One performance cost incurred here (besides more energy usage) is the added latency required to get data to/from the GPU (as we saw in assignment 2). Such a cost is easily amortized if you're sending the GPU sufficiently intensive tasks that it is well suited for. However, one could imagine a workload where having the CPU and GPU share memory could be very beneficial. For instance, if you're computing on the same data that you're rendering (e.g., a large mesh) then having it all happen on one chip could be advantageous (good data locality for both processing units).
vrazdan
Another issue with this is that you need to predict your workload in advance, so that you don't waste energy turning the gpu on and off again (or even just specific hardware components on the gpu).
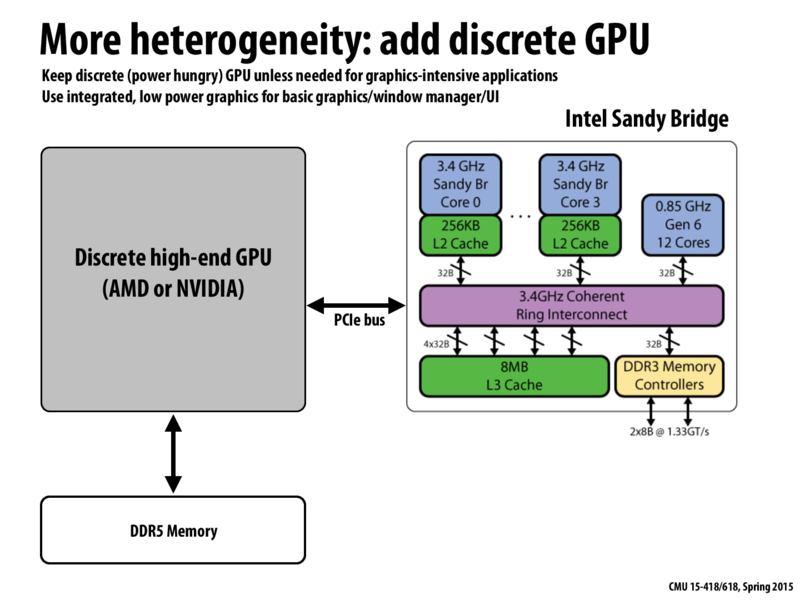
One performance cost incurred here (besides more energy usage) is the added latency required to get data to/from the GPU (as we saw in assignment 2). Such a cost is easily amortized if you're sending the GPU sufficiently intensive tasks that it is well suited for. However, one could imagine a workload where having the CPU and GPU share memory could be very beneficial. For instance, if you're computing on the same data that you're rendering (e.g., a large mesh) then having it all happen on one chip could be advantageous (good data locality for both processing units).
Another issue with this is that you need to predict your workload in advance, so that you don't waste energy turning the gpu on and off again (or even just specific hardware components on the gpu).