I'm still trying to wrap my head around the Maxwell architecture vs Fermi, but they have a little over 4x the cuda cores, about 4x the memory, and the memory bandwidth and caches are slightly larger.
kayvonf
I'm going to wait until the GPU lecture before I answer this one in detail. In the mean time, I'll let you puzzle over it.
xSherlock
@jslone I had a similar curiosity, and ended up looking up the GTX Titan.
This version of the Titan has 2x more CUDA cores than the gtx-980, as well as 3x the memory bandwidth, and a significantly larger cache. For all this, the clock speed is roughly half, and the texture fill rate is about 2.5x. So it seems it makes some interesting tradeoffs versus the 980. The Titan Z seems to use yet another new architecture that they are calling the 'Pascal' architecture, which doesn't seem to be in any other consumer available graphics cards. Curious that it ends up with a fairly significantly lower clock rate; this will probably make more sense once we talk about GPUs in lecture.
admintio42
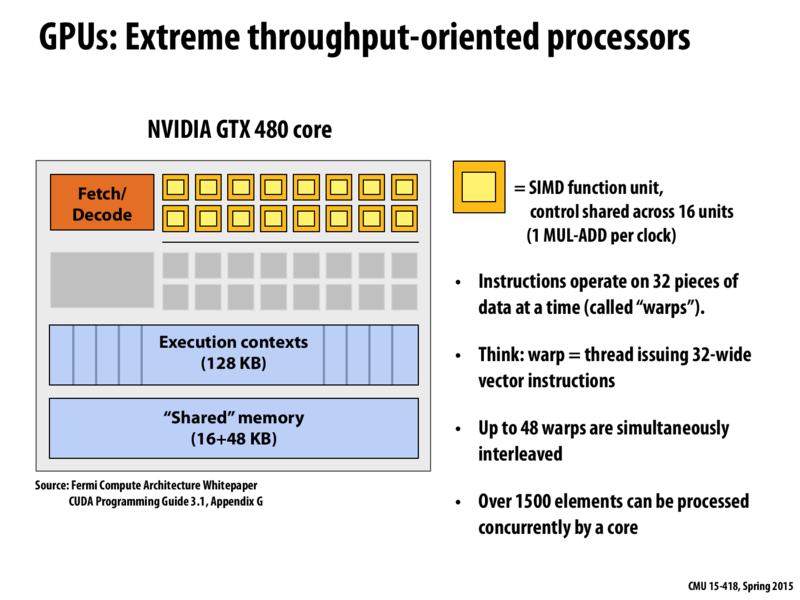
what does it mean that 1500 elements can be processed concurrently by a core? does this mean 1500 bytes of data can be read and executed?
kayvonf
@admintio42: It means that in terms of the running example in this lecture (sinx), 1500 array elements would be processed concurrently.
andrewwuan
I'm a bit confused when I reviewed this slide... So each SM can have at most 48 resident warps, but can all of them run concurrently? (I was reading the whitepaper of Fermi and it seems that it can only run 2 warps concurrently with 16 CUDA cores allocated to each warp, though a lot more warps can be assigned to an SM)
kayvonf
@andwerwuan: Remember, concurrent and parallel are different. The 48 resident warps are executing concurrently on the core via hardware multi-threading. As you read in the Fermi whitepaper, two of the warps are executed simultaneously.
In case anyone else was interested in looking at the specs of the 480's vs the new 980's.
http://www.geforce.com/hardware/desktop-gpus/geforce-gtx-480/specifications http://www.geforce.com/hardware/desktop-gpus/geforce-gtx-980/specifications
I'm still trying to wrap my head around the Maxwell architecture vs Fermi, but they have a little over 4x the cuda cores, about 4x the memory, and the memory bandwidth and caches are slightly larger.
I'm going to wait until the GPU lecture before I answer this one in detail. In the mean time, I'll let you puzzle over it.
@jslone I had a similar curiosity, and ended up looking up the GTX Titan.
http://www.geforce.com/hardware/desktop-gpus/geforce-gtx-titan-z/specifications
This version of the Titan has 2x more CUDA cores than the gtx-980, as well as 3x the memory bandwidth, and a significantly larger cache. For all this, the clock speed is roughly half, and the texture fill rate is about 2.5x. So it seems it makes some interesting tradeoffs versus the 980. The Titan Z seems to use yet another new architecture that they are calling the 'Pascal' architecture, which doesn't seem to be in any other consumer available graphics cards. Curious that it ends up with a fairly significantly lower clock rate; this will probably make more sense once we talk about GPUs in lecture.
what does it mean that 1500 elements can be processed concurrently by a core? does this mean 1500 bytes of data can be read and executed?
@admintio42: It means that in terms of the running example in this lecture (
sinx), 1500 array elements would be processed concurrently.I'm a bit confused when I reviewed this slide... So each SM can have at most 48 resident warps, but can all of them run concurrently? (I was reading the whitepaper of Fermi and it seems that it can only run 2 warps concurrently with 16 CUDA cores allocated to each warp, though a lot more warps can be assigned to an SM)
@andwerwuan: Remember, concurrent and parallel are different. The 48 resident warps are executing concurrently on the core via hardware multi-threading. As you read in the Fermi whitepaper, two of the warps are executed simultaneously.