This idea of multi-threading depends on bandwidth limitations. If too much memory is accessed at once, exceeding the bandwidth, then latency hiding does not work. One solution is to increase arithmetic intensity (the ratio of math operations to memory accesses-- see slide 63) so stalls occur less often.
oulgen
How viable/feasible would it be to add a priority supporting (similar to that of an OS) thread/context switching mechanism? As I pointed out in the lecture, starvation and also importance of certain tasks over others seem like a crucial point that should be handled. In the OS level, doing this is expensive since context switching is not easy. However, on the processor level, this should be relative cheap.
ericwang
@oulgen I think priority mechanism should be doable but may be too complicated at this level. Basically processors are only responsible for executing the instructions without understanding the program's high level logic. So different threads only imply different groups of instructions that can be executed separately. Then processors can optimal the executing sequence accordingly with a simple logic: execute until stall/finish and switch to next thread.
If we allow priority, more information needs to be recorded in the registers/caches. Moreover, the core cannot treat all threads equally. That introduces extra logic for checking and comparing. Since the priority check might happen frequently, the performance of the core will be hurt. So I don't think it would be relative cheap. What's more, priority increases the risk of starvation.
So as for the starvation, I think there could be a limitation on single threads' running time for avoiding this problem.
aoeuidhtns
Does context switching only happen if there's a cache miss?
I'm assuming it happens only after a L1, L2, and L3 cache miss. Is this correct?
kayvonf
@aoeuidhtns: The best way to answer your question is to stay that context switching happens when the processor would otherwise stall. That is, it cannot run the next instruction in the current threads instruction stream due to a dependency on a prior instruction or operation that has not completed yet. Rather than wait, the process proceeds to "do something else", i.e., begin processing instructions from another thread.
In this lecture, we focused on stalls due to cache misses, since the latency of access memory is so high, these are incredibly long stalls.
But stalls can happen for many reasons, and this would be the subject of a good computer architecture class like 18-447.
For the architects in the house (or if you are familiar with the concept of pipelining), consider the fact that most instructions require several clocks to complete. Most GPU cores switch between threads each cycle (even when executing arithmetic instructions) to hide the latency of their instruction pipelines since in the presence of significant thread-level parallelism it's a much simpler and more efficient way to keep the pipeline full than complex out-of-order execution.
muyangya
In multi-threading, we are adopting a PROCESSOR level context switching to hide stalls. What interests me is how this will affect the OS level context switching?
Specifically:
What is the granularity of OS-level context switching in this time. Or to say, in the case of OS-level context switching, the OS would (1) switch all of those four threads with new ones, or (2) just switch a single thread?
It seems (1) would be more beneficial to throughput. However, this may leads to the following case: if a single thread in those 4 invokes an IO operations(maybe from disk), it will bring down the other three brother threads as well(since all those 4 threads will be context-switched out of the processor). It's really weird.
Zarathustra
If we hooked this processor up to an imaginary, infinitely large and infinitely fast cache, how would it decide when to switch contexts, since stalls would be eliminated? There are many, many programs which don't "finish execution", but instead run in a loop (perhaps idling, perhaps not). Then, I suppose, the processor will just throw X amount of cycles at each concurrently executing process and call it a day?
yuel1
@kayvonf So considering pipelining, when there is a context switch, does the pipeline have to be flushed?
kayvonf
@yuel1. The answer would depend on the processor's implementation. But in short, no. Every operation in the pipeline can just be tagged with the context its executing within, and the processor should use that information to carry out the instruction as needed.
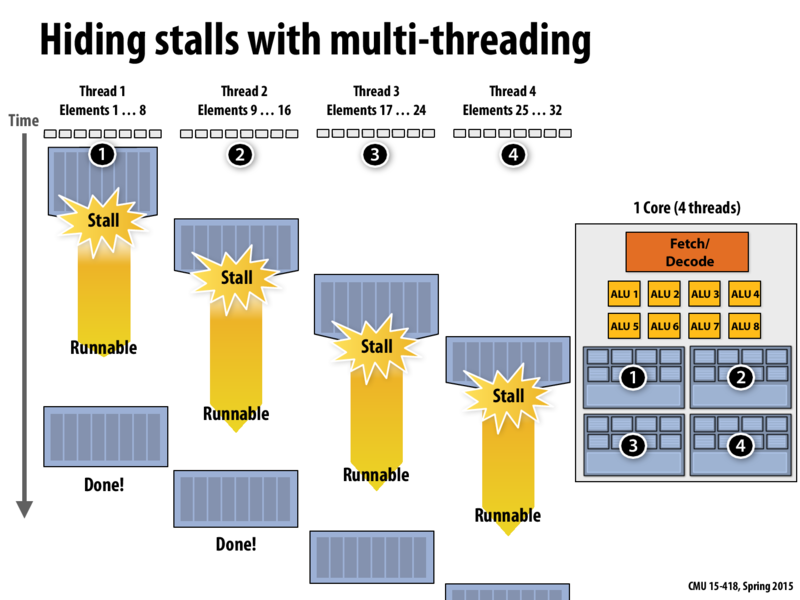
This idea of multi-threading depends on bandwidth limitations. If too much memory is accessed at once, exceeding the bandwidth, then latency hiding does not work. One solution is to increase arithmetic intensity (the ratio of math operations to memory accesses-- see slide 63) so stalls occur less often.
How viable/feasible would it be to add a priority supporting (similar to that of an OS) thread/context switching mechanism? As I pointed out in the lecture, starvation and also importance of certain tasks over others seem like a crucial point that should be handled. In the OS level, doing this is expensive since context switching is not easy. However, on the processor level, this should be relative cheap.
@oulgen I think priority mechanism should be doable but may be too complicated at this level. Basically processors are only responsible for executing the instructions without understanding the program's high level logic. So different threads only imply different groups of instructions that can be executed separately. Then processors can optimal the executing sequence accordingly with a simple logic: execute until stall/finish and switch to next thread.
If we allow priority, more information needs to be recorded in the registers/caches. Moreover, the core cannot treat all threads equally. That introduces extra logic for checking and comparing. Since the priority check might happen frequently, the performance of the core will be hurt. So I don't think it would be relative cheap. What's more, priority increases the risk of starvation.
So as for the starvation, I think there could be a limitation on single threads' running time for avoiding this problem.
Does context switching only happen if there's a cache miss?
I'm assuming it happens only after a L1, L2, and L3 cache miss. Is this correct?
@aoeuidhtns: The best way to answer your question is to stay that context switching happens when the processor would otherwise stall. That is, it cannot run the next instruction in the current threads instruction stream due to a dependency on a prior instruction or operation that has not completed yet. Rather than wait, the process proceeds to "do something else", i.e., begin processing instructions from another thread.
In this lecture, we focused on stalls due to cache misses, since the latency of access memory is so high, these are incredibly long stalls. But stalls can happen for many reasons, and this would be the subject of a good computer architecture class like 18-447.
For the architects in the house (or if you are familiar with the concept of pipelining), consider the fact that most instructions require several clocks to complete. Most GPU cores switch between threads each cycle (even when executing arithmetic instructions) to hide the latency of their instruction pipelines since in the presence of significant thread-level parallelism it's a much simpler and more efficient way to keep the pipeline full than complex out-of-order execution.
In multi-threading, we are adopting a PROCESSOR level context switching to hide stalls. What interests me is how this will affect the OS level context switching?
Specifically: What is the granularity of OS-level context switching in this time. Or to say, in the case of OS-level context switching, the OS would (1) switch all of those four threads with new ones, or (2) just switch a single thread?
It seems (1) would be more beneficial to throughput. However, this may leads to the following case: if a single thread in those 4 invokes an IO operations(maybe from disk), it will bring down the other three brother threads as well(since all those 4 threads will be context-switched out of the processor). It's really weird.
If we hooked this processor up to an imaginary, infinitely large and infinitely fast cache, how would it decide when to switch contexts, since stalls would be eliminated? There are many, many programs which don't "finish execution", but instead run in a loop (perhaps idling, perhaps not). Then, I suppose, the processor will just throw X amount of cycles at each concurrently executing process and call it a day?
@kayvonf So considering pipelining, when there is a context switch, does the pipeline have to be flushed?
@yuel1. The answer would depend on the processor's implementation. But in short, no. Every operation in the pipeline can just be tagged with the context its executing within, and the processor should use that information to carry out the instruction as needed.