The key idea from this slide is that even though each instruction always takes 4 cycles (in this example), we can still perform n instructions in roughly n cycles. Because we split up the instruction into multiple steps, just as we split laundry into the washing and drying steps, we can do different steps for different instructions at the same time. We cannot make the latency of the instruction lower than 4, so one instruction will always complete 4 clocks later. However, since we can perform one step of at most 4 instructions at the same time, if we supply new instructions once every cycle, we will complete an instruction once every cycle. This gives us a throughput of 1 instruction per cycle.
Compare this to latency hiding from previous lectures, where we could context switch among threads so that we could work on one thread while waiting for a memory retrieve for another thread.
This comment was marked helpful 1 times.
tliao
Pipelining has been a great way for speeding up the execution speed of a program but it's up to the programmer to fully utilize it. Using a lot of conditionals in one's code can hurt the pipeline because it can force the processor to branch to some location in memory and flush out what's currently in the pipeline (unless the branch predictor correctly guessed which branch the program will take) which then has start fresh at the next instruction. Assuming that there's 4 cycles per instruction, each branch effectively adds 3 extra cycles for each missed branch.
This comment was marked helpful 0 times.
unihorn
Instruction pipeline is a great technology, but it is hard to be utilized fully when design CPU. The ideal situation for this graph seems to be 4x speedup, but several reasons make it difficult to realize. First, if the pipeline is stopped, it needs some extra cycles to recover, as tliao said. Second, because of all stages should be finished in a cycle, the length of a cycle equals to the time used by the slowest stage, which drags the progress of other stages down. For efficiency, long stage may need to be split. Last, dependency may exist between two instructions, which leads to complicate synchronization methods.
This comment was marked helpful 0 times.
kayvonf
Question: Let's say the "execute" phase of the above pipeline took significantly longer than the other pipeline stages. What might you consider to speed up the pipeline's execution?
This comment was marked helpful 0 times.
pebbled
@kayvon If any one portion of the pipeline takes a disproportionately large amount of time, we could add more of the relevant units to break up this work. For this example, we could add a second execution unit and have the decoder alternate feeding one EU and then the other.
This comment was marked helpful 0 times.
kailuo
Shouldn't a good instruction pipeline be designed so that it can never be the case that one stage is significantly longer than the other pipeline stages? Suppose a stage A is longer than any other stages in a pipeline, then once A's buffer is full, execution of other stages will pause for A's buffer to be available again. So why not put some of the execution units of those fast stages into the slow stage to balance the execution time instead of wasting them knowing that they will pause every once in a while?
This comment was marked helpful 0 times.
ToBeContinued
^ Balance the load between different stages of a pipeline is indeed a good design heuristic. However, there are certain things you just can not avoid. Usually the most time consuming stage in a pipeline involves memory access, which can be >100X compared to operations such as decoding etc.
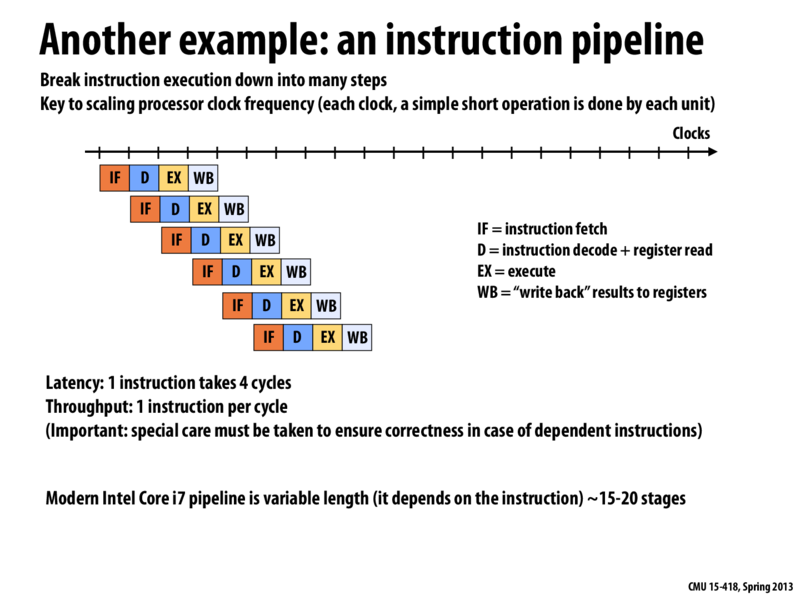
The key idea from this slide is that even though each instruction always takes 4 cycles (in this example), we can still perform n instructions in roughly n cycles. Because we split up the instruction into multiple steps, just as we split laundry into the washing and drying steps, we can do different steps for different instructions at the same time. We cannot make the latency of the instruction lower than 4, so one instruction will always complete 4 clocks later. However, since we can perform one step of at most 4 instructions at the same time, if we supply new instructions once every cycle, we will complete an instruction once every cycle. This gives us a throughput of 1 instruction per cycle.
Compare this to latency hiding from previous lectures, where we could context switch among threads so that we could work on one thread while waiting for a memory retrieve for another thread.
This comment was marked helpful 1 times.
Pipelining has been a great way for speeding up the execution speed of a program but it's up to the programmer to fully utilize it. Using a lot of conditionals in one's code can hurt the pipeline because it can force the processor to branch to some location in memory and flush out what's currently in the pipeline (unless the branch predictor correctly guessed which branch the program will take) which then has start fresh at the next instruction. Assuming that there's 4 cycles per instruction, each branch effectively adds 3 extra cycles for each missed branch.
This comment was marked helpful 0 times.
Instruction pipeline is a great technology, but it is hard to be utilized fully when design CPU. The ideal situation for this graph seems to be 4x speedup, but several reasons make it difficult to realize. First, if the pipeline is stopped, it needs some extra cycles to recover, as tliao said. Second, because of all stages should be finished in a cycle, the length of a cycle equals to the time used by the slowest stage, which drags the progress of other stages down. For efficiency, long stage may need to be split. Last, dependency may exist between two instructions, which leads to complicate synchronization methods.
This comment was marked helpful 0 times.
Question: Let's say the "execute" phase of the above pipeline took significantly longer than the other pipeline stages. What might you consider to speed up the pipeline's execution?
This comment was marked helpful 0 times.
@kayvon If any one portion of the pipeline takes a disproportionately large amount of time, we could add more of the relevant units to break up this work. For this example, we could add a second execution unit and have the decoder alternate feeding one EU and then the other.
This comment was marked helpful 0 times.
Shouldn't a good instruction pipeline be designed so that it can never be the case that one stage is significantly longer than the other pipeline stages? Suppose a stage A is longer than any other stages in a pipeline, then once A's buffer is full, execution of other stages will pause for A's buffer to be available again. So why not put some of the execution units of those fast stages into the slow stage to balance the execution time instead of wasting them knowing that they will pause every once in a while?
This comment was marked helpful 0 times.
^ Balance the load between different stages of a pipeline is indeed a good design heuristic. However, there are certain things you just can not avoid. Usually the most time consuming stage in a pipeline involves memory access, which can be >100X compared to operations such as decoding etc.
This comment was marked helpful 0 times.