I don't quite get why each processor can compute its assignment of bodies independently, since processor Pi need to know the number of bodies already assigned to P0 to P(i-1) and such a number depends on the specific per-body costs.
Berry
I am also unsure of this but one way to do it would be with an exclusive sum scan on the leaves. In this case each processor i can find iW/p and accumulate work until it reaches (i+1)W/p.
jazzbass
@doodoloo I may be wrong with this, but here's what I think:
If you know the value of W, I think that each processor can find it's assigned leafs easily, simply traverse the tree from left to right until you have seen at least iW/P work (*).
Now, to find the value of W, we could perform a parallel DFS on the tree, each worker estimates the amount of work that needs to be done for each leaf and accumulates this value (perhaps store estimated work for intermediate nodes as well? This way we can make (*) more efficient), and we make a sum reduction over the estimates of all workers to get the value of W.
parallelfifths
This is an aside, but in doing Assignment 3, I remember reading that depth first search is more difficult to parallelize than breadth first search. Not having taken any classes before this that covered algorithms, I can get a very high-level sense of why DFS might be difficult to parallelize because of the dependencies of searching through hierarchical chains of vertices, but can anyone provide a better explanation than that or point me to a resource that does so?
So if you look at the pseudocode for the iterative version then you'll notice that every unvisited node pushes its neighbors on a stack to be checked. If we parallelized by having each thread take an element off the stack then we would require locks every time a thread checks a node to see if it's unvisited. Why? A node could be added to the stack multiple times so threads could work on the same node and add all its neighbors if they all think it's unvisited. Worst case, this could mean with k threads we do k times the work which isn't too parallel... Even if we fix this with a lock when popping elements, lock on our record of unvisited nodes, and sequentially add to the stack then we have the majority of operations being costly sequential ones. Thus, it's difficult to make a greatly parallel DFS with simple data structures. One way people have been optimizing it is to use concurrent hash maps. This allows for threads to lock on different ranges of nodes instead of all nodes. Also, to avoid contention on the stack we could have each thread keep its own stack but that may lead to workload imbalance.
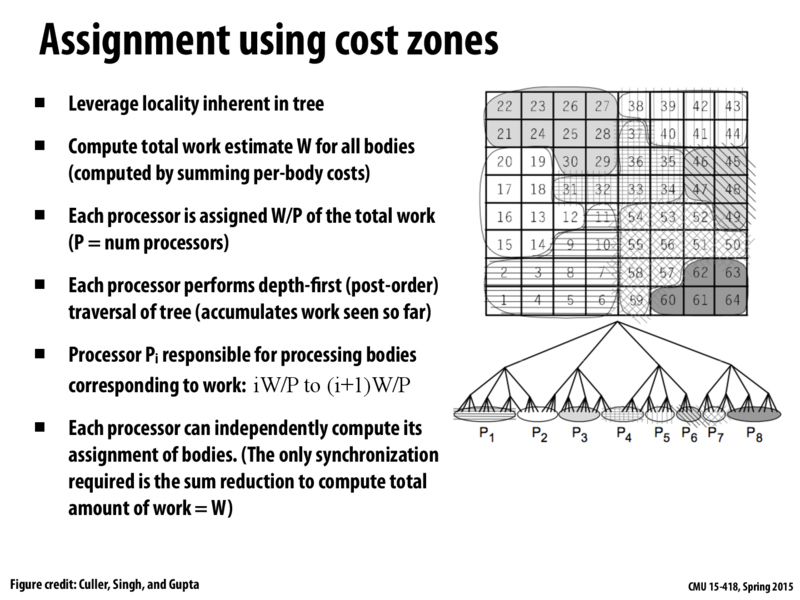
I don't quite get why each processor can compute its assignment of bodies independently, since processor Pi need to know the number of bodies already assigned to P0 to P(i-1) and such a number depends on the specific per-body costs.
I am also unsure of this but one way to do it would be with an exclusive sum scan on the leaves. In this case each processor i can find iW/p and accumulate work until it reaches (i+1)W/p.
@doodoloo I may be wrong with this, but here's what I think:
If you know the value of W, I think that each processor can find it's assigned leafs easily, simply traverse the tree from left to right until you have seen at least iW/P work (*).
Now, to find the value of W, we could perform a parallel DFS on the tree, each worker estimates the amount of work that needs to be done for each leaf and accumulates this value (perhaps store estimated work for intermediate nodes as well? This way we can make (*) more efficient), and we make a sum reduction over the estimates of all workers to get the value of W.
This is an aside, but in doing Assignment 3, I remember reading that depth first search is more difficult to parallelize than breadth first search. Not having taken any classes before this that covered algorithms, I can get a very high-level sense of why DFS might be difficult to parallelize because of the dependencies of searching through hierarchical chains of vertices, but can anyone provide a better explanation than that or point me to a resource that does so?
@parallelfifths: http://en.m.wikipedia.org/wiki/Depth-first_search
So if you look at the pseudocode for the iterative version then you'll notice that every unvisited node pushes its neighbors on a stack to be checked. If we parallelized by having each thread take an element off the stack then we would require locks every time a thread checks a node to see if it's unvisited. Why? A node could be added to the stack multiple times so threads could work on the same node and add all its neighbors if they all think it's unvisited. Worst case, this could mean with k threads we do k times the work which isn't too parallel... Even if we fix this with a lock when popping elements, lock on our record of unvisited nodes, and sequentially add to the stack then we have the majority of operations being costly sequential ones. Thus, it's difficult to make a greatly parallel DFS with simple data structures. One way people have been optimizing it is to use concurrent hash maps. This allows for threads to lock on different ranges of nodes instead of all nodes. Also, to avoid contention on the stack we could have each thread keep its own stack but that may lead to workload imbalance.