So it looks like Dequeue usually has a longer runtime with the lock-free implementation. Does anyone know why this is the case? My guess at least for producer/consumer is that both ends have producers and consumers on them, which makes for more contention.
bwf
Does anyone know what the cause of the "U" shape in the linked list graph is caused by?
uncreative
@bwf The "U" shape seen in the linked-list graph is for the fine-grained locks. I'll try to give a rough explanation of what is going on.
For very few processors, this solution will be worse than just locking the whole data structure, since most of the time, there is no contention at all. So, with only one lock, there is much less overhead than the fine grained locking solution.
At some point there is a moderate amount of contention, and the fine grained locking solution allows more than one processor to modify the data structure at once. This makes it a little bit better than the single lock.
With a high amount of contention, there are many processors attempting to modify the data structure, but almost all of them are waiting for locks. Something like
Node1 -> Node2 -> Node3
PA PB PC
When processor C releases the lock for Node3, processor B grabs it, and releases the lock for Node2. Then processorA grabs the lock for Node2 and releases the lock for Node1. This whole process involves a lot of either spinning, or having the os go find the processor waiting on various locks, and not much gets done.
uncreative
It took me a little bit to figure out what the labels on this graph were, so for anyone else who may be confused.
lf = Lock Free
fg = Fine Grained Locking
The constant line is the time taken by the One Lock for the entire data structure approach.
kayvonf
@rbcarlso. A simple way to think about your question is to consider how much concurrency is possible in a data structure. A stack only allows accesses at one end, so while it's a nice simple example for illustrating lock-free concepts, there's really not much concurrency to be had. (only one thread can be modifying the stack at a time). Ditto for a dequeue, where there really are only two modifications (one on each end) that can happen at the same time. This means that in most of these cases, a coarse-grained lock solution really isn't that much worse that the maximum possible concurrency, and so mutual exclusion can be better than an optimistic lock-free implementation which might do some work and then have to throw it away when the compare_and_swap fails (which becomes increasingly more likely to occur under heavy contention).
However, for a linked list, there's A LOT of concurrency to be had. The lock-free implementation gives you that concurrency where as a coarse lock would not.
yuel1
I wonder what the performance comparison between operations on a lock-free data structure and operations involving transational memory look like, given my understanding that transactional memory also allows the system as a whole to make progress, which I guess makes it lock-free as well? I'm confused...
It seems that when there are a lot of threads, lock-free is a better choice. But since lock-free data structure make use of while loop to make sure the algorithm correct, it will make the CPU busy. Does it means that it will waste a lot of CPU resources when compared with the lock based implementation which will make OS switch out the process?
gryffolyon
@ESINNG, I do not see it as wasting the CPU time. Remember in each iteration, we recalculate the state (old value or old head etc) so our states are getting more and more dynamic and we try to complete our operation atomically with this new state hoping we don't get interleaved in between the time we calculate the old state and make an update. If we do, we go back to calculating the state again and try again. This is much different that busy looping on a while loop while the lock becomes available where we waste CPU. Here we are trying to gain progress. The worst thing that can hit us here is starvation. A thread can fail each time and may have to do these calculations endlessly based on OS scheduling. But we always ensure there is good progress here all the time.
yuel1
@gryffolyon I wonder if this would cause problems on an oversubscribed system. Say you have a bunch of processes that are spinning on a lock, ideally we want the owner of the lock to run without being context switched out. With a bunch of processes testing the lock condition and updating it, we might swap out the process that owns the lock, halting the overall progress of the system.
gryffolyon
@yuel1, yes it would be the case if we use a lock. But we have no locking mechanism here as to what I was referring. We have a CAS or something of that nature when we do it lock free. So there wont be an owner of the lock as such.
yuel1
@gryffolyon Although it doesn't explicitly hold a "lock", it has exclusive access to some resource, and we want it to be done with the resource as soon as possible, hence we ideally don't want it to ever get swapped out.
gryffolyon
@yuel1, I am not quite sure what critical resource it will hold as all we do is a CAS. Either the thread succeeds or its doesn't. If it doesn't, it tries again. But it does not share any critical resource with other threads.
ESINNG
@gryffolyon, suppose I have several processes running on a machine, and one process has many threads and race to access the lock-free data structure. As we know, only one will do the operation like push or pop at the same time and all others are just running in the loop. If we use lock, then all others will be blocked and may be switched out by OS to let other processes run which can make a better use of the CPU instead of wasting on the while loop.
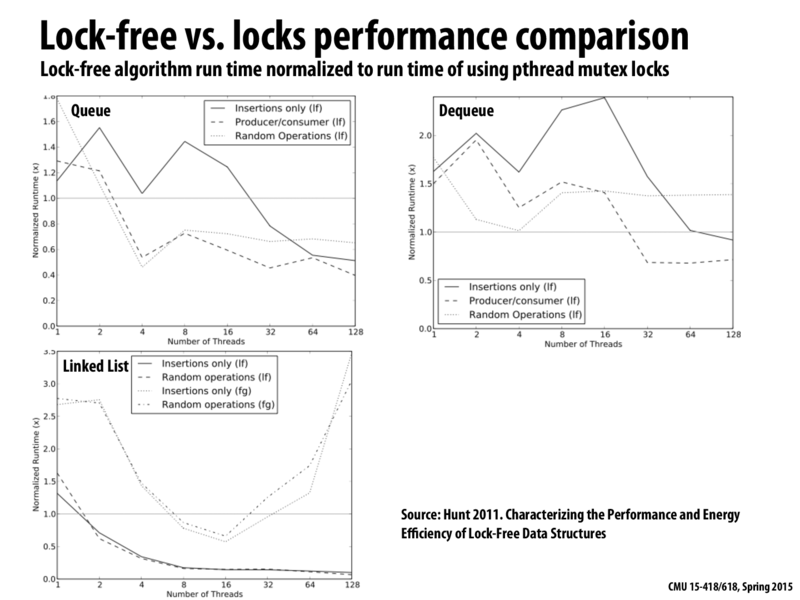
So it looks like Dequeue usually has a longer runtime with the lock-free implementation. Does anyone know why this is the case? My guess at least for producer/consumer is that both ends have producers and consumers on them, which makes for more contention.
Does anyone know what the cause of the "U" shape in the linked list graph is caused by?
@bwf The "U" shape seen in the linked-list graph is for the fine-grained locks. I'll try to give a rough explanation of what is going on.
For very few processors, this solution will be worse than just locking the whole data structure, since most of the time, there is no contention at all. So, with only one lock, there is much less overhead than the fine grained locking solution.
At some point there is a moderate amount of contention, and the fine grained locking solution allows more than one processor to modify the data structure at once. This makes it a little bit better than the single lock.
With a high amount of contention, there are many processors attempting to modify the data structure, but almost all of them are waiting for locks. Something like
When processor C releases the lock for Node3, processor B grabs it, and releases the lock for Node2. Then processorA grabs the lock for Node2 and releases the lock for Node1. This whole process involves a lot of either spinning, or having the os go find the processor waiting on various locks, and not much gets done.
It took me a little bit to figure out what the labels on this graph were, so for anyone else who may be confused.
lf = Lock Free
fg = Fine Grained Locking
The constant line is the time taken by the One Lock for the entire data structure approach.
@rbcarlso. A simple way to think about your question is to consider how much concurrency is possible in a data structure. A stack only allows accesses at one end, so while it's a nice simple example for illustrating lock-free concepts, there's really not much concurrency to be had. (only one thread can be modifying the stack at a time). Ditto for a dequeue, where there really are only two modifications (one on each end) that can happen at the same time. This means that in most of these cases, a coarse-grained lock solution really isn't that much worse that the maximum possible concurrency, and so mutual exclusion can be better than an optimistic lock-free implementation which might do some work and then have to throw it away when the
compare_and_swapfails (which becomes increasingly more likely to occur under heavy contention).However, for a linked list, there's A LOT of concurrency to be had. The lock-free implementation gives you that concurrency where as a coarse lock would not.
I wonder what the performance comparison between operations on a lock-free data structure and operations involving transational memory look like, given my understanding that transactional memory also allows the system as a whole to make progress, which I guess makes it lock-free as well? I'm confused...
Transactional memory is a type of lock free synchronization itself as it involves no locks at all. You might be interested in reading this Transactional Memory:Architectural Support for Lock-Free Data Structures
It seems that when there are a lot of threads, lock-free is a better choice. But since lock-free data structure make use of while loop to make sure the algorithm correct, it will make the CPU busy. Does it means that it will waste a lot of CPU resources when compared with the lock based implementation which will make OS switch out the process?
@ESINNG, I do not see it as wasting the CPU time. Remember in each iteration, we recalculate the state (old value or old head etc) so our states are getting more and more dynamic and we try to complete our operation atomically with this new state hoping we don't get interleaved in between the time we calculate the old state and make an update. If we do, we go back to calculating the state again and try again. This is much different that busy looping on a while loop while the lock becomes available where we waste CPU. Here we are trying to gain progress. The worst thing that can hit us here is starvation. A thread can fail each time and may have to do these calculations endlessly based on OS scheduling. But we always ensure there is good progress here all the time.
@gryffolyon I wonder if this would cause problems on an oversubscribed system. Say you have a bunch of processes that are spinning on a lock, ideally we want the owner of the lock to run without being context switched out. With a bunch of processes testing the lock condition and updating it, we might swap out the process that owns the lock, halting the overall progress of the system.
@yuel1, yes it would be the case if we use a lock. But we have no locking mechanism here as to what I was referring. We have a CAS or something of that nature when we do it lock free. So there wont be an owner of the lock as such.
@gryffolyon Although it doesn't explicitly hold a "lock", it has exclusive access to some resource, and we want it to be done with the resource as soon as possible, hence we ideally don't want it to ever get swapped out.
@yuel1, I am not quite sure what critical resource it will hold as all we do is a CAS. Either the thread succeeds or its doesn't. If it doesn't, it tries again. But it does not share any critical resource with other threads.
@gryffolyon, suppose I have several processes running on a machine, and one process has many threads and race to access the lock-free data structure. As we know, only one will do the operation like push or pop at the same time and all others are just running in the loop. If we use lock, then all others will be blocked and may be switched out by OS to let other processes run which can make a better use of the CPU instead of wasting on the while loop.