An example: Writing a CUDA program with a thread block count of 1024 is probably not a good choice in this case - as the thread count limits the number of blocks that can be scheduled on a core at once to 1 since 2*1024 > 1536.
This comment was marked helpful 0 times.
kayvonf
@aditm, you're thinking along the right lines. However, keep in mind there is nothing wrong running a single block of 1024 CUDA threads if 1024 CUDA threads (32 warps) provide sufficient parallelism for the core to hide stalls. More warps would provide more latency hiding, but it may not be necessary if the program has sufficient arithmetic intensity.
The end goal is to keep the execution units busy, it's not to maximize latency-hiding ability. It fact, it's preferable to execute with only the minimum number of threads needed to cover stalls. With fewer threads, you can use more resources per thread, e.g., more shared memory per thread, more L1 cache per thread, etc. In fact, there are situations where a lower thread count will yield better performance if the presence of more per-thread resources does more to prevent stalls than multi-threading does to hide them.
This comment was marked helpful 0 times.
martin
@aditm @kayvonf i think there is a mistake in the above comment. The number of blocks that can be scheduled on a core at once should be 12 not 1, because threadsPerBlock in this example is 128 hence 1536/128 = 12 blocks can at most be scheduled on the same core at once.
Another thing I would like to add is that since CUDA doesn't allow the programmer to assign work directly to hardware but via a special block scheduler, the programmer can basically create as many threads as they want and the hardware would assign the work properly.
This comment was marked helpful 0 times.
kayvonf
@martin: I believe @aditm was making up his own example of a CUDA program with a thread block size of 1024. He points out the since 1024 doesn't divide 1536 evenly, a CUDA program with 1024 threads in a thread block won't ever benefit from the maximum latency hiding of the chip. I pointed out that this is certainly true, but not necessarily bad, if 1024 threads (32 warps) is sufficient to hide memory stalls in the program.
As you correctly state, for the convolve example used in this lecture, the thread block size is 128, so 12 blocks can be scheduled onto one GTX 480 SM core. This is also pointed out in the slide.
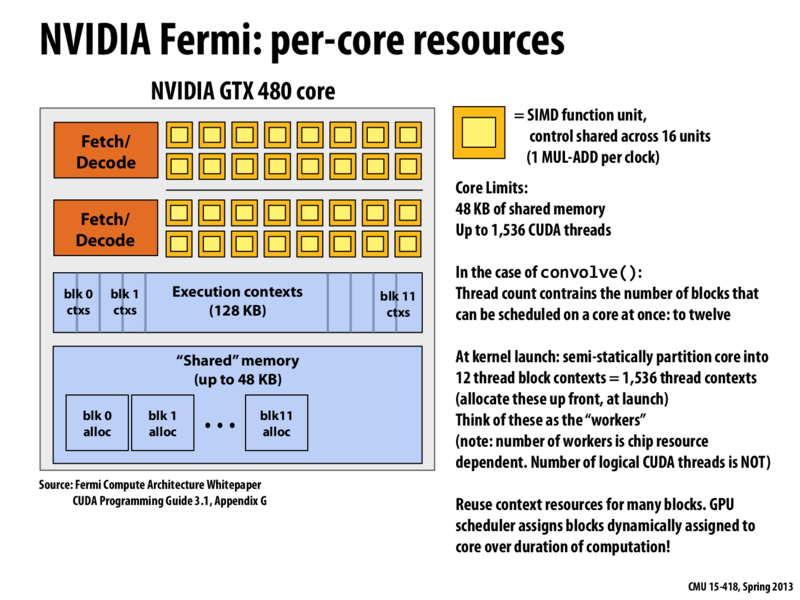
An example: Writing a CUDA program with a thread block count of 1024 is probably not a good choice in this case - as the thread count limits the number of blocks that can be scheduled on a core at once to 1 since 2*1024 > 1536.
This comment was marked helpful 0 times.
@aditm, you're thinking along the right lines. However, keep in mind there is nothing wrong running a single block of 1024 CUDA threads if 1024 CUDA threads (32 warps) provide sufficient parallelism for the core to hide stalls. More warps would provide more latency hiding, but it may not be necessary if the program has sufficient arithmetic intensity.
The end goal is to keep the execution units busy, it's not to maximize latency-hiding ability. It fact, it's preferable to execute with only the minimum number of threads needed to cover stalls. With fewer threads, you can use more resources per thread, e.g., more shared memory per thread, more L1 cache per thread, etc. In fact, there are situations where a lower thread count will yield better performance if the presence of more per-thread resources does more to prevent stalls than multi-threading does to hide them.
This comment was marked helpful 0 times.
@aditm @kayvonf i think there is a mistake in the above comment. The number of blocks that can be scheduled on a core at once should be 12 not 1, because threadsPerBlock in this example is 128 hence 1536/128 = 12 blocks can at most be scheduled on the same core at once.
Another thing I would like to add is that since CUDA doesn't allow the programmer to assign work directly to hardware but via a special block scheduler, the programmer can basically create as many threads as they want and the hardware would assign the work properly.
This comment was marked helpful 0 times.
@martin: I believe @aditm was making up his own example of a CUDA program with a thread block size of 1024. He points out the since 1024 doesn't divide 1536 evenly, a CUDA program with 1024 threads in a thread block won't ever benefit from the maximum latency hiding of the chip. I pointed out that this is certainly true, but not necessarily bad, if 1024 threads (32 warps) is sufficient to hide memory stalls in the program.
As you correctly state, for the
convolveexample used in this lecture, the thread block size is 128, so 12 blocks can be scheduled onto one GTX 480 SM core. This is also pointed out in the slide.This comment was marked helpful 0 times.