





Busy-waiting is bad because you are wasting processor cycles checking on the true condition when you can instead sleep a thread to be woken up for instance. It's better to be notified once when the condition changes rather than repeatedly checking.
This comment was marked helpful 0 times.

In a single-core system, busy-waiting is especially bad because you know you won't get out of the loop; someone else needs the core to change X to true!
This comment was marked helpful 0 times.

@jpaulson That's not necessarily true on a single-core system. If a process has a signal handler that modifies a flag whose value it keeps checking or the process reading from memory mapped I/O for the condition, you can break out of the spin loop.
This comment was marked helpful 0 times.

Busy waiting is bad because the process wastes resources that another process could use.
This comment was marked helpful 0 times.

Note, in some situations, the spin loop may not affect performance, but will have an effect in power consumption.
This comment was marked helpful 0 times.

busy waiting might also increase the bus load and slow down other processors since it tries to read from memory each iteration.
This comment was marked helpful 0 times.

^ actually busy waiting won't increase bus load, because all of the processors spinning would be in the S state anyway, until there was a write.
This comment was marked helpful 0 times.


Blocking is better than busy waiting where execution resources are scarce. In blocking, execution resources are not held up (compared to spinning) and other threads are permitted to execute.
This comment was marked helpful 0 times.


In terms of performance, if no other party in the system needs any resources, it may be better to be busy-waiting instead of blocking because right when the lock frees, the thread can immediately continue, whereas if we used a mutex , we would have to wait for the system to put and schedule the thread back on the processor.
This comment was marked helpful 0 times.

For example, in our homework assignments (for the most part), we have planned our programs around using the entirety of the computing resources. If necessary, design decisions would not have been based on keeping resources free for anyone else. While we're not told how OpenMP implements the critical section, for our WSP program, busy waiting would have been acceptable.
This comment was marked helpful 0 times.



If two threads try to access a critical section using lock, the race condition can cause both threads to enter the critical section at the same time. For example, if thread 1 performs the ld instruction and then thread 2 performs the ld instruction immediately after, both threads will have R0 as 0 and so they will both go ahead into the critical section.
This comment was marked helpful 4 times.

If we make the operation "if 0, store 1" an atomic operation. This can be correct.
This comment was marked helpful 0 times.

@xiaowend: I think we need to make all the three operations ("load word into R0", "if 0" and "store 1") into one atomic operation to make the implementation correct.
The example is the same as @Arnie had mentioned: if p1 load the word into R0, then p2 load the word into R0, even the later "if 0, store 1" operation is atomic, p1 and p2 will both enter the critical section.
This comment was marked helpful 0 times.

Remember: a data race occurs when two or more threads try to access the same memory location without the proper locking mechanisms, and at least one is attempting to write to that location. The set "data races" is a subset of "race conditions." A race condition occurs when multiple actors accessing some arbitrary shared resource aren't properly synchronized (resulting in different possible outputs of your program).
This comment was marked helpful 0 times.

Test-and-set allows you to load the address and set the address to a different value in one instruction. This way we can load the lock value and simultaneously set it to one. This will prevent someone else from thinking they can also grab the lock, since the lock value will be 1 as soon as we grab it.
This comment was marked helpful 0 times.

Test-and-set is one kind of the basis for the synchronization.
As an instruction, it can support the atomicity of the conditional operations on some variable. Because it ensures the consecutive happen of LOAD-TEST-STORE, it can master the value of an variable.
Based on the master of specified variable, lock can be implemented to manage some memory. Furthermore, lock is the basis for advanced synchronization strategy, such as read-write lock.
This comment was marked helpful 0 times.

In the lecture, somebody asked what we are testing here and professor did not quite answer the question. I did some search but still remain uncertain. My guess is that the term come from the X86 "test" instruction, which sets the zero flag based on the argument. Apparently here we are also setting the zero flag of the processor.
This comment was marked helpful 0 times.

@ToBeContinued: as I understand it, you're testing the lock flag variable in this manner: read the lock flag (mem[addr]) and write 1 to mem[addr] atomically. Then you test the lock flag which was read before you wrote that 1 -- if it was zero, you've got the lock. If it was 1, some other thread has the lock, and the 1 your test-and-set wrote had no effect.
This comment was marked helpful 0 times.


Processor 1 issues test-and-set. This triggers an exclusive access transaction on the bus to obtain exclusive access to this cache line. Processor 1 then sets the lock, and all other processors have invalidated their cache line.
All other processors are continually requesting exclusive access. This takes the cache line from Processor 1.
Problems: -Releasing lock requires a cache invalidation -False sharing: The cache line in the critical section unrelated to the lock is likely on the same cache line as the lock -Highly loaded bus
This comment was marked helpful 0 times.

Question: If all the other processors keep taking cache line away from Processor 1 before it can do anything, is it a livelock?
This comment was marked helpful 1 times.
slide 29 of snooping implementation mentioned that a write can finish before lose cache line, I think this is the answer.
This comment was marked helpful 0 times.

@TeBoring: you are correct. This aspect of a coherence implementation is important to prevent livelock.
This comment was marked helpful 0 times.
Would test-and-set be bad if the logic proceeded to deschedule the waiting process which was unable to obtain the lock?
This comment was marked helpful 0 times.
@markwongsk. The situation you state isn't much of a problem. The thread holding the lock is not affected if a waiting thread is descheduled. Note that it is a much bigger problem if the thread holding the lock is descheduled. This thread is not making progress (until it gets rescheduled) and the other threads are waiting for it to release the lock. Even worse, the threads spinning for the lock hog the processor, potentially preventing the lock-holding thread from being rescheduled. This is an example of priority inversion.
On a modern parallel system, the potential performance problems causes by swapping out a thread (or process) at an inopportune time (e.g., when it's holding an important lock) are the primary motivation for lock-free solutions that are discussed in the fine-grained synchronization lecture in the course.
This comment was marked helpful 0 times.

In test&set; lock, every processor is trying to write to a "shared" lock variable. Since it is test and "set", based on cache-coherence protocol every processing node will send a Read-Exclusive bus transaction for the "shared" lock variable, which invalidates everyone else cache line.
This comment was marked helpful 0 times.

Question: Why does time ever go down in this case? Wouldn't the amount of time needed to transfer the T&S lock only ever go up with an increased number of processors?
This comment was marked helpful 0 times.

@placebo: I think one possible answer is that the interconnect topology is different for different number of processors
This comment was marked helpful 0 times.


I remember a situation where an unfair lock made my program run faster:
I was trying to measure the performance of a FIFO-locked resource allocator by making lots of small allocations. The results were awful because each thread would get the lock, finish a tiny fraction of its work, and then attempt to take the lock again. But since the lock was FIFO, that thread had go to the back of the queue of threads waiting on the lock. It would also have to context switch to the thread at the head of the queue. Since context switch time was greater than the length of the tight critical section, the CPU wound up spending most of its time context switching (note that a nonblocking fair lock on a multicore system would have been even worse in this particular case).
I thought about changing that function so that it could batch requests while holding a lock, but I think it wasn't practical because there was a lot of non-critical work to do between requests (writing zeros). Instead, I just switched to an unfair test-and-set lock. That let me approximate batching because threads that won the lock could continue to retake the lock until they got context switched out. They'd also get an unfair extra scheduler slot of they got context switched out while inside the critical section, but I found that no thread ever actually failed to win the lock more than a handful of times. I wound up with much better latency and throughput, and a lot less congestion on the lock.
This comment was marked helpful 0 times.
The reason test and set is high traffic and poor scaling is because processor has to constantly issue a memory read and a memory write operation atomically.
This comment was marked helpful 0 times.

volatile means not to store the volatile variable in a register (common compiler optimization), and instead actually access it every time. This wouldn't work without volatile.
This comment was marked helpful 0 times.
In general, this "double-checked locking" approach is dubious, although it's a good idea here: http://www.cs.umd.edu/~pugh/java/memoryModel/DoubleCheckedLocking.html
This comment was marked helpful 0 times.
Reason for volatile:
The compiler may optimize out the recurring read of the lock by storing the value of a lock in a register. We want to prevent this, so we make the lock a volatile variable.
Unfortunately volatile doesn't meet this spec for many compilers.
This comment was marked helpful 0 times.

Compilers correctly implement the C specification with respect to volatile. Volatile was not intended to and does not correctly support this kind of operation.
From here:
There appear to be three classes of volatile use that are actually portable. Though such uses appear relatively rare, they would be slowed down on some platforms if we adopted stronger semantics. These are:
volatile may be used to mark local variables in the same scope as a setjmp whose value should be preserved across a longjmp. It is unclear what fraction of such uses would be slowed down, since the atomicity and ordering constraints have no effect if there is no way to share the local variable in question. (It is even unclear what fraction of such uses would be slowed down by requiring all variables to be preserved across a longjmp, but that is a separate matter and is not considered here.)
volatile may be used when variables may be "externally modified", but the modification in fact is triggered synchronously by the thread itself, e.g. because the underlying memory is mapped at multiple locations.
A volatile sigatomic_t may be used to communicate with a signal handler in the same thread, in a restricted manner. One could consider weakening the requirements for the sigatomic_t case, but that seems rather counterintuitive.
Volatile works (mostly) to perform synchronization of memory between processors on x86 because x86's memory model is extremely strong.
Unfortunately, C historically had no concept of a memory model, so there was no platform independent way of correctly synchronizing state. C11 adds a memory model and the stdatomic.h header which provides such functionality.
This comment was marked helpful 1 times.
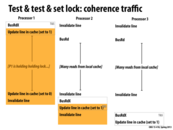

This example has much less bus traffic than the one on slide 11. Consider the time period when Processor 1 has the lock. As long as Processor 1 has the lock, nothing is being written to lock, so the values in Processor 2 and 3's caches are valid. Since Processor 2 and 3 are spinning in the while(lock != 0) loop, they are only sending read requests (not RdX). Since they only want to read the value and they have a valid value in their cache, they do not need to acquire the bus, reducing the bus traffic in this example.
This comment was marked helpful 2 times.

Here test & test & set has less bus traffic because it repeatedly test if another processor has the lock before doing test & set. Therefore we don't need to use BusRdX since we don't modify the value of the lock. Therefore there might be less bus traffic.
This comment was marked helpful 0 times.


The gains in bus traffic reduction shown on the previous slide might not outweigh the cons of this new scheme if the lock is never held for very long by any processor. This is because once the lock is released there is a surge of traffic on the bus.
This comment was marked helpful 0 times.
As a result, we can potentially use exponential backoff to prevent excessive traffic on bus when locks are released; however, we might be unfair to some processors here (since the most recent processor will try to acquire the lock more frequently).
This comment was marked helpful 0 times.


There a couple of reasons at why this code has bad effects. 1) Some threads might not ever get to run. By the time one thread is ready to check if the lock is ready, another thread might have gotten it by then. Now that thread is penalized by double the amount of time and there is even more of a chance that another thread might get the lock while the same thread is waiting in the delay. (Note that this same scenario could have happened with the ideas discussed earlier in the lecture) 2) A lock might become available but threads might be stuck in the delay loop and will be unable to acquire the lock. The threads stuck in the while loop are wasting valuable time in the delay when they could have acquired the lock already.
This comment was marked helpful 1 times.
This works good when processors may hold the lock for a long period. In this case, there would be less traffic.
This comment was marked helpful 0 times.
This can result in severe unfairness because processors that have been waiting a long time have to wait even longer between each successive test. This means that a processor that has been waiting a long time has infrequent tests, which means it will probably have to be waiting quite a bit longer. A processor with a new request has frequent tests, so it has a higher chance of getting into the critical section during the period when the lock isn't held by anyone.
This comment was marked helpful 0 times.

I remember this as how many online services do auto-reconnect. (The easiest example is googletalk.) Whenever you lose connection, googletalk constantly pings the server to see if it can reconnect, if not, it waits a while and pings again. These waits increase exponentially the longer the connection is lost. Luckily, (unlike a lock) more than one person (or thread) can be connected to google talk (or acquire the lock). However, in the case of locks, exponential wait-times can be very unfair as another thread can acquire the lock as soon as it unlocks, leaving the waiting lock waiting even longer.
This comment was marked helpful 0 times.


A processor trying to acquire the lock modifies the l->next_ticket variable. But no other processor is reading this variable and hence its invalidation does not affect other processors. On a lock release, l->now_serving is written to and this causes each processor waiting for the lock to invalidate the cache line. This will result in a read request by each of these processors. However, in an efficient implementation of cache, the result of the first memory read for l->now_serving can be snooped by all other processors.
This comment was marked helpful 0 times.

A comparison of the ticket lock with test-and-set:
Latency: Higher
Traffic: Less (only reads while waiting for lock)
Scalability: Higher
Storage: Low
Fairness: More fair because of ticket "number" ensures lock will be acquired in chronological sequence.
This comment was marked helpful 1 times.
The best thing about this lock I think is not just cache coherent performance, but that this guarantees fairness. The spinlock will be FIFO, so the oldest waiter will get to run first. You can do this all with just one int and not a queue!
This comment was marked helpful 0 times.

I think there are certain details missing here. Does the following sound correct?
When the lock is created, the l->status array should be initialized such that l->head = 0, l->status[0] = 0 and all other elements are 1.
During unlock, we should also set l->status[my_element] = 1, because my_element is a circular increment. If we do not set l->status[my_element] to 1, then after the first round of circular increment, all the elements in l->status will be 0.
This comment was marked helpful 2 times.
@Mayank: thanks. I'll add the detail to the slides.
This comment was marked helpful 0 times.

I'm not sure how this could be better than a ticket lock implementation. In high contention areas, you would assume in a ticket lock that cache values would be updated as long as more contention for the lock was coming in. Since threads will need to wait no matter what, there can be cache coherency done in the background to hide these this latency. This, and the fact you need to allocate some room for an array seems like a waste when ticket locks work so simply.
This comment was marked helpful 0 times.

Load value from memory, increment it locally, use compare and swap on (address, old value, incremented value), compare to original value, and if they're the same then we're good.
If someone else accessed after we loaded the value before, then the values won't be the same so we won't swap (increment).
This comment was marked helpful 0 times.
atomicIncrement(int* x) {
while(true) {
int n = *x;
if(CAS(x, n, n+1) == n) break;
}
}
This comment was marked helpful 0 times.
Atomic addition is so common that many architectures provide specialized instructions for it. For example, x86 provides xadd, which when combined with the lock prefix, performs addition atomically.
This comment was marked helpful 0 times.

int atomicIncrement (int* addr) {
int old = *addr;
int assumed;
do {
assumed = old;
old = atomicCAS(addr, assumed, assumed+1);
} while (old != assumed)
return old;
}
This comment was marked helpful 0 times.


The code sequence on the right causes deadlock:
Suppose all threads have passed through the atomic region. One thread then sets b->counter = 0 and b->flag = 1. This thread moves on to the next Barrier, takes the lock, and sets b->flag = 0. Then the other threads still in the barrier will become stuck in their while loop, and will never reach the second barrier.
This comment was marked helpful 1 times.

It avoids the deadlock problem in the last slide by clear flag after all thread leave.
This comment was marked helpful 0 times.

This solves the deadlock by having "while (b->leave_counter != P);". This works as the first arriving thread to the next barrier can only wait and switch the flag only when all the threads have left the previous block. This solves the problem of the implementation a slide ago which had some slow threads stuck behind the last barrier but cannot make progress because of the faster threads switching the flag before the slower threads have left the last barrier.
This comment was marked helpful 0 times.

This works since it introduces the concept of "odd/even" barriers, and since two consecutive barriers cannot be even (local_sense == 0) and odd (local_sense == 1), we won't have the issue from the previous slide.
This comment was marked helpful 1 times.
This wouldn't work if it were somehow possible for threads to be in three barriers at once. But that is impossible because it takes every thread to exit a barrier.
This comment was marked helpful 0 times.
I was thinking of a slightly different way to implement this. Instead of requiring a per-processor variable, my thought was to add a third state to the flag. It effectively does the same thing (assuming I didn't make a mistake), but I thought I would share since it was my first thought for how to fix the original buggy version.
// barrier for p processors
void Barrier(Bar_t* b, int p) {
while (b->flag == 2); // wait until everyone leaves the last barrier
lock(b->lock);
if (b->counter == 0) {
b->flag = 0; // first arriver clears flag
}
int arrived = ++(b->counter);
unlock(b->lock);
if (arrived == p) { // last arriver sets flag
b->counter--;
b->flag = 2;
}
else {
while (b->flag == 0); // wait for flag
lock(b->lock);
int remaining = --(b->counter);
if (remaining == 0)
b->flag = 1;
unlock(b->lock);
}
}
This comment was marked helpful 0 times.
I also thought of a different way to implement this, but my goal was to remove the locks. I think I succeeded in removing them with calls to atomicCAS
void Barrier(Bar_t *b, int p) {
local_sense = (local_sense == 0) ? 1 : 0;
bool changed = false;
int guess = b->counter;
// Keep trying to change the counter until success
while (!changed) {
int actual = atomicCAS(&b->counter, guess, guess + 1);
if (guess == actual) {
changed = true;
}
else {
guess = actual;
}
}
if (guess + 1 == p) {
b->counter = 0;
b->flag = local_sense;
}
else {
while (b->flag != local_sense); // wait for flag
}
}
This comment was marked helpful 0 times.

What happens when I call
barrier(b,p)
- sets local_sense of p processors to 1,
- sets flag to 1,
and right away
barrier(b,1)
- sets local_sense of p processors to 0,
- sets flag to 0,
Is there a chance that some processors in first barrier call have not yet stopped spinning and the second barrier finishes using only 1 processor, setting flag to 0 therefore deadlock for processors from first barrier? Or am I missing something?
This comment was marked helpful 0 times.
@raphaelk: I think barriers are always for a "group of processes". The usage you suggest might not be a correct use of an instance of a barrier. This can lead to deadlock
As per my guess, if you do want a second barrier only for a subset of processes (different "p"), then you should define a different barrier variable "b2" and call barrier(b2,1).
Example code: (Assume 8 processes)
//Common code
barrier(b,8) //All processes should reach this barrier
if(pid % 2 == 0) {
//Code specific to even pids
barrier(b_even,4) //Barrier for even pids
//more code specific to even pids
} else {
//Code specific to odd pids
barrier(b_odd,4) //Barrier for odd pids
//more code specific to odd pids
}
barrier(b,8)
This comment was marked helpful 0 times.

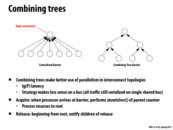

By combining calls into a tree structure, we allow each sub tree to run in parallel reducing the contention we normally see on a single parent node (left hand picture). This is still a safe barrier since the root of the tree is the only node that will notify the children of a lock release.
This comment was marked helpful 0 times.

Comparing traffic and space to the previous slide, this takes $O(P)$ space and, where $P=2^k$, $2\sum_{i=0}^{k-1} 2^i = 2P-2$ traffic (including the release).
Note that in the picture above, on the right, there are double the amount of arrows we actually need (because for each parent, one of the children should be electrically equivalent to the parent). Then, we must account for the release.
This comment was marked helpful 0 times.


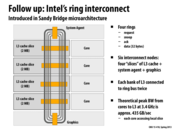
I asked this in lecture but I just was curious again: if Intel scales up this arrangement to 8 cores, would it be worth the silicon to have two buses that go in opposite directions? (e.g. one set of buses to communicate clockwise, and another set to go counterclockwise)
This comment was marked helpful 0 times.