The implementation can assign blocks of work to different cores. This means that resources do not need to be reallocated. In the example, this means that we don't need to allocate 8000 arrays of 130 floats. Instead, each core can allocate the space needed (in the space labeled Shared mem) and reuse it for each block that it runs.
This comment was marked helpful 0 times.
GG
The independence requirement allows thread blocks to be scheduled in any order across any number of cores, enabling the programs to be run on all kinds of GPUs without modification. And if you do require inter-block communication, which breaks the independence assumption, you have to make assumptions about the implementation of the GPU's block scheduler, as is discussed in the comments of slide 31.
This comment was marked helpful 1 times.
ajindia
Since the thread block execution can be carried out in any order and also possibly simultaneously using multiple cores, one must be careful when reading and writing from global memory. One would need to lock any global variable being accessed across thread blocks in order to avoid race conditions.
This comment was marked helpful 0 times.
kfc9001
@ajindia As I learned painfully from Assignment 2, locking in CUDA with a shared memory mutex/semaphore is hard. There is no cache coherency protocol in place, so every read and write needs to be done with an atomic instruction. Also, because all the threads in a warp execute in lockstep, you incur a lot of thrashing because different threads will all attempt to grab the lock at exactly the same time, leaving it completely arbitrary as to who gets the lock (no bounded waiting, etc). You're better off writing to a local array, and then in the host code accumulating all the results and writing to global memory in one transaction.
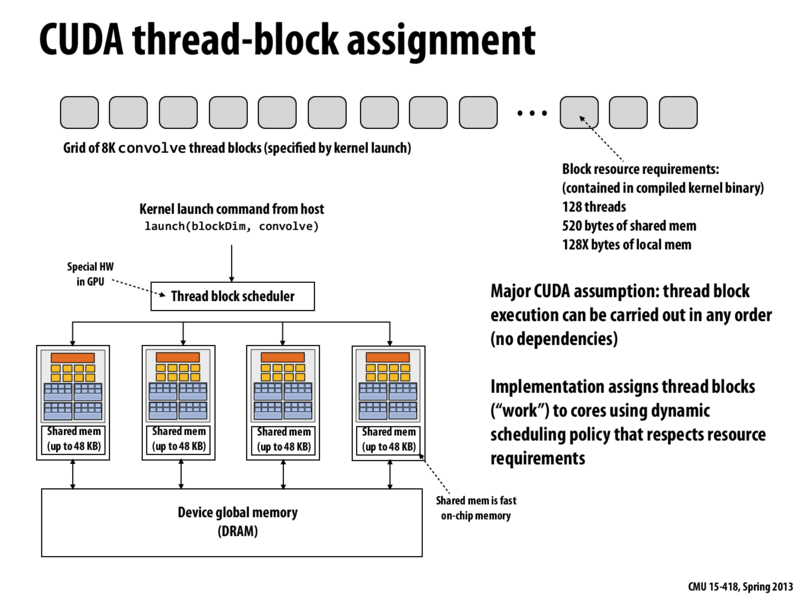
The implementation can assign blocks of work to different cores. This means that resources do not need to be reallocated. In the example, this means that we don't need to allocate 8000 arrays of 130 floats. Instead, each core can allocate the space needed (in the space labeled Shared mem) and reuse it for each block that it runs.
This comment was marked helpful 0 times.
The independence requirement allows thread blocks to be scheduled in any order across any number of cores, enabling the programs to be run on all kinds of GPUs without modification. And if you do require inter-block communication, which breaks the independence assumption, you have to make assumptions about the implementation of the GPU's block scheduler, as is discussed in the comments of slide 31.
This comment was marked helpful 1 times.
Since the thread block execution can be carried out in any order and also possibly simultaneously using multiple cores, one must be careful when reading and writing from global memory. One would need to lock any global variable being accessed across thread blocks in order to avoid race conditions.
This comment was marked helpful 0 times.
@ajindia As I learned painfully from Assignment 2, locking in CUDA with a shared memory mutex/semaphore is hard. There is no cache coherency protocol in place, so every read and write needs to be done with an atomic instruction. Also, because all the threads in a warp execute in lockstep, you incur a lot of thrashing because different threads will all attempt to grab the lock at exactly the same time, leaving it completely arbitrary as to who gets the lock (no bounded waiting, etc). You're better off writing to a local array, and then in the host code accumulating all the results and writing to global memory in one transaction.
This comment was marked helpful 0 times.