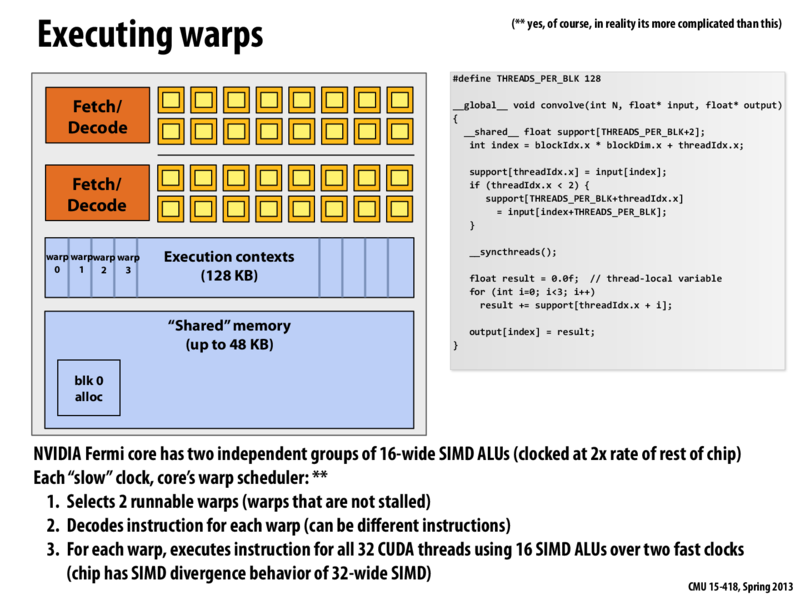
Question: The previous slide says each block has 4 warps, and each warp can execute different instructions. But why do we have only 2 Fetch/Decode units here?
This comment was marked helpful 0 times.
sfackler
@xiaowend: As the text at the bottom of the slide says, only up to 2 of the 4 warps can run at a same time. It's similar to Intel's Hyper-threading. At any time, there's a decently high probability that some of the warps are going to be blocked on memory so having a full set of 4 Fetch/Decode units and ALUs would be a waste.
This comment was marked helpful 0 times.
kayvonf
I'll also clarify that the previous slide refers to 4 warps because a CUDA thread block with 128 threads (which is what the CUDA program in this example specifies) will get mapped to four warps. The number 128 is specific to this example program! An NVIDIA GPU core can support interleaved execution of many warps at once. For example the GTX 680 can interleave up to 64 warps (2,048 total CUDA threads) on a single "SMX" core. See the details on slide 52 of this lecture. You can look up the details for other GPUs on NVIDIA's web site.
This comment was marked helpful 0 times.
martin
Basically at each clock, 2 runnable warps (in total of 64 threads) can be executed once on the core's SIMD array of ALUs. And the 2 warps can be working on two different instruction streams which is also the reason why there are two fetch/decode units
Question: The previous slide says each block has 4 warps, and each warp can execute different instructions. But why do we have only 2 Fetch/Decode units here?
This comment was marked helpful 0 times.
@xiaowend: As the text at the bottom of the slide says, only up to 2 of the 4 warps can run at a same time. It's similar to Intel's Hyper-threading. At any time, there's a decently high probability that some of the warps are going to be blocked on memory so having a full set of 4 Fetch/Decode units and ALUs would be a waste.
This comment was marked helpful 0 times.
I'll also clarify that the previous slide refers to 4 warps because a CUDA thread block with 128 threads (which is what the CUDA program in this example specifies) will get mapped to four warps. The number 128 is specific to this example program! An NVIDIA GPU core can support interleaved execution of many warps at once. For example the GTX 680 can interleave up to 64 warps (2,048 total CUDA threads) on a single "SMX" core. See the details on slide 52 of this lecture. You can look up the details for other GPUs on NVIDIA's web site.
This comment was marked helpful 0 times.
Basically at each clock, 2 runnable warps (in total of 64 threads) can be executed once on the core's SIMD array of ALUs. And the 2 warps can be working on two different instruction streams which is also the reason why there are two fetch/decode units
This comment was marked helpful 0 times.