The 4D array layout reduces contention between processors, but doesn't reduce the amount of data sent between processors, because the whole cache line is sent anyway, right?
jezimmer
I was thinking about this 4D blocked layout today in relation to modeling a sudoku board (I wanted to implement a solver to get familiar with a new language). The trick with implementing a sudoku solver is that you need to be able to check a condition across rows, columns, and blocks. Is there some sort of static assignment that would work well to magically combine the efficiency of row/col/block major ordering into a data structure that allows all three operations to be efficient?
mingf
Is it the programmer's responsibility for laying out a cache friendly array?
rbcarlso
@jezimmer: This is an interesting problem. My gut instinct would be to just go with block-major order, assuming you don't want three different arrays. We can try looking at this by cases:
Block-major order:
1 block's data needed to analyze a block - no sharing
3 blocks' data needed to analyze a row - 2 shared
3 blocks' data needed to analyze a column - 2 shared
Row-major order:
3 rows' data needed to analyze a block - 2 shared
1 row's data needed to analyze a row - no sharing
9 rows' data needed to analyze a column - 8 shared
Column-major order:
3 columns' data needed to analyze a block - 2 shared
9 columns' data needed to analyze a row - 8 shared
1 column's data needed to analyze a column - no sharing
So the problem with row or column major orderings in Sudoku is that rows work poorly with columns and vice versa. They both work reasonably well with blocks, though.
As for magic combinations, I've got no idea but I suspect that Sudoku validation's just an inherently complicated problem in this regard.
Faust
@caretcaret I believe that the main benefit from the 4D array layout here is to reduce artifactual communication as from last lecture. I also believe that because no cache line will straddle the partition border in the 4D array, we will actually be transferring less data in some circumstances.
apoms
Another benefit of the 4D blocked layout is that a hardware prefetcher might be able to predict the memory accesses and thus dramatically reduce memory latency times without involved software prefetching instructions.
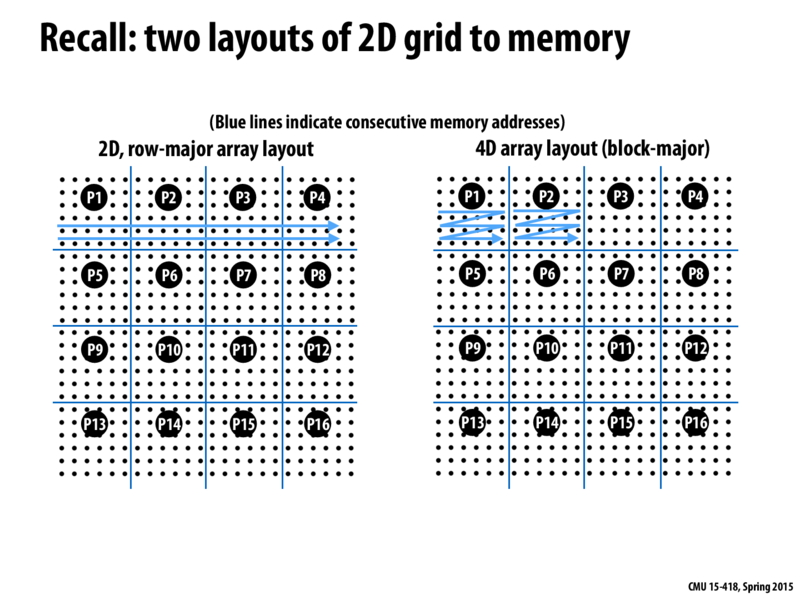
The 4D array layout reduces contention between processors, but doesn't reduce the amount of data sent between processors, because the whole cache line is sent anyway, right?
I was thinking about this 4D blocked layout today in relation to modeling a sudoku board (I wanted to implement a solver to get familiar with a new language). The trick with implementing a sudoku solver is that you need to be able to check a condition across rows, columns, and blocks. Is there some sort of static assignment that would work well to magically combine the efficiency of row/col/block major ordering into a data structure that allows all three operations to be efficient?
Is it the programmer's responsibility for laying out a cache friendly array?
@jezimmer: This is an interesting problem. My gut instinct would be to just go with block-major order, assuming you don't want three different arrays. We can try looking at this by cases:
Block-major order:
1 block's data needed to analyze a block - no sharing
3 blocks' data needed to analyze a row - 2 shared
3 blocks' data needed to analyze a column - 2 shared
Row-major order:
3 rows' data needed to analyze a block - 2 shared
1 row's data needed to analyze a row - no sharing
9 rows' data needed to analyze a column - 8 shared
Column-major order:
3 columns' data needed to analyze a block - 2 shared
9 columns' data needed to analyze a row - 8 shared
1 column's data needed to analyze a column - no sharing
So the problem with row or column major orderings in Sudoku is that rows work poorly with columns and vice versa. They both work reasonably well with blocks, though.
As for magic combinations, I've got no idea but I suspect that Sudoku validation's just an inherently complicated problem in this regard.
@caretcaret I believe that the main benefit from the 4D array layout here is to reduce artifactual communication as from last lecture. I also believe that because no cache line will straddle the partition border in the 4D array, we will actually be transferring less data in some circumstances.
Another benefit of the 4D blocked layout is that a hardware prefetcher might be able to predict the memory accesses and thus dramatically reduce memory latency times without involved software prefetching instructions.