It seems like data-parallelism is best suited, since on large datasets any one of these boxes will have more independent jobs to do than all of your processors, with only some cost to synchronization.
kk
Also, parallelizing over grids on the same level may introduce extra memory traffic as we fill up the cache with non-related data from multiple distinct grids.
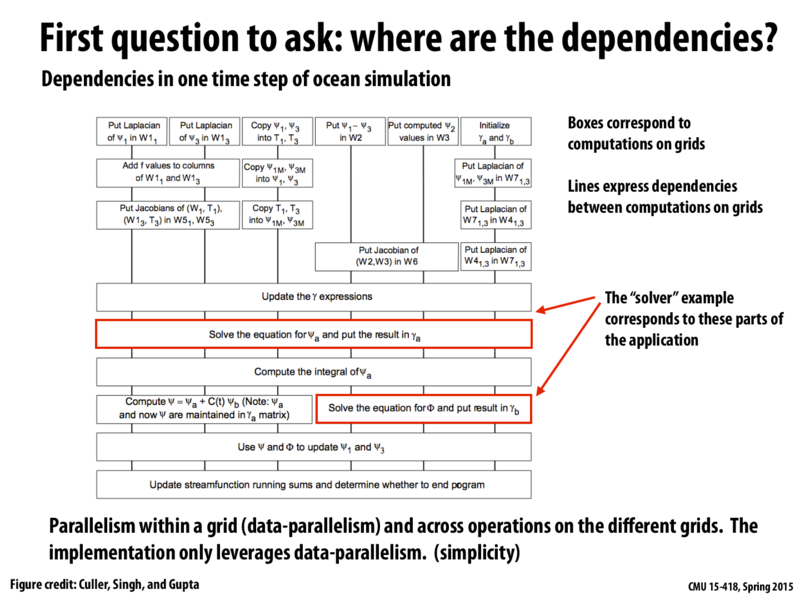
It seems like data-parallelism is best suited, since on large datasets any one of these boxes will have more independent jobs to do than all of your processors, with only some cost to synchronization.
Also, parallelizing over grids on the same level may introduce extra memory traffic as we fill up the cache with non-related data from multiple distinct grids.