I don't quite get it: as we are marching to the multiple multiple cores era, and modern CPUs have integrated GPU as well, do we really need all those 8 ALUs in a core? I wonder how many of them will be utilized by end user? For games, image processing and maths, just use opencl/cuma and GPU is much better at these tasks. For CPU, SIMD increases programming complexity, and forces software engineers to learn more details about hardware. Isn't that a bad abstraction? I think a better solution would be, no SIMD, just more cores. Thus programmers have a better programming model: threads. Huge amount of floats to process? Get GPU to work.
kayvonf
@sherry: But aren't these same concepts exactly how GPU's work as well? See slide 35 and slide 37?
arjunh
@Sherry The problem is there is a certain overhead to creating a thread; it requires trapping the kernel (which has a non-trivial overhead) and maintaining a considerable amount of extra state just to perform a small operation. Also, cores require more resources (such as fetch/decode units). In the end, you'd have to make each of the cores rather weak in order to support more of them and as a result, programs that require high-compute capabilities/powerful cores would suffer.
You're right that the existence of SIMD requires programmers to think more about the actual hardware, but that's unavoidable when you're trying to optimize for performance. An analogous case would be the numerous guidelines programmers must heed when managing memory (using locality to their advantage, understanding how to allocate/free/dereference memory safely, etc). The abstraction of having an unbounded array of bytes where each access is equal in terms of cost just doesn't work in the real world.
Kayvon explains the fundamental difference between threads and SIMD very well in lecture 2 (at around 37:00).
kayvonf
@arjunh: I want to stress that SIMD execution AND HW multi-threaded execution are techniques used by BOTH modern CPUs and modern GPUs in order to maximize the efficiency of these processors for more throughput oriented workloads. Having a set of ALUs share the resources for decoding an instruction stream is a far more efficient architecture for parallel workloads that demonstrate highly coherent execution.
Sherry
@arjunh @kayvonf You are right. It IS more efficient. CPU or GPU, SIMD shall be on one of them anyway.
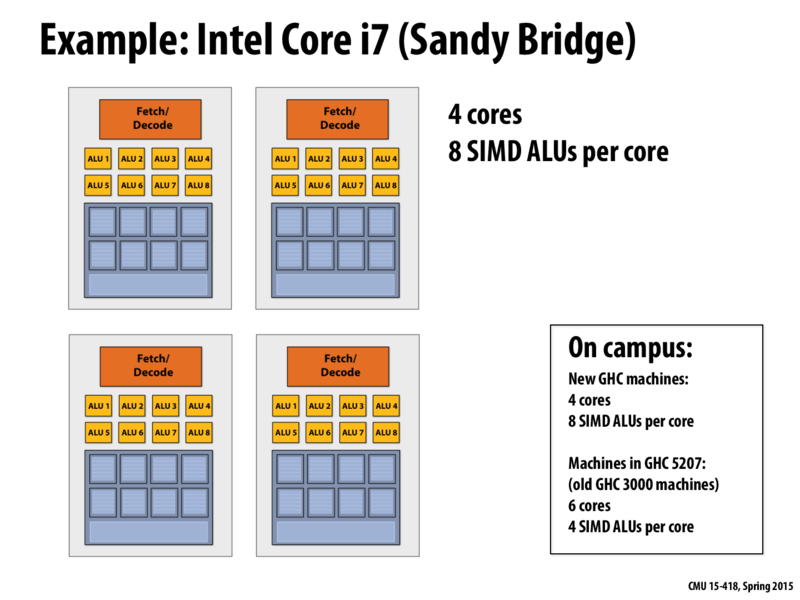
I don't quite get it: as we are marching to the multiple multiple cores era, and modern CPUs have integrated GPU as well, do we really need all those 8 ALUs in a core? I wonder how many of them will be utilized by end user? For games, image processing and maths, just use opencl/cuma and GPU is much better at these tasks. For CPU, SIMD increases programming complexity, and forces software engineers to learn more details about hardware. Isn't that a bad abstraction? I think a better solution would be, no SIMD, just more cores. Thus programmers have a better programming model: threads. Huge amount of floats to process? Get GPU to work.
@sherry: But aren't these same concepts exactly how GPU's work as well? See slide 35 and slide 37?
@Sherry The problem is there is a certain overhead to creating a thread; it requires trapping the kernel (which has a non-trivial overhead) and maintaining a considerable amount of extra state just to perform a small operation. Also, cores require more resources (such as fetch/decode units). In the end, you'd have to make each of the cores rather weak in order to support more of them and as a result, programs that require high-compute capabilities/powerful cores would suffer.
You're right that the existence of SIMD requires programmers to think more about the actual hardware, but that's unavoidable when you're trying to optimize for performance. An analogous case would be the numerous guidelines programmers must heed when managing memory (using locality to their advantage, understanding how to allocate/free/dereference memory safely, etc). The abstraction of having an unbounded array of bytes where each access is equal in terms of cost just doesn't work in the real world.
Kayvon explains the fundamental difference between threads and SIMD very well in lecture 2 (at around 37:00).
@arjunh: I want to stress that SIMD execution AND HW multi-threaded execution are techniques used by BOTH modern CPUs and modern GPUs in order to maximize the efficiency of these processors for more throughput oriented workloads. Having a set of ALUs share the resources for decoding an instruction stream is a far more efficient architecture for parallel workloads that demonstrate highly coherent execution.
@arjunh @kayvonf You are right. It IS more efficient. CPU or GPU, SIMD shall be on one of them anyway.