Graph contraction (in particular, star contraction) is an example that indeed only neighboring information is needed.
For problems that fail the assumption, an extension of this approach might be multi-window sliding, i.e. we can have several (disjoint) intervals of graph data stored in shared memory.
ericwang
Can sliding window approach be used in multiple nodes system for increasing data locality?
Or maybe it is not worthwhile because there would be overhead for maintaining consistency.
rojo
@ericwang From my understanding sliding window on multiple nodes system will definitely be beneficial, But not all system will operate such a way. Perhaps, this mechanism would help if the system is domain specific and it is prior known that sliding widow helps. Perhaps a machine learning algorithm would help in determining this.
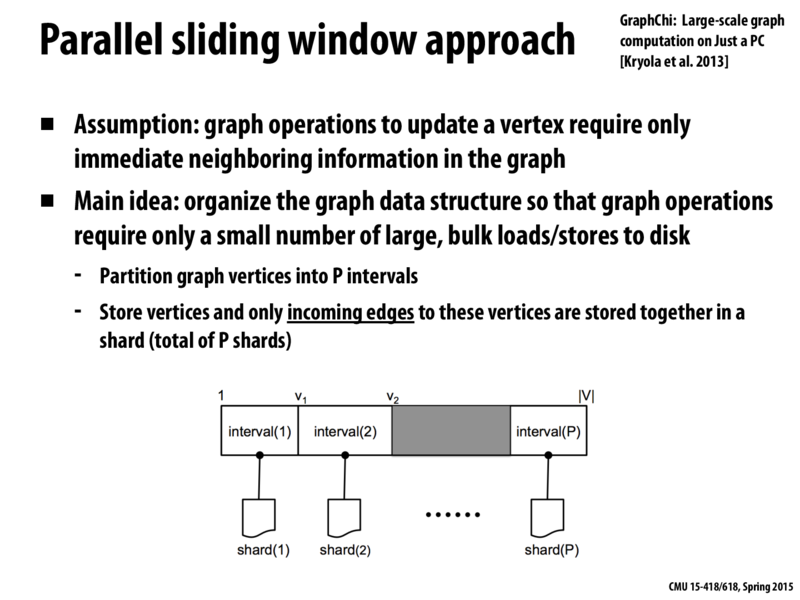
One such scheme is GraphChi that uses sliding window on a single computer, which is described in this paper:
http://select.cs.cmu.edu/publications/paperdir/osdi2012-kyrola-blelloch-guestrin.pdf
Corian
A couple slides ago it was noted that partitioning a graph is expensive and difficult. Is that still the case here? It seems like having a distributed system would easily be worth the troubles if we're going to partition anyway.
Graph contraction (in particular, star contraction) is an example that indeed only neighboring information is needed.
For problems that fail the assumption, an extension of this approach might be multi-window sliding, i.e. we can have several (disjoint) intervals of graph data stored in shared memory.
Can sliding window approach be used in multiple nodes system for increasing data locality?
Or maybe it is not worthwhile because there would be overhead for maintaining consistency.
@ericwang From my understanding sliding window on multiple nodes system will definitely be beneficial, But not all system will operate such a way. Perhaps, this mechanism would help if the system is domain specific and it is prior known that sliding widow helps. Perhaps a machine learning algorithm would help in determining this.
One such scheme is GraphChi that uses sliding window on a single computer, which is described in this paper: http://select.cs.cmu.edu/publications/paperdir/osdi2012-kyrola-blelloch-guestrin.pdf
A couple slides ago it was noted that partitioning a graph is expensive and difficult. Is that still the case here? It seems like having a distributed system would easily be worth the troubles if we're going to partition anyway.