Reading the 512 bit cache line will take 8 clocks (if counting from the time the first data hits the bus, and assuming a burst transfer mode is used to consecutively read 8 bytes from the active row in each chip). Now consider the case where the processor suffered a cache miss because it tries to read a 4-byte value from memory (1/16 of the cache line). The entire cache line must be transferred into the cache, but can you think of an optimization that reduces the latency of the read if the required work is at the end of the cache line?
ericwang
My first idea is skipping the unnecessary bytes and only read the required bytes into the cache line. So if reading 4 bytes at the end of the line, it just reads the final 8 bytes which cost 1 clock.
But after that, if the cache line is read and other bytes are required, the cache may return wrong value because it didn't actually read those bytes from memory.
So I'm thinking whether it is possible that the first read can start reading from the end and return immediately when the required bytes are ready. Then it continue reading the rest bytes to fill the whole cache line. Or it just discard the incomplete cache line when the request is served, so as to avoid error in later read.
kayvonf
Nice @ericwang. You've independently invented an optimization typically called critical word first! You can see a description in point 3 in these slides.
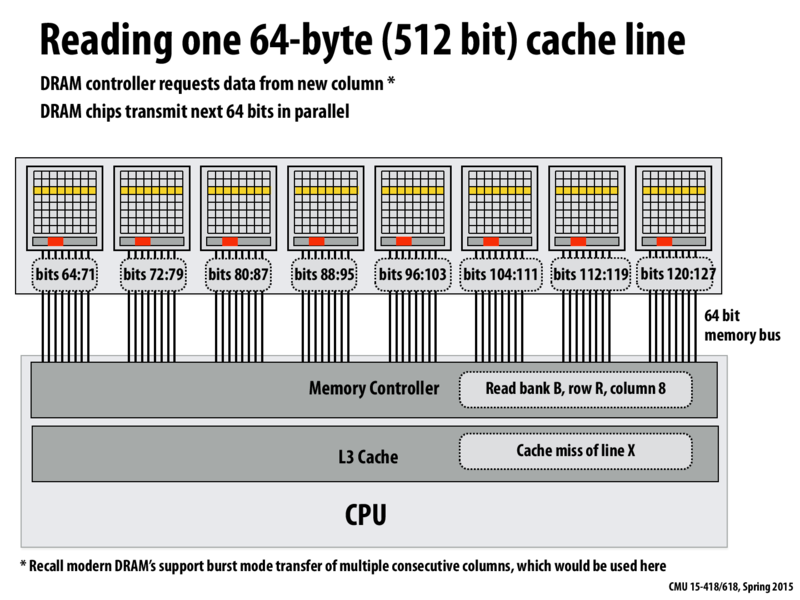
Reading the 512 bit cache line will take 8 clocks (if counting from the time the first data hits the bus, and assuming a burst transfer mode is used to consecutively read 8 bytes from the active row in each chip). Now consider the case where the processor suffered a cache miss because it tries to read a 4-byte value from memory (1/16 of the cache line). The entire cache line must be transferred into the cache, but can you think of an optimization that reduces the latency of the read if the required work is at the end of the cache line?
My first idea is skipping the unnecessary bytes and only read the required bytes into the cache line. So if reading 4 bytes at the end of the line, it just reads the final 8 bytes which cost 1 clock.
But after that, if the cache line is read and other bytes are required, the cache may return wrong value because it didn't actually read those bytes from memory.
So I'm thinking whether it is possible that the first read can start reading from the end and return immediately when the required bytes are ready. Then it continue reading the rest bytes to fill the whole cache line. Or it just discard the incomplete cache line when the request is served, so as to avoid error in later read.
Nice @ericwang. You've independently invented an optimization typically called critical word first! You can see a description in point 3 in these slides.