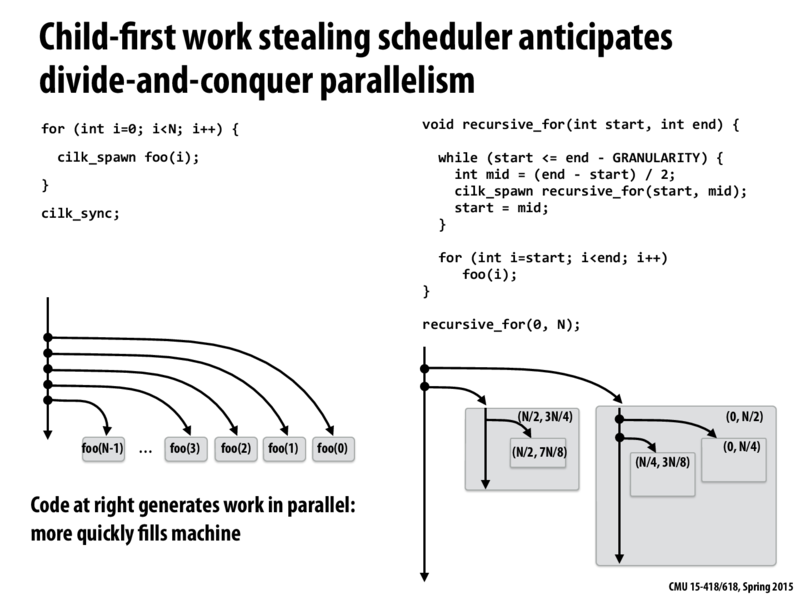
I actually do not understand how the code on right is splitting the things as shown in graph. Can someone explain it ?
jazzbass
@sam Here's what I believe that's happening:
In the beginning, the initial task creates the task (0, N/2). Afterwards, the initial task is only responsible for creating new tasks in the interval (N/2, N). If we continue focusing on the initial task (going down the leftmost line), it will keep creating tasks for it's assigned interval, until the interval is smaller than the granularity. Specifically, the next tasks that it would create would be: (N/2, 3N/4) (shown on the left), (3N/4, 7N/8) (not shown), (7N/8, 15N/8) (not shown), etc.
What is shown in the graph are the child tasks of the two first tasks that the initial task creates.
Specifically, (0, N/2) (right side) would first generate the task (0, N/4), and then it would start filling the interval (N/4, N/2), therefore it would create the task (N/4, 3N/8), and continue working on the interval (3N/8, N/2) as shown in the right side of the picture. Similar idea for the left side of the picture.
I do think there is a small bug in the left side of the picture though, I think that the spawned child of (N/2, 3N/4) should be (N/2, 5N/8). 7N/8 does not lie in the range (N/2, 3N/4).
rhnil
I think it is also helpful to compare the for loop on the left with the while loop on the right when we call recursive_for(0, N). The while loops spawns tasks (0, N/2), (N/2, 3N/4), (3N/4, 7N/8), ... until the remaining range is smaller than the granularity. This is similar to the case on the left when foo(0), foo(1), foo(2), ... are spawned in order. The difference for the recursive case is that the spawned "top-level" tasks may spawn their own children to further partition the range.
jcarchi
This diagram is actually a good reference for why to use cilk_for vs many cilk_spawn. Cilk_for allows scheduling to be done in parallel (like the tree in the figure)
parallelfifths
I think that this slide makes clear why we might want to use Cilk over OpenMP in certain cases. Kayvon highlights the semantic differences between Cilk and OpenMp for the left-hand side of this slide on Slide 22 of this lecture. Despite those semantic differences, it seems like if your goal is to achieve the structure of parallelism on the left-hand side of this slide, you could often achieve a similar outcome with a similar amount of programming work in both Cilk and OpenMP. The divide and conquer parallelism on the right-hand side of this slide that keeps forking recursively seems more difficult or at least less intuitive to achieve with OpenMP syntax.
HCN
I agree with @parallelfifths , Cilk may be better at divide and conquer than OpenMP.
The code on the right should use:
int mid = (end+start)/2
or
int mid = start + (end-start)/2
I actually do not understand how the code on right is splitting the things as shown in graph. Can someone explain it ?
@sam Here's what I believe that's happening:
In the beginning, the initial task creates the task (0, N/2). Afterwards, the initial task is only responsible for creating new tasks in the interval (N/2, N). If we continue focusing on the initial task (going down the leftmost line), it will keep creating tasks for it's assigned interval, until the interval is smaller than the granularity. Specifically, the next tasks that it would create would be: (N/2, 3N/4) (shown on the left), (3N/4, 7N/8) (not shown), (7N/8, 15N/8) (not shown), etc.
What is shown in the graph are the child tasks of the two first tasks that the initial task creates.
Specifically, (0, N/2) (right side) would first generate the task (0, N/4), and then it would start filling the interval (N/4, N/2), therefore it would create the task (N/4, 3N/8), and continue working on the interval (3N/8, N/2) as shown in the right side of the picture. Similar idea for the left side of the picture.
I do think there is a small bug in the left side of the picture though, I think that the spawned child of (N/2, 3N/4) should be (N/2, 5N/8). 7N/8 does not lie in the range (N/2, 3N/4).
I think it is also helpful to compare the
forloop on the left with thewhileloop on the right when we callrecursive_for(0, N). Thewhileloops spawns tasks (0, N/2), (N/2, 3N/4), (3N/4, 7N/8), ... until the remaining range is smaller than the granularity. This is similar to the case on the left whenfoo(0),foo(1),foo(2), ... are spawned in order. The difference for the recursive case is that the spawned "top-level" tasks may spawn their own children to further partition the range.This diagram is actually a good reference for why to use cilk_for vs many cilk_spawn. Cilk_for allows scheduling to be done in parallel (like the tree in the figure)
I think that this slide makes clear why we might want to use Cilk over OpenMP in certain cases. Kayvon highlights the semantic differences between Cilk and OpenMp for the left-hand side of this slide on Slide 22 of this lecture. Despite those semantic differences, it seems like if your goal is to achieve the structure of parallelism on the left-hand side of this slide, you could often achieve a similar outcome with a similar amount of programming work in both Cilk and OpenMP. The divide and conquer parallelism on the right-hand side of this slide that keeps forking recursively seems more difficult or at least less intuitive to achieve with OpenMP syntax.
I agree with @parallelfifths , Cilk may be better at divide and conquer than OpenMP.