Warps are exposed in CUDA. The warpSize built-in variable contains the number of threads per warp. In addition, there are "warp vote functions" __all, __any and __ballot and "warp shuffle functions" __shfl, __shfl_up, __shfl_down and __shfl_xor.
This comment was marked helpful 1 times.
kayvonf
Very good point @sfackler. The concept of a warp was not exposed in the early versions of CUDA. However, as reasoning about warps (about the underlying implementation of a CUDA program) is often required for performance tuning (just as it was important in Assignment 1, Program 4), the warp size ended up hard-coded in many optimized CUDA programs. As a result, later versions of CUDA have exposed the warp size and also warp-granularity operations using the constructs you mentioned.
Exposing these hardware capabilities is also consistent with NVIDIA's goal of maintaining a low abstraction distance between CUDA programs and the underlying hardware implementation. In general, I'd say CUDA's design reflects the philosophy that allowing programmers to maximize performance takes precedence over code portability. Obviously maintaining both are desirable, but in design choices that trade one off for the other, NVIDIA seems to have taken the performance-centric view most of the time.
This comment was marked helpful 0 times.
danielk2
Question What happens when threads per block is less than 32? My guess is that it will run normally as if it had 32 threads (as if we don't use all the ALUs in ISPC). So if my guess is right, would it be more efficient to assign threads per block to be at least 32 if possible?
This comment was marked helpful 0 times.
kayvonf
@danielk2: Logically, the program runs as if it created N CUDA threads, where N is the number of threads per block specified. However, in the case you propose (N<32), your program's CUDA thread block would get mapped to one hardware warp. Certain threads of the warp would get masked off and the code would run at lower than peak efficiency. You can think of it as if the warp was divergent for the entire program.
This comment was marked helpful 0 times.
TeBoring
I have several questions:
1) If some threads in a warp are stalled, can core switch to do another warp?
2) If some warp hold on (eg:explicitly call function to wait for other threads in the block), can core do another warp?
3) If a block is not done, can core switch to another block?
4) if warp can be switched, does it mean the thread contexts (local variables) will be changed? if block can be switched, does it mean the block contexts (local variables) will be changed?
This comment was marked helpful 0 times.
kayvonf
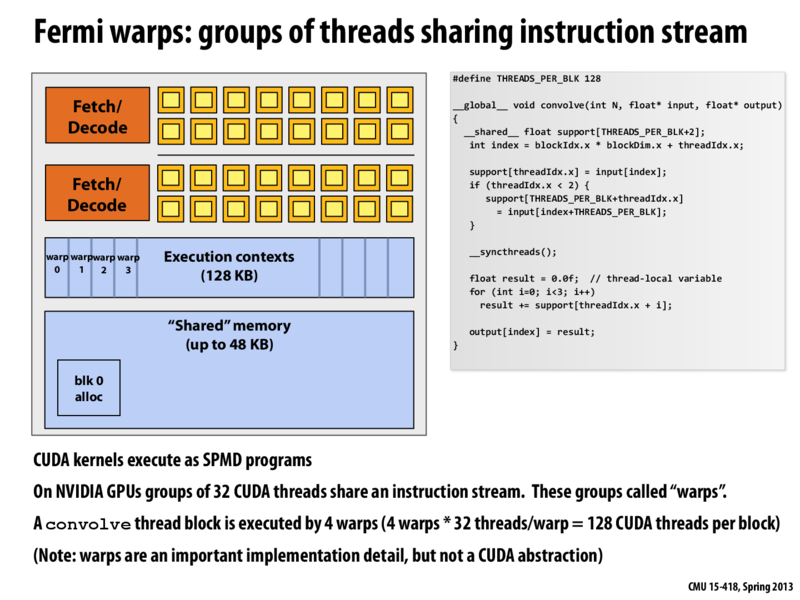
Here is a simple (and sufficiently accurate for the purposes of this class) way to think about how an NVIDIA GPU core (a.k.a. SM) runs CUDA threads: First, don't think about individual CUDA threads, just consider the scheduling of warps. Since the warp is the minimum granularity of scheduling, it does not help to think about scheduling the individual CUDA threads.
The GTX 480 SM (core) in this figure can maintain up to 48 warp execution contexts at once. These execution contents can be from different thread blocks if more than one thread block is assigned to the core at once.
At any point in time, each warp is either runnable or not. Warps that are NOT runnable may be in this state because they are waiting on memory, waiting on other warps to reach a __syncthreads point, etc.
Each clock, the scheduler chooses up to two runnable warps to execute, decodes the next instruction in the instruction stream for each of these warps, and then executes the instruction on the core's SIMD array of ALUs.
When a warp terminates, not much happens. However, when all the warps executing CUDA threads in a thread block have terminated (that is, the block is complete), all the execution contexts for the block become free, so the scheduler is able to assign a new thread block to the core. State for this new thread block will get mapped to the available warp execution contexts.
This comment was marked helpful 0 times.
apodolsk
@jpaulson @kayvonf:
There's another difference, which has to do with the fact that ISPC instances on x86 map to lanes in a single set of wide shared registers. That is, in order to carry out an instruction in an SIMD setting, you need to coalesce the input of all instances into a single (or a pair, etc.) shared SIMD register.
On the other hand, according to NVIDIA, all threads get their own register state.
(Section 3.1 in PTX manual. I searched a couple GTX whitepapers, but they only seem to give the size of the register file, and not its structure.)
Why is this? I can understand that you might want to do 32 operations in lock-step in order to cut down on instruction fetch costs and ALU requirements for data-parallel programs. But why keep per-thread state if you're still only executing one instruction at a time?
My idea is that it might have to do with the cost of coalescing into a register.
In HW1, I tried to improve saxpy by interleaving the X, Y, and OUTPUT arrays into a single array of struct{int x; int y; int out;}. The ispc compiler actually warned me (thanks, @mmp!) about implicit gather-scatter, and my program ran a lot slower than the original.
Apparently the issue was that, in order for an ISPC gang to operate on several elements of X in the original code, it was only necessary to perform a single read from memory directly to an SIMD register. But since my code's arr[0].x and arr[1].x, etc. were no longer contiguous in memory, coalescing this data into a register presumably involved extra reads, and maybe extra work in compiling them together. I never got around to checking the assembly, but Intel describes the same issue here:
I imagine that CUDA's design avoids this, since you can read from multiple banks simultaneously, and since you wouldn't need to coalesce into a single register. (But then, depending on the size of your struct, you might still wind up reading from ((int32_t\*)arr)[0] and ((int32_t\*)arr)[32] at the same time...)
I can't think of anything else, except the vague notion that you might be able to make divergent execution cheaper with such a scheme.
This comment was marked helpful 1 times.
kayvonf
@apodolsk: Absolutely excellent observations and question. I'll defer my answer to the weekend since a good answer is not trivial to explain. In the meantime you can Google SIMD vs. SIMT (or implicit SIMD) or try and think further about Lecture 2, slides 33 and 34.
This comment was marked helpful 0 times.
apodolsk
In the meantime, if anyone reads these posts and is wondering what's up: Alex R. talked to the NVIDIA lecturer about this. He said that warps' implementation can best be described as a set of shared registers, but that they reserve the right to switch to a registers-per-thread implementation and they want us to think about them as separate threads. I'm really curious to hear what's actually going on.
warp == ISPC gang
This comment was marked helpful 1 times.
Warps are exposed in CUDA. The
warpSizebuilt-in variable contains the number of threads per warp. In addition, there are "warp vote functions"__all,__anyand__ballotand "warp shuffle functions"__shfl,__shfl_up,__shfl_downand__shfl_xor.This comment was marked helpful 1 times.
Very good point @sfackler. The concept of a warp was not exposed in the early versions of CUDA. However, as reasoning about warps (about the underlying implementation of a CUDA program) is often required for performance tuning (just as it was important in Assignment 1, Program 4), the warp size ended up hard-coded in many optimized CUDA programs. As a result, later versions of CUDA have exposed the warp size and also warp-granularity operations using the constructs you mentioned.
Exposing these hardware capabilities is also consistent with NVIDIA's goal of maintaining a low abstraction distance between CUDA programs and the underlying hardware implementation. In general, I'd say CUDA's design reflects the philosophy that allowing programmers to maximize performance takes precedence over code portability. Obviously maintaining both are desirable, but in design choices that trade one off for the other, NVIDIA seems to have taken the performance-centric view most of the time.
This comment was marked helpful 0 times.
Question What happens when threads per block is less than 32? My guess is that it will run normally as if it had 32 threads (as if we don't use all the ALUs in ISPC). So if my guess is right, would it be more efficient to assign threads per block to be at least 32 if possible?
This comment was marked helpful 0 times.
@danielk2: Logically, the program runs as if it created N CUDA threads, where N is the number of threads per block specified. However, in the case you propose (N<32), your program's CUDA thread block would get mapped to one hardware warp. Certain threads of the warp would get masked off and the code would run at lower than peak efficiency. You can think of it as if the warp was divergent for the entire program.
This comment was marked helpful 0 times.
I have several questions:
1) If some threads in a warp are stalled, can core switch to do another warp?
2) If some warp hold on (eg:explicitly call function to wait for other threads in the block), can core do another warp?
3) If a block is not done, can core switch to another block?
4) if warp can be switched, does it mean the thread contexts (local variables) will be changed? if block can be switched, does it mean the block contexts (local variables) will be changed?
This comment was marked helpful 0 times.
Here is a simple (and sufficiently accurate for the purposes of this class) way to think about how an NVIDIA GPU core (a.k.a. SM) runs CUDA threads: First, don't think about individual CUDA threads, just consider the scheduling of warps. Since the warp is the minimum granularity of scheduling, it does not help to think about scheduling the individual CUDA threads.
The GTX 480 SM (core) in this figure can maintain up to 48 warp execution contexts at once. These execution contents can be from different thread blocks if more than one thread block is assigned to the core at once.
At any point in time, each warp is either runnable or not. Warps that are NOT runnable may be in this state because they are waiting on memory, waiting on other warps to reach a
__syncthreadspoint, etc.Each clock, the scheduler chooses up to two runnable warps to execute, decodes the next instruction in the instruction stream for each of these warps, and then executes the instruction on the core's SIMD array of ALUs.
When a warp terminates, not much happens. However, when all the warps executing CUDA threads in a thread block have terminated (that is, the block is complete), all the execution contexts for the block become free, so the scheduler is able to assign a new thread block to the core. State for this new thread block will get mapped to the available warp execution contexts.
This comment was marked helpful 0 times.
@jpaulson @kayvonf:
There's another difference, which has to do with the fact that ISPC instances on x86 map to lanes in a single set of wide shared registers. That is, in order to carry out an instruction in an SIMD setting, you need to coalesce the input of all instances into a single (or a pair, etc.) shared SIMD register.
On the other hand, according to NVIDIA, all threads get their own register state.
http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#simt-architecture
http://docs.nvidia.com/cuda/parallel-thread-execution/index.html
(Section 3.1 in PTX manual. I searched a couple GTX whitepapers, but they only seem to give the size of the register file, and not its structure.)
Why is this? I can understand that you might want to do 32 operations in lock-step in order to cut down on instruction fetch costs and ALU requirements for data-parallel programs. But why keep per-thread state if you're still only executing one instruction at a time?
My idea is that it might have to do with the cost of coalescing into a register.
In HW1, I tried to improve saxpy by interleaving the X, Y, and OUTPUT arrays into a single array of
struct{int x; int y; int out;}. The ispc compiler actually warned me (thanks, @mmp!) about implicit gather-scatter, and my program ran a lot slower than the original.Apparently the issue was that, in order for an ISPC gang to operate on several elements of X in the original code, it was only necessary to perform a single read from memory directly to an SIMD register. But since my code's
arr[0].xandarr[1].x, etc. were no longer contiguous in memory, coalescing this data into a register presumably involved extra reads, and maybe extra work in compiling them together. I never got around to checking the assembly, but Intel describes the same issue here:http://software.intel.com/sites/default/files/m/c/c/0/1/0/33940-OptimizingApps_Using_SIMD.pdf
I imagine that CUDA's design avoids this, since you can read from multiple banks simultaneously, and since you wouldn't need to coalesce into a single register. (But then, depending on the size of your struct, you might still wind up reading from
((int32_t\*)arr)[0]and((int32_t\*)arr)[32]at the same time...)I can't think of anything else, except the vague notion that you might be able to make divergent execution cheaper with such a scheme.
This comment was marked helpful 1 times.
@apodolsk: Absolutely excellent observations and question. I'll defer my answer to the weekend since a good answer is not trivial to explain. In the meantime you can Google SIMD vs. SIMT (or implicit SIMD) or try and think further about Lecture 2, slides 33 and 34.
This comment was marked helpful 0 times.
In the meantime, if anyone reads these posts and is wondering what's up: Alex R. talked to the NVIDIA lecturer about this. He said that warps' implementation can best be described as a set of shared registers, but that they reserve the right to switch to a registers-per-thread implementation and they want us to think about them as separate threads. I'm really curious to hear what's actually going on.
This comment was marked helpful 0 times.