




This is what we had implemented in ProxyLab in 15-213. Here the value of N depends upon the workload you expect to see: How frequently do you get requests and what is the expected latency of these requests. If a continuous unbounded stream of requests is expected, N should be such that the request queue doesn't grow very fast so as to avoid running out of memory.
This comment was marked helpful 0 times.
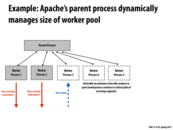
Here we maintain few idle workers to avoid the overhead of creation of new threads when requests come in. Since thread creation takes time, it occupies the "critical path" of servicing requests, meaning the server cannot receive and service requests while this is happening.
This comment was marked helpful 0 times.
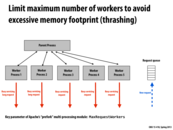

In a DDOS (distributed denial of service) attack, with a large number of spam requests, the request queue is completely filled up so any actual requests must wait through the entire queue before being serviced.
This comment was marked helpful 0 times.

when request queue is full, incoming requests will be denied.
This comment was marked helpful 0 times.


How does Apache's worker module account for the protection arguments given above? Specifically, if the server is using non-thread safe libraries or there is a crash in one thread/worker, what are its protocols?
This comment was marked helpful 0 times.
If each thread does not write to shared object but write to database instead, I think one thread crash would not affect other threads.
This comment was marked helpful 0 times.

The default response to a fault in one thread of a process is to kill the entire process. If the threads share any state at all, it's a huge mess to try to kill one thread without leaving the process as a whole in some weird state. If threads aren't sharing any state, then you may as well set up separate processes for them.
This comment was marked helpful 0 times.
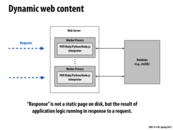


Originally, Javascript was only run in browsers. This means that servers would just send the source code to clients and all the computation is executed in clients' browsers.
As Javascript became so popular, people developed framework to run Javascript in server side. One of the most popular framework is Node.js.
This comment was marked helpful 1 times.
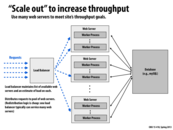
What is the biggest advantage in using multiple web servers as opposed to using many worker processes? Why would it be better to have 5 web servers with 10 worker processes than having 50 worker processes on one web server. Is it just to avoid waiting while the web server figures out what to do with the request(like start a new process, put in queue etc.)? or is there something more?
This comment was marked helpful 0 times.

@ajindia The throughput on a single machine is restricted to the resources on that machine. If there's too many computationally intensive tasks running on the web server or too many memory intensive tasks, then there will be a noticeable change in the latency of response.
This comment was marked helpful 0 times.

Amazon's EC2 actually offers this exact architecture by allowing you to create your own server load balancer, and forwarding each incoming request to your servers in sequential order (round-robin). Amazon also offers another tool called CloudWatch that allows you to define alarms for determining when to scale in or scale out your pool of machines (they are automatically booted up or terminated according to your scale in/out policies). Of course, this is all very similar to what we did in Assignment 4.
This comment was marked helpful 3 times.

The term "scale out" is commonly used in contrast to "scale up." Scaling up is the traditional way of replacing a computing element with a more larger, better, more powerful one, whereas scaling out involves using many computing elements, as in the slide about using many web servers.
In terms of database paradigms, in significant part because of cost efficiency, scaling up is more closely associated with SQL and ACID, whereas scaling out is more closely associated with NoSQL and BASE (Basically Available, Soft State, Eventually Consistent), though there are many exceptions - some applications of database technology, such as for banks, may require ACID.
This comment was marked helpful 0 times.
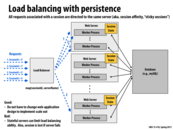
How exactly would you define a session in this case? Also, isn't the point of the load balancer slightly lost? Instead of distributing the work according to the load on each server, it is now just mapping the work to the appropriate server. As it states in one of the bad implications of this approach, this could lead to limited load balance ability or none at all. There is a "workload balance" problem, where certain servers could have multiple requests and others could be idle, which counteracts the use of the load balancer.
This comment was marked helpful 0 times.

@mitraraman An example may be the namespace in a distributed file system. The load balance is not the entire picture. For example, AFS in a simple way partition users folders into different blocks, usr1,usr2...usr11,usr12...(not sure how many). Here, each of our andrew id is mapped to each of the different server, but the load balance may not be the same at all time or may not be able to adjust to the best server dynamically.
This comment was marked helpful 0 times.

@mitraman: Even if the load balancer has to direct requests associated with the same session to the same machine, it retains flexibility to make assignment decisions for new incoming sessions. Also, on the next slide we discussed an alternative setup where the session was stored in a persistent store, like a database, resulting in the worker nodes being completely stateless.
This comment was marked helpful 0 times.
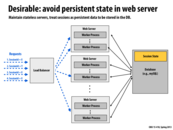
In terms of reliability, this is a much better scheme than the previous one where each worker had to maintain state. Now, if a worker were to go down for any reason, the load balancer can easily have assign another worker to the user without having to create a new session. This does produce some problems though since the database is now the point of contention.
This comment was marked helpful 1 times.
Some trade off will always be required. The stateless design does not come without a cost. If you desire reliability and robustness, then be ready to sacrifice some performance.
This comment was marked helpful 0 times.

Database here is used to persistent session information and makes server stateless, which makes load balancer a lot easier to do their work. From the point of recovery if server crashes, stateless server also results in faster recovery phase. To reduce the contention of database, I think each server can hold session information as lease for a certain time instead of contacting DB constantly.
This comment was marked helpful 0 times.
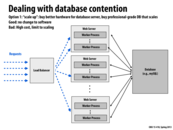

One way of dealing with database contention is simply to add more databases. A simple solution to consistency issues that arise would be on a write, you simply write to all database. On a read, you can choose any database and read from it.
This comment was marked helpful 0 times.

On large database, it is also possible to apply logging & commit mechanisms, so that multiple writes are committed to database as one single block. The idea is that disk writes are fast for large chunk of contiguous sector, but slow for small chunks of sparse sectors.
This comment was marked helpful 0 times.
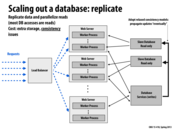

There are many details in realizing replicas, when considering efficiency. Consistency is maintained in the whole system to ensure the same eventual result at least. Different levels of consistency should be compared carefully. Fault tolerance is another important point. Either the fault of master database or that of slave one should be recovered. High availability means that using the same hardware, it can provide as much service as possible.
When the idea of parallelism combines with network implementation, many new problems come out.
This comment was marked helpful 0 times.

Another name for "scale up" and "scale out" is vertical scaling and horizontal scaling. A detailed explanation is in wiki.
This comment was marked helpful 0 times.

Is consistency between the master and slave databases a bottleneck of any sort? I assume that since there is mostly static content on a webpage, then keeping databases consistent is not difficult and can be done without much interruption to site availability.
This comment was marked helpful 0 times.
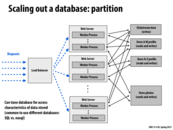
Some negatives to the partition model:
Requests that involve accessing multiple databases would be a lot worse since you have to hit multiple databases to service the request instead of just one.
Also, it's difficult to distribute data among the databases equally.
This comment was marked helpful 0 times.
There is a common solution for the data distribution problem and that is to use consistent hashing to map data to servers. For example, instead of mapping a certain range of names to a server, which is unbalanced since names aren't equally distributed across all people, the servers can hash the data and instead map the hash to servers.
This comment was marked helpful 0 times.
But using consistent hashing might reduce locality and increase response time since getting data from a nearby server is faster than getting data from servers far away.
This comment was marked helpful 0 times.
Solution to sharding also involves hash-by-content, where the hash value of the stored object is based on the the content of the object but not just things like username or title. This is especially common in P2P.
This comment was marked helpful 0 times.

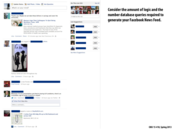
This slide is showing how you can divide a request for a page into multiple database queries, such as a query for the ads, a query for search requests, a query for recommendations, etc.
This comment was marked helpful 0 times.

*This is good for parallelism because each database query can be done in parallel. This will decrease the time for a response since the database queries are not reliant upon each other. This method can greatly decrease latency.
This comment was marked helpful 0 times.

Here's a quick summary of the linked article:
Latency on websites matters far more than most think. Marissa Mayer (back when she was at Google) reported that users unanimously want 30 results per page, but 10 results /page did way better in A/B testing. This was because the 10 results page takes .4 seconds to generate, whereas the 30 results page takes .9.
This finding is corroborated with data from AOL, Shopzilla, and additional Google data.
Interestingly, the bulk of the web page latency on popular sites like Facebook and Ebay was actually front-end time rather than server latency.
I suspect that this is because these sites have already implemented the methods described in this slide, and not because these methods are not important.
Here is a clickable link to the article: http://perspectives.mvdirona.com/2009/10/31/TheCostOfLatency.aspx
This comment was marked helpful 1 times.



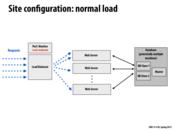
This shows that we have fluctuating demand for servers. As in Amazon or HuffingtonPost, the demand for servers can be regular, but some other sites can have irregular burst of demand for server capability. This suggests the need for efficient elastic web servers which can handle not only regular demands but also sudden and unexpected burst as well.
This comment was marked helpful 0 times.

Could someone explain the Y axis of the Amazon.com graph? I understand the trend that the graph is trying to convey, but what does Daily Pageviews (percent) measure? Just curious at this point..
This comment was marked helpful 0 times.

@dyc I believe it's the percentage of global page views across the entire web according to alexa.com
This comment was marked helpful 0 times.


There are many papers that deal with interesting ways to deal with elasticity beyond turning servers on and off when needed, such as Blink (http://none.cs.umass.edu/papers/pdf/asplos2011.pdf) and Powernap (http://web.eecs.umich.edu/~twenisch/papers/asplos09.pdf), which 'smartly' use power state S3 (sleeping) to minimize power usage when load is low and can quickly become available when needed.
Some techniques used are to have all servers maintain a percentage of time that they are on (staggered so there is never a time they are all sleeping) and have a master modify their sleeping percentage based on workload.
Other power saving policies have whole clusters of nodes sleep at once and have data intelligently striped and replicated across clusters so if any piece of data is on a sleeping cluster it can be retrieved in a timely manner from an awake one and if needed that whole cluster can be waken up.
This comment was marked helpful 0 times.



Question: So what happens during the holiday shopping season when Amazon needs their servers back? Do you, as an EC2 customer, get less compute power around those times?
This comment was marked helpful 0 times.
@nslobody
Following the law of supply and demand, the computing power and server time simply become more expensive during these times. Anyway Amazon is making money.
This comment was marked helpful 0 times.
For anyone concerned that their EC2 instance will suddenly jump in price, this only applies to Spot Instances, not On-Demand Instances.
Spot-Instances follow a bidding model and are a bit unreliable in the sense that once the hourly price goes above your bid, your instance is automatically shutdown.
Better not use only Spot Instances for Dropbox.
This comment was marked helpful 0 times.

In Amazon EC2, user can define their own monitoring metric for load balancer.
This comment was marked helpful 0 times.
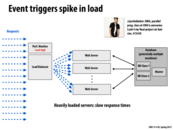
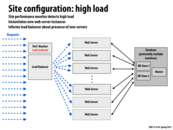
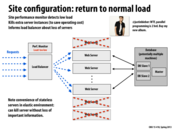
One should also make sure that starting a new web server and killing a new web server doesn't happen at at the same threshold. In this case, if the number of requests varies around this threshold, we will end up repeatedly starting and killing we servers for every small change in load. This could end up being very expensive.
This comment was marked helpful 0 times.


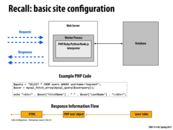


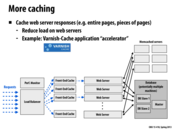
Doing a database query every time someone hits the page will take far too long, and has too much overhead to scale well. To help alleviate this issue, you can introduce a cache between the web server and the database which can store a large amount of recently used data. One popular cache implementation is memcached which is discussed on the next slide.
This comment was marked helpful 0 times.
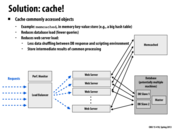

I was originally going to ask why it was better to use Memcached vs APC (which is faster) but I did a search, and Memcached is best for distributed systems across multiple web servers, whereas APC is better used for reading/writing on one server.
This comment was marked helpful 0 times.
What if there are more web servers accessing the cache than the database itself. Wouldn't this cause the same problem? Could it be better to have a cache for each server?
This comment was marked helpful 0 times.

Cache is far more faster than communicating with database, since dealing with the queries in the database cost more time. Therefore even though more web servers accessing the cache than the database, it will stil save time. If each server has its own cache, it may cost more time when dealing with concurrency and consistency if we modify the database. We can also add some Front-end Cache to cache some web server response.
This comment was marked helpful 0 times.

@ajindia: i imagine contention for the cache would incur a smaller performance hit than contention for the database, because a cache lookup ought to be significantly cheaper than a database lookup. On slide 34 there is an example which uses a set of front-end caches in addition to memcached, which is similar to your suggestion.
You probably wouldn't want to trade the shared cache for front-end or server-specific caches though, because the front-end caches might end up holding replicated data, effectively reducing how much information you can fit in the cache system.
This comment was marked helpful 0 times.
An alternative is to add more caches as shown in slide 32. This could be done either by replication or by partitioning of the data in cache, in the same manner as these links show the replication and partitioning of data across multiple databases.
This comment was marked helpful 0 times.

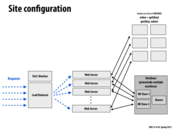
Here the graph shows that multiple servers are used as memcached servers. This is to avoid the cache becoming another bottleneck.
This comment was marked helpful 0 times.

Question: What is the definition of "unacceptable" latency here? It seems like different people have different definitions...
This comment was marked helpful 0 times.
"28TB of cached data in 800 memcached servers" results in 35GB main memory per server. Although servers with large RAM is in market, is this configuration practical?
I searched for a while and found this post. The main reason is cost. When taking account of the cost of operation (energy, cooling, rack space, etc), the dedicated memcached servers that have much more RAM cost only one third of combining typical servers to achieve the same amount of RAM.
This comment was marked helpful 1 times.
An interesting aside from lecture: the cheapest data centers are up in the Pacific Northwest because of the availability of hydroelectric power, and some big data centers are situated right on rivers. This is something to think about if you are located in the middle of the country and you must decide between greater latency of having your data center on a coast and greater cost of having it local.
This comment was marked helpful 0 times.
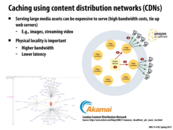

The edge servers will have a copy of some read-only data from the origin server. The origin server will redirect the user to an edge server based on their IP address.
An additional benefit of using edge servers is that there is reduced cost from having to send data from the origin server over a large distance. However, there is cost for paying companies like Amazon or Akamai for use of their edge servers.
This comment was marked helpful 0 times.

As the slide says, CDN nodes are usually deployed in multiple locations, often over multiple backbones. Benefits include reducing bandwidth costs, improving page load times, or increasing global availability of content. The number of nodes and servers making up a CDN varies, depending on the architecture.
This comment was marked helpful 0 times.
Another reason that CDN becomes important today is that the web server providers like Amazon tends to consolidate their resource in several large data centers to reduce management cost. So the latency is influenced a lot by the data center locations. Thus CDN nodes are needed to make contents closer to users.
This comment was marked helpful 0 times.

No company wants to tie up their servers delivering huge assets. Instead, they employ CDNs around the world to deliver these huge assets for them. This is possible since these assets (pictures, video) generally never change. When a user wants to download such content, it is delivered to them by a nearby CDN (based on their IP address). The geographic locality lets the content be delivered with higher bandwidth and lower latency. Furthermore, the cost to the company is lower, since they just have to pay the CDN to deliver the image for them, instead of having to pay for sending the data itself over and over and over again all over the world.
This comment was marked helpful 0 times.

The example shows that images are served from the CDN whereas other web page content (such as html text) is served by the origin server(s). The reason is that image requests require greater bandwidth and are more likely to be create a bottleneck.
This comment was marked helpful 0 times.
Another reason that a CDN is applicable is that images tend to be read only, or at least change infrequently --say compared to messages on your News Feed. Therefore, they can be replicated and pushed out to CDNs close to users around the globe without worries about consistency issues.
The CDN is a data cache, so it is only useful if the same data is accessed multiple times. If content is always changing, then it's likely not data a site will push out to a CDN.
This comment was marked helpful 3 times.
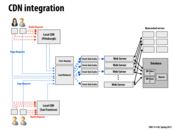
This slide shows how everything is put together. When a request is made, the page requests go to the Load Balancer and the media requests go to the local CDN (here we have a different one for Pittsburgh and San Francisco). If the CDN doesn't have the media requested, it forwards the requests to the Load Balancer as well. the load balancer then assigns requests to different servers. A request going to server X first queries the front end cache to see if the data requested is cached. If so, the cache data is returned and the request is complete. If not, server X processes the request, accessing the DB or memchache as needed.
This comment was marked helpful 0 times.


Question (mostly for @kayvonf): Since language speed was mentioned a couple of times in this lecture, if you were starting a Facebook-scale site today, what language and/or framework would you write it in? Would a scripting language be the way to go? Does it matter? (Assume maybe that you could find or train as many programmers as you needed in your language of choice.)
This comment was marked helpful 2 times.
Is scaling a website about throughput or latency? It's both!
Latency: People don't want to wait for a webpage to load. Studies have shown that increasing the response time of a website decreases usage significantly.
Throughput: The throughput of a website needs to be high enough to sustain all incoming requests. Think about how many requests are sent to Facebook every second. If throughput isn't high enough to handle incoming requests, you will have to drop requests, or buffer them.
This comment was marked helpful 0 times.
Kayvon gives an example of how Google increased search results from 10 per page to 30 per page; however, this lead to increased latency resulting in lower website usage. Throughput, in this context, refers to the number of incoming requests that can be handled per second (or other unit of time); websites could drop requests if they do not have sufficiently high throughput compared to the number of incoming requests. Both lower latency and high throughput are essential to ensure site performance.
This comment was marked helpful 0 times.