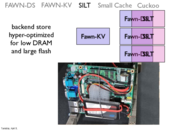
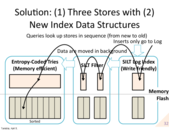
The reason you do not want random writes is because flash is terrible at this. Everything stored in a node is done so in a sequential log, to avoid these issues.
This comment was marked helpful 0 times.




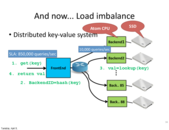
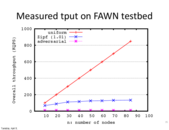
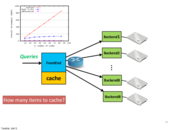
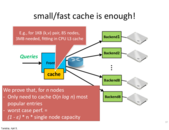
the worst case is almost a single node capacity since one can figure out the hashing function and always send query that will be hashed to the same node.
This comment was marked helpful 0 times.



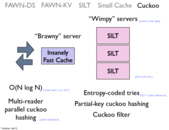

Google data center is located right next to a hydro power station to obtain the cheapest electricity possible. Google's energy bill can be estimated up to hundreds of million USD.
This comment was marked helpful 0 times.