Since computing the new value of an element at (i,j) requires you to first do the calculation for (i-1,j) and (i,j-1) each element on each round has a dependency on the elements that are above it and/or the left of it. However, this means that all elements on a given diagonal (the blue lines) are independent of each other and can be done in parallel. This gives some parallelization, but overall is not the most effective technique, because you still have to do each diagonal in order, which is still a lot of sequential code.
This comment was marked helpful 0 times.
smcqueen
An interesting note about this algorithm is that the amount of parallelism changes as the computation progresses. Initially, there is very little parallelism, which then increases until we reach halfway through the grid, at which point it once again begins to decrease. As mentioned above, this means that it is not the most effective technique, since we are not always fully taking advantage of all the possible parallelization.
This comment was marked helpful 0 times.
jpaulson
Note that you can run many iterations at once, as long as they are separated by at least one diagonal. So in fact the parallelization you can get here is very good (basically as good as the red-black coloring suggested a few slides later; you can do work on about half the elements at a time).
To elaborate: the last diagonal can compute iteration 1 at the same time the third-to-last diagonal computes iteration 2 at the same time the fifth-to-last diagonal computes iteration 3...
This comment was marked helpful 0 times.
briandecost
@jpaulson -- that's actually a really cool idea, to set your program up to run iterations in waves, but it's probably not the best design choice for this geometry. It's certainly takes advantage of more parallelism, but it doesn't really address the drawbacks of the diagonal method -- nontrivial to code, not much parallelism early on (and at the end) for two reasons now, and you still have lots of synchronization.
This comment was marked helpful 0 times.
bourne
@briandecost If you had a small difference required to stop (difference between one iteration and the next) you could probably just stop in the middle of several iterations- leaving each diagonal on a different iteration. While this would not be the same as the sequential if the error is small enough running the end iterations to completion would result in only a negligible change.
This comment was marked helpful 0 times.
kuity
Note that this algorithm runs in O($n$) time and the previous algorithm runs in O($n^2$) time. That means that if both algorithms were optimized, as $n$ increases, the running time for the first algorithm increases exponentially.
This comment was marked helpful 0 times.
jpaulson
@kuity: Huh? Are you assuming you actually have $n$ cores to run on?
This comment was marked helpful 0 times.
kuity
@jpaulson Oh yeah, I was indeed assuming that. I was more thinking about it in terms of the span of the algorithm rather than the actual specs of the machine, though (so assuming no hardware limitations).
This comment was marked helpful 0 times.
pd43
Wouldn't jpaulson's method of parallelism across iterations theoretically be one of the best ways to parallelize this algorithm? It allows there to be n processors doing useful work at all times. The only drawback I see is the need for synchronization after every calculation, every iteration needs to move to the next calculation at the same time.
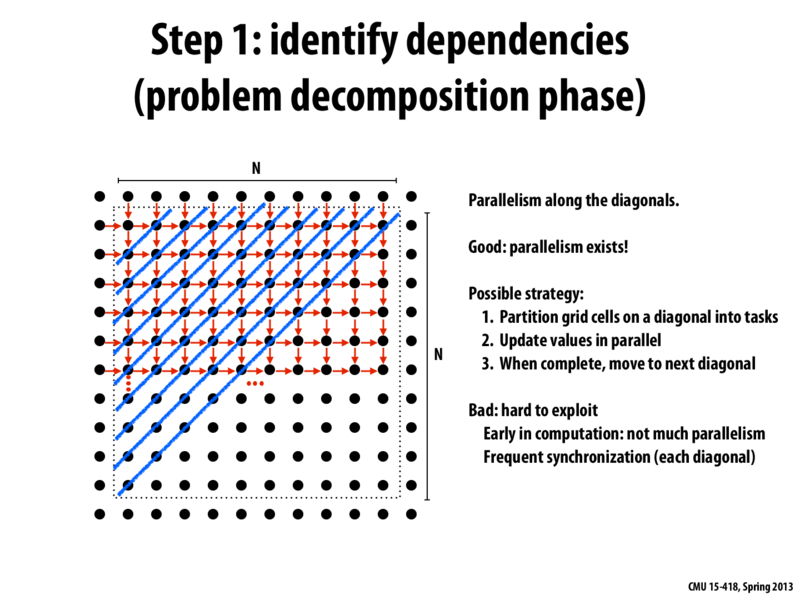
Since computing the new value of an element at (i,j) requires you to first do the calculation for (i-1,j) and (i,j-1) each element on each round has a dependency on the elements that are above it and/or the left of it. However, this means that all elements on a given diagonal (the blue lines) are independent of each other and can be done in parallel. This gives some parallelization, but overall is not the most effective technique, because you still have to do each diagonal in order, which is still a lot of sequential code.
This comment was marked helpful 0 times.
An interesting note about this algorithm is that the amount of parallelism changes as the computation progresses. Initially, there is very little parallelism, which then increases until we reach halfway through the grid, at which point it once again begins to decrease. As mentioned above, this means that it is not the most effective technique, since we are not always fully taking advantage of all the possible parallelization.
This comment was marked helpful 0 times.
Note that you can run many iterations at once, as long as they are separated by at least one diagonal. So in fact the parallelization you can get here is very good (basically as good as the red-black coloring suggested a few slides later; you can do work on about half the elements at a time).
To elaborate: the last diagonal can compute iteration 1 at the same time the third-to-last diagonal computes iteration 2 at the same time the fifth-to-last diagonal computes iteration 3...
This comment was marked helpful 0 times.
@jpaulson -- that's actually a really cool idea, to set your program up to run iterations in waves, but it's probably not the best design choice for this geometry. It's certainly takes advantage of more parallelism, but it doesn't really address the drawbacks of the diagonal method -- nontrivial to code, not much parallelism early on (and at the end) for two reasons now, and you still have lots of synchronization.
This comment was marked helpful 0 times.
@briandecost If you had a small difference required to stop (difference between one iteration and the next) you could probably just stop in the middle of several iterations- leaving each diagonal on a different iteration. While this would not be the same as the sequential if the error is small enough running the end iterations to completion would result in only a negligible change.
This comment was marked helpful 0 times.
Note that this algorithm runs in O($n$) time and the previous algorithm runs in O($n^2$) time. That means that if both algorithms were optimized, as $n$ increases, the running time for the first algorithm increases exponentially.
This comment was marked helpful 0 times.
@kuity: Huh? Are you assuming you actually have $n$ cores to run on?
This comment was marked helpful 0 times.
@jpaulson Oh yeah, I was indeed assuming that. I was more thinking about it in terms of the span of the algorithm rather than the actual specs of the machine, though (so assuming no hardware limitations).
This comment was marked helpful 0 times.
Wouldn't jpaulson's method of parallelism across iterations theoretically be one of the best ways to parallelize this algorithm? It allows there to be n processors doing useful work at all times. The only drawback I see is the need for synchronization after every calculation, every iteration needs to move to the next calculation at the same time.
This comment was marked helpful 0 times.