Rendering the circles in Assignment 2 heavily relied upon operating in the correct order. Doing the segments in the wrong order could drastically slow down the program.
kayvonf
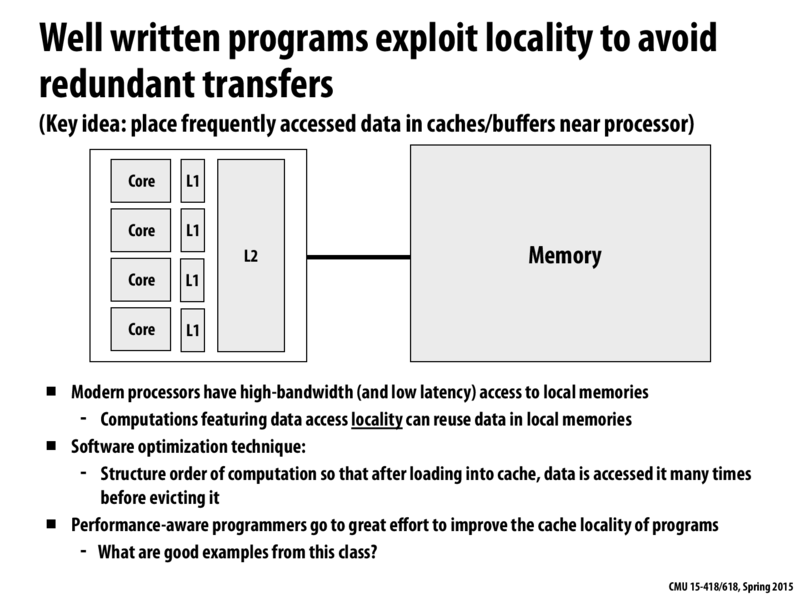
@ekr. But that ordering requirement was for program correctness. In this slide we are asking about examples where the order of iteration in an already correct problem is modified, yielding another equally correct program that exhibits improved data locality.
scedarbaum
An example of this from class is the grid traversals we looked at in lecture 7. Specifically, you generally want to traverse a 2D grid in row-major order (possibly with blocking) if you want to achieve good cache locality. Traversing in any order will give a correct result, but ensuring data is being accessed in a cache-friendly manner will greatly improve performance.
Jing
I am curious what modern compilers are able to do for us in terms of reordering the data for better locality. It seems that it is hard to beat gcc -O3 in my own experience.
kayvonf
@Jing. There is a significant amount of research on globally reordering loops (e.g., tiling, fusion, etc.) to maximize locality, but to my knowledge most of our modern C compilers are not going to attempt these optimizations. Remember the optimizations were talking about here are major project restructurings, like the examples on the next two slides or like the reorderings you implemented in your transpose lab in 15-213. The difference between a good ordering an a bad one in a computation like transpose or matrix multiplication can easily by 100x.
I think this factor is one of prime importance while designing a Domain Specific language/ Compiler. Unlike a general purpose programming languages, DSL compilers have to deal with a very small subset of data access patterns which compilers can be equipped to optimize beautifully.
For example Darkroom drastically reduces DRAM fetches for multi-stage Image processing/ Vision pipelines by line buffering intermediate stages of the pipeline.
jcarchi
Tiling/Blocking is used heavily in making dynamic programming algorithms (which are already quite difficult to parallelize) cache efficient both on single cores and multicores.
Rendering the circles in Assignment 2 heavily relied upon operating in the correct order. Doing the segments in the wrong order could drastically slow down the program.
@ekr. But that ordering requirement was for program correctness. In this slide we are asking about examples where the order of iteration in an already correct problem is modified, yielding another equally correct program that exhibits improved data locality.
An example of this from class is the grid traversals we looked at in lecture 7. Specifically, you generally want to traverse a 2D grid in row-major order (possibly with blocking) if you want to achieve good cache locality. Traversing in any order will give a correct result, but ensuring data is being accessed in a cache-friendly manner will greatly improve performance.
I am curious what modern compilers are able to do for us in terms of reordering the data for better locality. It seems that it is hard to beat gcc -O3 in my own experience.
@Jing. There is a significant amount of research on globally reordering loops (e.g., tiling, fusion, etc.) to maximize locality, but to my knowledge most of our modern C compilers are not going to attempt these optimizations. Remember the optimizations were talking about here are major project restructurings, like the examples on the next two slides or like the reorderings you implemented in your transpose lab in 15-213. The difference between a good ordering an a bad one in a computation like transpose or matrix multiplication can easily by 100x.
Here's an example: http://polly.llvm.org/
I think this factor is one of prime importance while designing a Domain Specific language/ Compiler. Unlike a general purpose programming languages, DSL compilers have to deal with a very small subset of data access patterns which compilers can be equipped to optimize beautifully.
For example Darkroom drastically reduces DRAM fetches for multi-stage Image processing/ Vision pipelines by line buffering intermediate stages of the pipeline.
Tiling/Blocking is used heavily in making dynamic programming algorithms (which are already quite difficult to parallelize) cache efficient both on single cores and multicores.