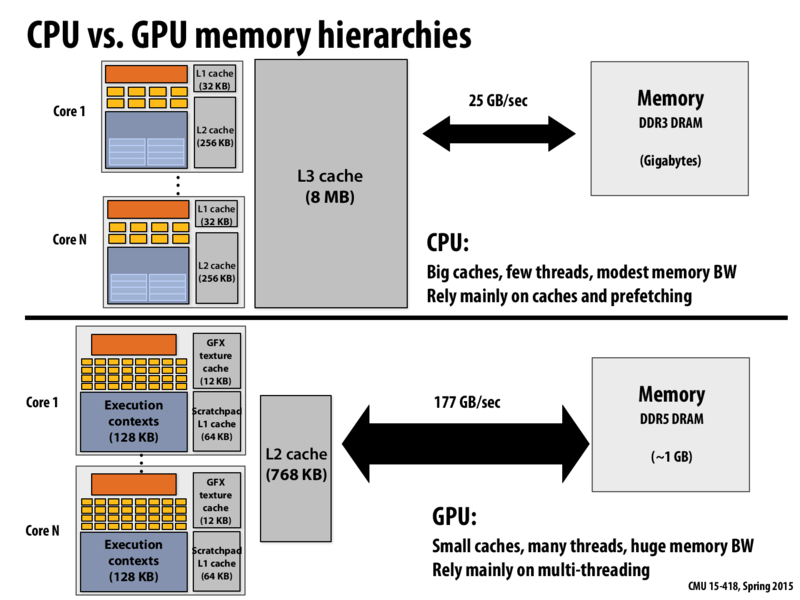
What is the purpose of having two caches in the cores? Does the L1 cache refer to the L2 cache in the case of an L1 cache miss, or are do they store different information altogether?
Azerty
I think if there is a cache miss with L1, then the processor checks L2. L1 is checked first as it is faster (because smaller) than L2.
ESINNG
@DudaK: Usually L1 cache store a subset of data of L2 cache, and when the CPU want some data which is not in L1 cache but in L2 cache, it will first read it to L1 cache and then to CPU. The reason why there are two caches is because L1 cache is faster and more expansive than L2 cache. So usually L2 cache is larger than L1 cache. Hope it solve your question.
Berry
Question: Does the above slide simply distinguish between quantity and quality when it comes to using data? I say this because both architectures use caching and the bottom one seems to care a lot less about cache misses than the top one in order to achieve its performance. Is there something deeper going on here than a mere difference in data reuse expectations? Why doesn't the GPU care as much about cache evictions and thrashing than the CPU even though both have the same number of logical cores/threads?
arjunh
@Berry Just to clarify, CPU's and GPU's do not have the same number of cores/threads; the N is not the same for both diagrams.
One of the main reasons why GPU's don't care about caching nearly as much as CPU's is that the workloads given to GPU's generally don't have a lot of data-reuse. Since there are many more threads available on a GPU, a GPU gets its speedup from executing many tasks at once. On the other hand, a CPU has limited cores and thus must rely upon caching much more to get good performance. In order to keep all the cores busy, a GPU also needs a very high bandwidth memory bus to transfer data to the cores.
When we look at GPU's and CUDA in more detail, we'll learn more about the types of memory available to GPU programmers. You can make small optimizations by placing data that is to be only read in read-only memory. Also, threads in the same block share block memory. So, there are ways to improve the memory usage of GPU's, but that's not the primary optimization that is emphasized.
kayvonf
The point of this slide is that the memory hierarchies of CPUs and GPUs are quite different. A key feature of the CPU memory hierarchy is the presence of large caches to minimize latency. Since the hope is that most memory requests get serviced from the caches, less bandwidth out to main memory is necessary. (Caches not only act as a mechanism to reduce the latency of data access, they act as a filter "absorbing" many of the memory fetches that would have consumed bandwidth if they needed to be services by DRAM.)
The GPU memory hierarchy features smaller caches but much larger main memory bandwidth. GPU architects anticipate workloads that don't cache as well as CPU workloads, so they leave big caches out of the design and instead design extremely high bandwidth memories and highly multi-threaded processors to hide the latency of all the resulting high-latency memory fetches.
apoms
Where does Intel's Xeon Phi fall into this spectrum? If I remember correctly, they schedule their threads using a software scheduler (thus non single cycle scheduling time?) so I imagine they would need a coarser partitioning of work.
Additionally, Xeon Phi's have a much more coherent cache than GPUs. How does this affect the performance of programs written for the Xeon Phi?
I was also told that NVIDIA's SIMD implementation includes a PC register per lane while Intel's does not, thus requiring the user to manually manage masks for branch divergence. Is this true and is having a PC per lane the only solution? How would that even be supported in Intel's programming model?
What is the purpose of having two caches in the cores? Does the L1 cache refer to the L2 cache in the case of an L1 cache miss, or are do they store different information altogether?
I think if there is a cache miss with L1, then the processor checks L2. L1 is checked first as it is faster (because smaller) than L2.
@DudaK: Usually L1 cache store a subset of data of L2 cache, and when the CPU want some data which is not in L1 cache but in L2 cache, it will first read it to L1 cache and then to CPU. The reason why there are two caches is because L1 cache is faster and more expansive than L2 cache. So usually L2 cache is larger than L1 cache. Hope it solve your question.
Question: Does the above slide simply distinguish between quantity and quality when it comes to using data? I say this because both architectures use caching and the bottom one seems to care a lot less about cache misses than the top one in order to achieve its performance. Is there something deeper going on here than a mere difference in data reuse expectations? Why doesn't the GPU care as much about cache evictions and thrashing than the CPU even though both have the same number of logical cores/threads?
@Berry Just to clarify, CPU's and GPU's do not have the same number of cores/threads; the N is not the same for both diagrams.
One of the main reasons why GPU's don't care about caching nearly as much as CPU's is that the workloads given to GPU's generally don't have a lot of data-reuse. Since there are many more threads available on a GPU, a GPU gets its speedup from executing many tasks at once. On the other hand, a CPU has limited cores and thus must rely upon caching much more to get good performance. In order to keep all the cores busy, a GPU also needs a very high bandwidth memory bus to transfer data to the cores.
When we look at GPU's and CUDA in more detail, we'll learn more about the types of memory available to GPU programmers. You can make small optimizations by placing data that is to be only read in read-only memory. Also, threads in the same block share block memory. So, there are ways to improve the memory usage of GPU's, but that's not the primary optimization that is emphasized.
The point of this slide is that the memory hierarchies of CPUs and GPUs are quite different. A key feature of the CPU memory hierarchy is the presence of large caches to minimize latency. Since the hope is that most memory requests get serviced from the caches, less bandwidth out to main memory is necessary. (Caches not only act as a mechanism to reduce the latency of data access, they act as a filter "absorbing" many of the memory fetches that would have consumed bandwidth if they needed to be services by DRAM.)
The GPU memory hierarchy features smaller caches but much larger main memory bandwidth. GPU architects anticipate workloads that don't cache as well as CPU workloads, so they leave big caches out of the design and instead design extremely high bandwidth memories and highly multi-threaded processors to hide the latency of all the resulting high-latency memory fetches.
Where does Intel's Xeon Phi fall into this spectrum? If I remember correctly, they schedule their threads using a software scheduler (thus non single cycle scheduling time?) so I imagine they would need a coarser partitioning of work.
Additionally, Xeon Phi's have a much more coherent cache than GPUs. How does this affect the performance of programs written for the Xeon Phi?
I was also told that NVIDIA's SIMD implementation includes a PC register per lane while Intel's does not, thus requiring the user to manually manage masks for branch divergence. Is this true and is having a PC per lane the only solution? How would that even be supported in Intel's programming model?