Can someone elaborate on how SIMD and multi-threaded execution work together on a single core in GPU? In particular, what does "multi-threaded" imply here?
fgomezfr
I believe "multi-threaded" refers to two things here:
1 - Multiple execution contexts maintained on each core. Remember that while each core executes code for a SIMD-width 'warp' or 'wavefront' of threads, multiple warps' execution contexts can be stored, ready to execute on the next instruction. The GPU uses this to perform latency hiding, running multiple warps concurrently (recall concurrently != simultaneously - it may be that only one warp executes at a time, but all are ready to execute).
2 - While #1 above is the key point, it's also worth remembering that GPU code typically implements 'implicit' parallelism in SIMD. That is, you write scalar programs which are then mapped to multiple 'threads' which can each run in a single SIMD lane. So each SIMD 'lane' is usually a separate 'thread' of execution, i.e. a separate instance of a program, which is not the same as using a SIMD intrinsic to perform a small piece of work (like a small bit of vector math) in a single-threaded application. This is crossing the line between hardware architecture and the software abstractions that it (usually) implements, so I think #1 is what Kayvon meant here, but still worth mentioning since the definition of 'thread' here is a little ambiguous.
kayvonf
@fgomezfr: I meant both.
The chip is multi-threaded, like you mention, because it maintains many hardware execution contexts per core.
The chip also is SIMD in that all the work mapped to "lanes" of one execution context execute in parallel using SIMD execution. Or, if you want to think about it in an "implicit SIMD" or "SIMT" manner (which is more applicable on this slide since we are talking about GPUs), it's fair to say an execution context is scalar and that multiple execution contexts are executed together in SIMD fashion.
meatie
Thanks for the explanation!
My understanding of the GPU architecture now is:
there is a chip;
on this chip, there are multiple cores that can run simultaneously;
within a core, there are multiple threads/warps which can run concurrently;
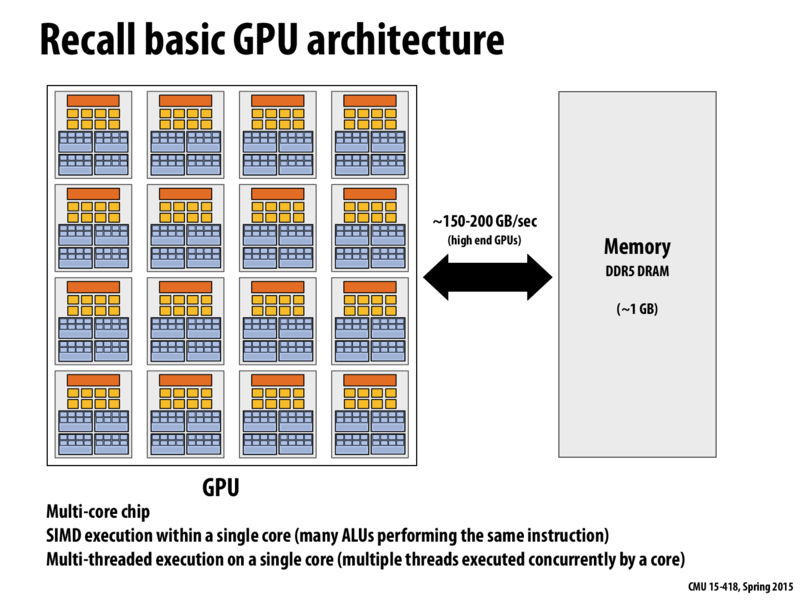
Can someone elaborate on how SIMD and multi-threaded execution work together on a single core in GPU? In particular, what does "multi-threaded" imply here?
I believe "multi-threaded" refers to two things here:
1 - Multiple execution contexts maintained on each core. Remember that while each core executes code for a SIMD-width 'warp' or 'wavefront' of threads, multiple warps' execution contexts can be stored, ready to execute on the next instruction. The GPU uses this to perform latency hiding, running multiple warps concurrently (recall concurrently != simultaneously - it may be that only one warp executes at a time, but all are ready to execute).
2 - While #1 above is the key point, it's also worth remembering that GPU code typically implements 'implicit' parallelism in SIMD. That is, you write scalar programs which are then mapped to multiple 'threads' which can each run in a single SIMD lane. So each SIMD 'lane' is usually a separate 'thread' of execution, i.e. a separate instance of a program, which is not the same as using a SIMD intrinsic to perform a small piece of work (like a small bit of vector math) in a single-threaded application. This is crossing the line between hardware architecture and the software abstractions that it (usually) implements, so I think #1 is what Kayvon meant here, but still worth mentioning since the definition of 'thread' here is a little ambiguous.
@fgomezfr: I meant both.
The chip is multi-threaded, like you mention, because it maintains many hardware execution contexts per core.
The chip also is SIMD in that all the work mapped to "lanes" of one execution context execute in parallel using SIMD execution. Or, if you want to think about it in an "implicit SIMD" or "SIMT" manner (which is more applicable on this slide since we are talking about GPUs), it's fair to say an execution context is scalar and that multiple execution contexts are executed together in SIMD fashion.
Thanks for the explanation! My understanding of the GPU architecture now is:
there is a chip;
on this chip, there are multiple cores that can run simultaneously;
within a core, there are multiple threads/warps which can run concurrently;
within a thread/warp, there are SIMD lanes.
@meatie. Correct.