Does CUDA give any interface to run operations on the "special" SIMD functional units or is that handled by the GPU / compiler.
byeongcp
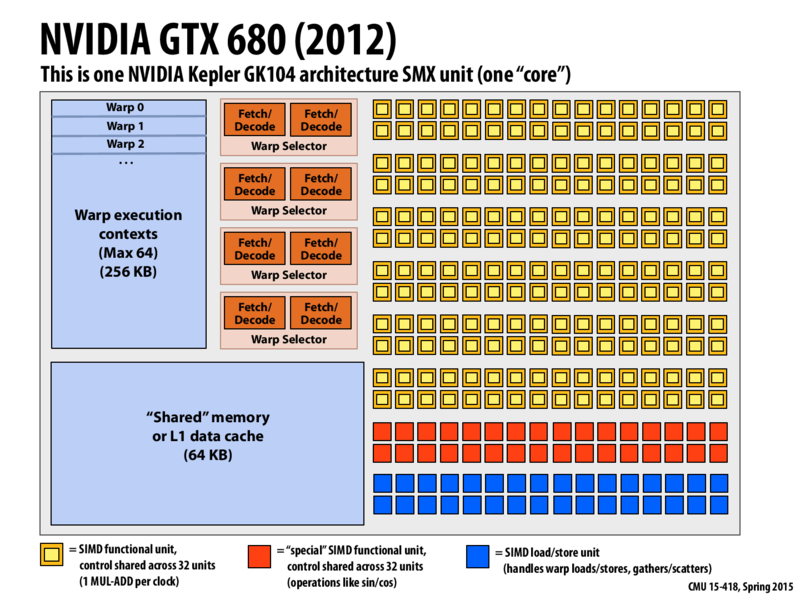
I might've missed this previously, but when I was rewatching the lecture, Kayvon said we can execute 8 instructions per clock if each instruction maps to a combination of 6 arithmetic, 1 load/store, and 1 transcendental. Where does the specific numbers in "6 arithmetic, 1 load/store, and 1 transcendental" come from and why does the instruction have to be combination of them?
HingOn
@byeongcp my understanding is that each unit has 4 warp selectors, and each warp selector dispatch 2 instructions per warp per clock (8 total dispatch units). There are 32 SFU, 32 LD/ST and 192 CUDA threads in each unit. The ratio is 1:1:6, so I am guessing one dispatch unit only dispatches SFU instructions, one only dispatches LD/ST instructions, and six dispatch CUDA threads instructions.
russt17
@byeongcp I believe the 6:1:1 comes from looking at the diagram, the ratio of orange/yellow:red:blue squares is 6:1:1, so if we want to use all of the squares in the diagram that's going to be the ratio
mingf
For this specific GPU, for each core, there are 6 * 32 arithmetic ALUs, 1 * 32 special math ALUs and 1*32 store/load ALUs. The core is able to select up to 4 warps out of 64 warp contexts and fetch up to 2 independent instructions per selected warp. That's at most 8 * 32 SIMD executions. If the 8 decoded instruction streams map to a combination of 6 arithmetic, 1 load/store, and 1 special, we can make full use of the ALUs on the core. Otherwise, it seems that the decoded instruction streams are more than the core can run.
BryceToTheCore
I remember that back when I took 15-150 I learned how to think about types. The way of thinking in that class leads to a programming style of copious thinking per line of code, whereas normal imperative programming seems to have relatively little thinking per line, but many simple instructions need to be combined together to get stuff done.
I think that parallel programming requires a balanced mix of both per line thinking and many lines. As seen in this thread of discussion there is an awful lot of specific information that the programmer needs to think about including block sizes, SIMD-width, etc.
It seems like it would be a bit aggravating if the programmer ever needs to transplant code from one machine to another.
kayvonf
@mingf: very nice work.
msebek
@BryceToTheCore In an earlier lecture, kayvon mentioned an idea of "low abstraction distance", such that CUDA maps onto the hardware in a very straight-forward fashion. This allows the programmers to make decisions based on their knowledge of the code. For most languages, the language is not strong enough to express relationships in such a way that the compiler can reasonably optimize.
Re: transplanting code from system to system, there are whole sets of algorithms that are "cache oblivious", that don't rely on knowing the precise details of the cache size. Predictably, though, in many cases these algorithms do not perform as well as their cache-aware counterparts.
Does CUDA give any interface to run operations on the "special" SIMD functional units or is that handled by the GPU / compiler.
I might've missed this previously, but when I was rewatching the lecture, Kayvon said we can execute 8 instructions per clock if each instruction maps to a combination of 6 arithmetic, 1 load/store, and 1 transcendental. Where does the specific numbers in "6 arithmetic, 1 load/store, and 1 transcendental" come from and why does the instruction have to be combination of them?
@byeongcp my understanding is that each unit has 4 warp selectors, and each warp selector dispatch 2 instructions per warp per clock (8 total dispatch units). There are 32 SFU, 32 LD/ST and 192 CUDA threads in each unit. The ratio is 1:1:6, so I am guessing one dispatch unit only dispatches SFU instructions, one only dispatches LD/ST instructions, and six dispatch CUDA threads instructions.
@byeongcp I believe the 6:1:1 comes from looking at the diagram, the ratio of orange/yellow:red:blue squares is 6:1:1, so if we want to use all of the squares in the diagram that's going to be the ratio
For this specific GPU, for each core, there are 6 * 32 arithmetic ALUs, 1 * 32 special math ALUs and 1*32 store/load ALUs. The core is able to select up to 4 warps out of 64 warp contexts and fetch up to 2 independent instructions per selected warp. That's at most 8 * 32 SIMD executions. If the 8 decoded instruction streams map to a combination of 6 arithmetic, 1 load/store, and 1 special, we can make full use of the ALUs on the core. Otherwise, it seems that the decoded instruction streams are more than the core can run.
I remember that back when I took 15-150 I learned how to think about types. The way of thinking in that class leads to a programming style of copious thinking per line of code, whereas normal imperative programming seems to have relatively little thinking per line, but many simple instructions need to be combined together to get stuff done.
I think that parallel programming requires a balanced mix of both per line thinking and many lines. As seen in this thread of discussion there is an awful lot of specific information that the programmer needs to think about including block sizes, SIMD-width, etc.
It seems like it would be a bit aggravating if the programmer ever needs to transplant code from one machine to another.
@mingf: very nice work.
@BryceToTheCore In an earlier lecture, kayvon mentioned an idea of "low abstraction distance", such that CUDA maps onto the hardware in a very straight-forward fashion. This allows the programmers to make decisions based on their knowledge of the code. For most languages, the language is not strong enough to express relationships in such a way that the compiler can reasonably optimize.
Re: transplanting code from system to system, there are whole sets of algorithms that are "cache oblivious", that don't rely on knowing the precise details of the cache size. Predictably, though, in many cases these algorithms do not perform as well as their cache-aware counterparts.