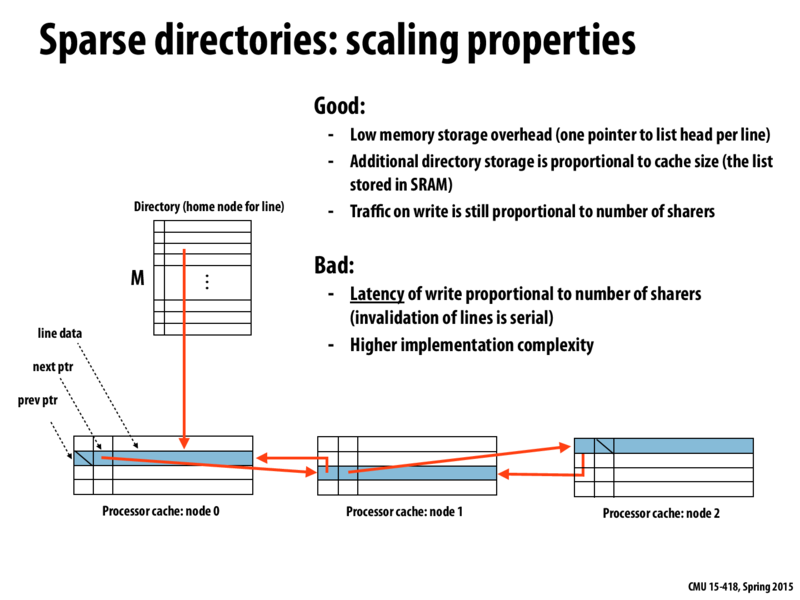
We determined that the number of links in this chain (the number of processors we need to talk to before we can complete a write) would be small empirically, but did we ever discuss the intuition behind why it should be small?
rbcarlso
I think it's because in general when you try to parallelize something you try to limit the number of processors that are working on a particular section of memory at a time. The kinds of programs that a sparse directory hurts are the kinds that often could have been written better even if there weren't a sparse directory.
Olorin
To elaborate a bit on @rbcarlso's answer, in general the advantage of parallelization is that different processors can do different work at the same time. Most of the time, that different work involves computations on independent data (think about the BFS and, to a lesser extent, sorting from assignment 3).
If there's a lot of shared data between different threads, we're going to incur a huge cost to ensure that we synchronize access to it safely (e.g. by using locks). It's for this reason that we want to limit the number of processors accessing one part of memory at the same time.
We determined that the number of links in this chain (the number of processors we need to talk to before we can complete a write) would be small empirically, but did we ever discuss the intuition behind why it should be small?
I think it's because in general when you try to parallelize something you try to limit the number of processors that are working on a particular section of memory at a time. The kinds of programs that a sparse directory hurts are the kinds that often could have been written better even if there weren't a sparse directory.
To elaborate a bit on @rbcarlso's answer, in general the advantage of parallelization is that different processors can do different work at the same time. Most of the time, that different work involves computations on independent data (think about the BFS and, to a lesser extent, sorting from assignment 3).
If there's a lot of shared data between different threads, we're going to incur a huge cost to ensure that we synchronize access to it safely (e.g. by using locks). It's for this reason that we want to limit the number of processors accessing one part of memory at the same time.