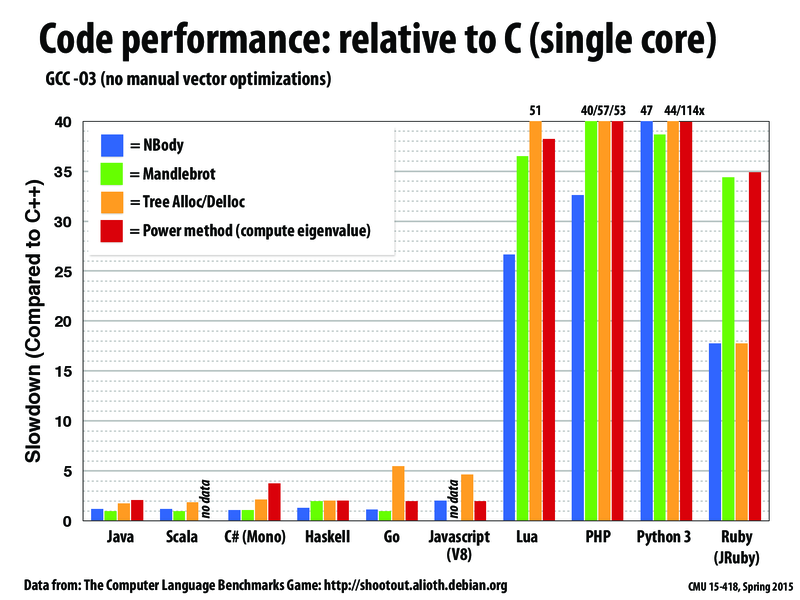
Any thoughts about where a language like R would fit in here? I recently faced the task of re-implementing a deep learning algorithm in C from R, it led to a speedup of about 180x!
bwf
I'd imagine R would be on the slower end of things. R was written to make stats programming easier to learn and do, not for high performance.
Seeing Java up there was a huge surprise to me because I usually think of it as an interpreted language like Python or PHP, but then I recalled that Java code is compiled to something like an executable that the Java VM runs; the compiler can make optimizations, but the JVM is still an application so more instructions have to run than would with a native binary compiled from C code, so faster than PHP and slower than C makes sense.
I think there's such a thing as Python binaries too, though. Were these tests done with Python 3 as interpreted language or Python 3 as compiled language?
flyne
Where would be Matlab fall in this list? Anybody knows of any resource for R and Matlab performance comparison.
top
@flyne From what I've found Matlab seems to be a lot faster than R in terms of matrix operations but can fall short in some particular cases. One particular reason is Matlab is sometimes smart enough to try and vectorize for loop while R has no such functionality. What's more interesting to me is how the Julia language performs. They seem to have taken the approach similar to Halide where the programmer can specify how computation should be parallized if at all.
The Julia homepage goes into more detail about how parallism works in the language and gives some benchmarks for common tasks done in Matlab and R.
jcarchi
Not surprisingly, compiled languages perform more like C (also compiled), vs scripting/interpreted languages
rhnil
Although the performance of Python seems terrible in the graph, there are packages like NumPy or SciPy which support efficient scientific computing. Some matrix operations in NumPy may use SIMD to parallelize computation, and many routines in NumPy/SciPy essentially call fast low-level implementation in C or Fortran (e.g. singular value decomposition (SVD) in SciPy can use multi-core processors to speedup computation).
fgomezfr
@rhnil: I think your comment about NumPy touches a similar nerve as the earlier question about compiled vs scripted/interpreted execution. In the end, everything compiles to x86, or to some intermediate language that is executed by a piece of code in native assembly. When you say NumPy calling low-level implementations in C or SIMD intrinsics is fast, that doesn't really validate Python; it just says that fast assembly is fast!
I believe the point of this comparison was to show what the typical/best compiler/interpreter does with the language, from the standpoint of programmer productivity. Yes, you could hand-write a fast SIMD implementation and link to it in Python. But that's not how the languages are intended to be used - Python exists so you can write Python, not SSE intrinsics!
The question asked is, if a programmer sits down to write some code in Python, what can he/she expect to get out of it? If the test used an interpreter, that is a fair comparison - it's judging whether the Python interpreter, a procedure written (likely) in C that simulates execution of some non-C code, can match the performance of re-writing that code in C. Are compilers/interpreters smart enough to perform really well, and/or is the increase in programmer productivity that may accompany a higher-level language worth the difference?
In other words, this isn't about language design - every language specifies procedures and operations on memory in some form, because that's what computers do for us. Different languages make it easier/harder to describe different procedures, and that's fine. The question was, how well do the platforms that translate those high-level abstractions into actual running binary hold up? (To a lesser extent, it tests the ability of the language design to specify procedures in ways that allow the compiler/interpreter to identify dependencies and patterns that influence the implementation it should generate for best performance.)
So to me, a NumPy implementation with a hand-coded C back-end isn't really a test of Python - it's a test of your C back-end :)
It may be that the design of your language (like much of Python and Matlab) is that everything will be implemented in C behind-the-scenes; then the performance of that C back-end, when used to execute some new Python/Matlab code, would be part of the benchmark.
rhnil
@fgomezfr I think you have made a great point. I totally agree that we should test procedures implemented in pure Python if we want to compare the performance of Python with other languages. When I mentioned NumPy/SciPy in my last comment, I did not mean that Python is fast because of these libraries. Rather, I was talking about a common way to achieve a good balance between productivity and performance. By "productivity", I refer to expressiveness of languages as well as availability of libraries. "Glue languages" like Python allows us to specify what to do and focus less on how to do it. Frequently used functionalities can be implemented efficient enough using the most suitable mechanisms which is invisible to programmers. I guess the situation is a little similar to languages like Liszt and Halide discussed in class, which separate "descriptions" of programs from implementation and optimization details in different platforms, though these domain-specific languages have taken a different approach.
Any thoughts about where a language like R would fit in here? I recently faced the task of re-implementing a deep learning algorithm in C from R, it led to a speedup of about 180x!
I'd imagine R would be on the slower end of things. R was written to make stats programming easier to learn and do, not for high performance.
You can read more about it here: http://adv-r.had.co.nz/Performance.html
Seeing Java up there was a huge surprise to me because I usually think of it as an interpreted language like Python or PHP, but then I recalled that Java code is compiled to something like an executable that the Java VM runs; the compiler can make optimizations, but the JVM is still an application so more instructions have to run than would with a native binary compiled from C code, so faster than PHP and slower than C makes sense.
I think there's such a thing as Python binaries too, though. Were these tests done with Python 3 as interpreted language or Python 3 as compiled language?
Where would be Matlab fall in this list? Anybody knows of any resource for R and Matlab performance comparison.
@flyne From what I've found Matlab seems to be a lot faster than R in terms of matrix operations but can fall short in some particular cases. One particular reason is Matlab is sometimes smart enough to try and vectorize for loop while R has no such functionality. What's more interesting to me is how the Julia language performs. They seem to have taken the approach similar to Halide where the programmer can specify how computation should be parallized if at all.
Here are some links where you can read more.
Matlab vs R
Julia Language
The Julia homepage goes into more detail about how parallism works in the language and gives some benchmarks for common tasks done in Matlab and R.
Not surprisingly, compiled languages perform more like C (also compiled), vs scripting/interpreted languages
Although the performance of Python seems terrible in the graph, there are packages like NumPy or SciPy which support efficient scientific computing. Some matrix operations in NumPy may use SIMD to parallelize computation, and many routines in NumPy/SciPy essentially call fast low-level implementation in C or Fortran (e.g. singular value decomposition (SVD) in SciPy can use multi-core processors to speedup computation).
@rhnil: I think your comment about NumPy touches a similar nerve as the earlier question about compiled vs scripted/interpreted execution. In the end, everything compiles to x86, or to some intermediate language that is executed by a piece of code in native assembly. When you say NumPy calling low-level implementations in C or SIMD intrinsics is fast, that doesn't really validate Python; it just says that fast assembly is fast!
I believe the point of this comparison was to show what the typical/best compiler/interpreter does with the language, from the standpoint of programmer productivity. Yes, you could hand-write a fast SIMD implementation and link to it in Python. But that's not how the languages are intended to be used - Python exists so you can write Python, not SSE intrinsics!
The question asked is, if a programmer sits down to write some code in Python, what can he/she expect to get out of it? If the test used an interpreter, that is a fair comparison - it's judging whether the Python interpreter, a procedure written (likely) in C that simulates execution of some non-C code, can match the performance of re-writing that code in C. Are compilers/interpreters smart enough to perform really well, and/or is the increase in programmer productivity that may accompany a higher-level language worth the difference?
In other words, this isn't about language design - every language specifies procedures and operations on memory in some form, because that's what computers do for us. Different languages make it easier/harder to describe different procedures, and that's fine. The question was, how well do the platforms that translate those high-level abstractions into actual running binary hold up? (To a lesser extent, it tests the ability of the language design to specify procedures in ways that allow the compiler/interpreter to identify dependencies and patterns that influence the implementation it should generate for best performance.)
So to me, a NumPy implementation with a hand-coded C back-end isn't really a test of Python - it's a test of your C back-end :) It may be that the design of your language (like much of Python and Matlab) is that everything will be implemented in C behind-the-scenes; then the performance of that C back-end, when used to execute some new Python/Matlab code, would be part of the benchmark.
@fgomezfr I think you have made a great point. I totally agree that we should test procedures implemented in pure Python if we want to compare the performance of Python with other languages. When I mentioned NumPy/SciPy in my last comment, I did not mean that Python is fast because of these libraries. Rather, I was talking about a common way to achieve a good balance between productivity and performance. By "productivity", I refer to expressiveness of languages as well as availability of libraries. "Glue languages" like Python allows us to specify what to do and focus less on how to do it. Frequently used functionalities can be implemented efficient enough using the most suitable mechanisms which is invisible to programmers. I guess the situation is a little similar to languages like Liszt and Halide discussed in class, which separate "descriptions" of programs from implementation and optimization details in different platforms, though these domain-specific languages have taken a different approach.
how have we not mentioned sml?