Question: In class a number of students smartly suggested we use the min or max of all the values in the line as a base. What was one problem with such an approach?
ChandlerBing
One of the problems is that the time needed to do this computation is proportional to the length of the cache line. We want the compression to be as fast as possible.
cube
Also, it's perhaps almost as susceptible to outliers as the "use the first word" approach.
Kapteyn
You could also XNOR the 8 4-byte chunks. The result will be a bit string with a sequence of 1s starting from the most significant digit followed by zeros. Where the 1s end is where the base ends. For example:
00100
00110
00101
xnor =
11100
So then you know your shared base ends at the third most significant digit of any of the 4-byte chunks.
uncreative
So just to test my understanding. This optimization would mostly affect the associativity of the cache, and different sets might have a different associatvity depending on how well the lines in them compressed.
Also, it seems like now we have to compress a line before we can actually determine whether or not it will cause an eviction. This could also give the opportunity for interesting cache eviction policies other than LRU, for instance, we might be interested in evicting lines which were not well compressed even if they were not the least recently used.
abist
@Kapteyn there are many smart solutions but Kayvon said in class that it's ideal that the calculation for the base is not in O(n), and that's why we take the first word because that's O(1)
parallelfifths
The people who suggested min/max are just being good statisticians ;) From a statistical perspective, this makes a ton of sense if we decide, as in the next slide, to use two bases. Assuming the data in the cache line are drawn from a uniform distribution (seems reasonable), the set containing the min and max is the minimal sufficient statistic of the data. But of course statisticians aren't concerned with the time it takes to compute min and max :)
squashme
If the values were 0x0000, 0xAB12, 0xAB34, 0xAB56, 0xAB78, and 0xFFFF, then clearly the min and max are both bad choices for a base. Choosing the min or max takes more time and still doesn't guarantee an optimal result.
rhnil
My first thought in class was to perform bitwise AND on all words to find the base. This approach, similar to the min/max approach, suffers from the problem that the time complexity is linear (or logarithmic if we do some optimization) to the cache line size, which may not be fast enough for hardware. In contrast, the "first word" approach is simple enough to be implemented in hardware and can be perfectly parallelized. So this is a tradeoff between accuracy (finding the best base in a mathematical sense) and efficiency. In practice it is often desirable to work out a fast approximation to handle the average case best.
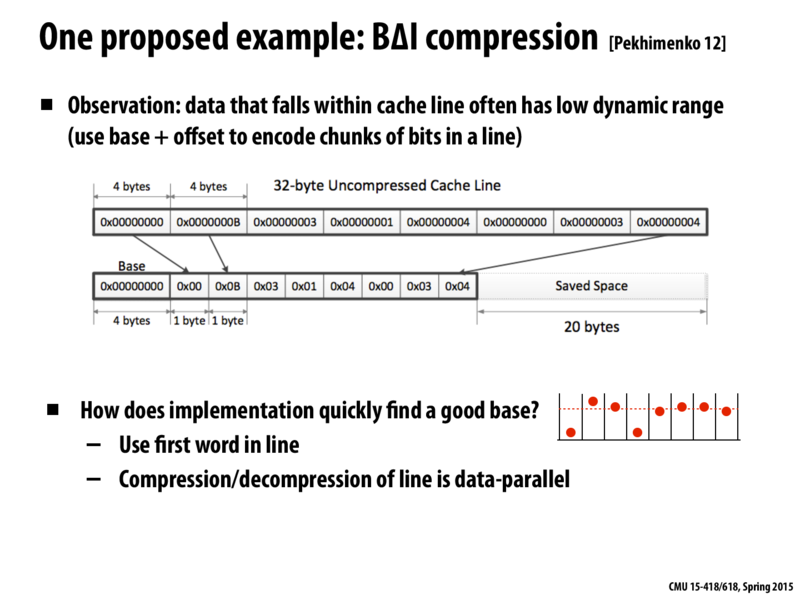
Question: In class a number of students smartly suggested we use the min or max of all the values in the line as a base. What was one problem with such an approach?
One of the problems is that the time needed to do this computation is proportional to the length of the cache line. We want the compression to be as fast as possible.
Also, it's perhaps almost as susceptible to outliers as the "use the first word" approach.
You could also XNOR the 8 4-byte chunks. The result will be a bit string with a sequence of 1s starting from the most significant digit followed by zeros. Where the 1s end is where the base ends. For example:
xnor =
11100
So then you know your shared base ends at the third most significant digit of any of the 4-byte chunks.
So just to test my understanding. This optimization would mostly affect the associativity of the cache, and different sets might have a different associatvity depending on how well the lines in them compressed.
Also, it seems like now we have to compress a line before we can actually determine whether or not it will cause an eviction. This could also give the opportunity for interesting cache eviction policies other than LRU, for instance, we might be interested in evicting lines which were not well compressed even if they were not the least recently used.
@Kapteyn there are many smart solutions but Kayvon said in class that it's ideal that the calculation for the base is not in O(n), and that's why we take the first word because that's O(1)
The people who suggested min/max are just being good statisticians ;) From a statistical perspective, this makes a ton of sense if we decide, as in the next slide, to use two bases. Assuming the data in the cache line are drawn from a uniform distribution (seems reasonable), the set containing the min and max is the minimal sufficient statistic of the data. But of course statisticians aren't concerned with the time it takes to compute min and max :)
If the values were 0x0000, 0xAB12, 0xAB34, 0xAB56, 0xAB78, and 0xFFFF, then clearly the min and max are both bad choices for a base. Choosing the min or max takes more time and still doesn't guarantee an optimal result.
My first thought in class was to perform bitwise AND on all words to find the base. This approach, similar to the min/max approach, suffers from the problem that the time complexity is linear (or logarithmic if we do some optimization) to the cache line size, which may not be fast enough for hardware. In contrast, the "first word" approach is simple enough to be implemented in hardware and can be perfectly parallelized. So this is a tradeoff between accuracy (finding the best base in a mathematical sense) and efficiency. In practice it is often desirable to work out a fast approximation to handle the average case best.