This reminds me of a type of processor instruction called a memory barrier or memory fence. Recall that instruction level parallelism occurs when the processor is able to reorder instructions that maintain correctness in order to execute them in parallel. The processor is able to maintain correctness from the viewpoint of that thread running alone, but not correctness among all the threads running. Sometimes, we want to force the processor to complete memory writes or reads before others in a concurrent setting so that instruction level parallelism does not disrupt the correctness of concurrent code and our code remains correct. In x86, a memory fence (mfence) instruction tells the processor that all memory activity before or after the instruction should not be reordered across the memory fence. This is also a way of expressing dependencies that the processor should respect. There are also load fences (lfence) and store fences (sfence) that tell the processor that only loads or only stores should not be reordered across the fence, providing coarser granularity.
Berry
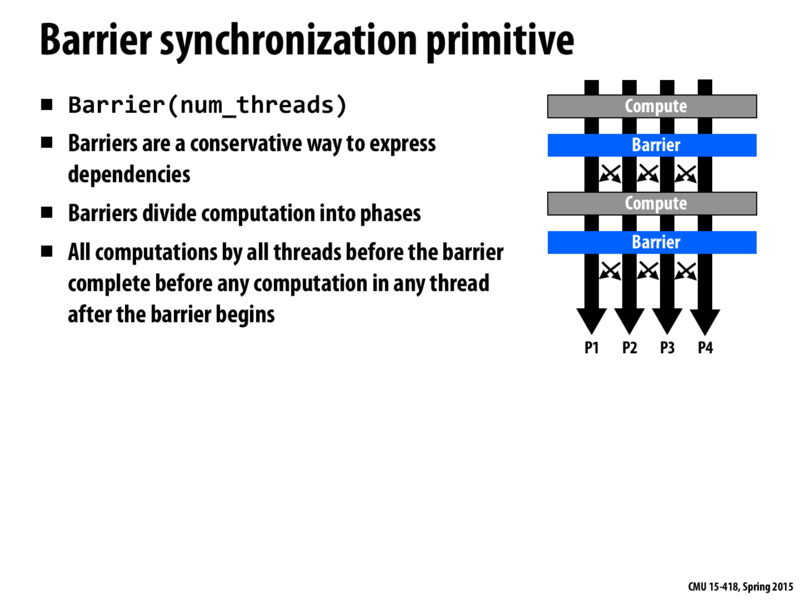
When a thread is blocked by a barrier can it still continue to do other work unrelated to the task at hand and then come back as soon as some flag is raised that that tells it everyone else is done?
scedarbaum
It seems that spawning a bunch of pthreads and waiting for them to terminate (i.e. by spinning in a while loop and joining them) is sort of like a special case of a barrier. Are language/library supported barriers just an abstraction of this or do their implementations' have performance advantages? For instance, instead of the main thread constantly polling the spawned threads to see if they're done (or have reached the barrier point), perhaps the threads could signal the barrier that they've finished.
fgomezfr
@Berry This depends on the compiler's ability to identify what operations after the barrier are independent of the memory operations performed before the barrier. For a multi-core implementation where threads can be executing different parts of the code at different times, you can sometimes achieve this effect yourself with asynchronous programming. For vectorized implementations where all 'threads' move in lockstep, it's not really possible. In a CUDA kernel, for instance, a barrier will block execution of the current warp until all previously-issued memory operations have returned (this warp-only barrier is often inserted automatically for GPU's that use asynchronous DMA's), but will also suspend the warp until all other warps running threads in the same block have reached the same point.
What the compiler will try to do is identify instructions issued after the barrier, which do not depend on memory written to before the barrier. When it sees this, it can simply lift the instruction up before the barrier; in other words, the compiler will try to make sure that threads don't start waiting until they have nothing left to do safely. This is also a cause of headaches when the compiler makes a mistake :)
This reminds me of a type of processor instruction called a memory barrier or memory fence. Recall that instruction level parallelism occurs when the processor is able to reorder instructions that maintain correctness in order to execute them in parallel. The processor is able to maintain correctness from the viewpoint of that thread running alone, but not correctness among all the threads running. Sometimes, we want to force the processor to complete memory writes or reads before others in a concurrent setting so that instruction level parallelism does not disrupt the correctness of concurrent code and our code remains correct. In x86, a memory fence (
mfence) instruction tells the processor that all memory activity before or after the instruction should not be reordered across the memory fence. This is also a way of expressing dependencies that the processor should respect. There are also load fences (lfence) and store fences (sfence) that tell the processor that only loads or only stores should not be reordered across the fence, providing coarser granularity.When a thread is blocked by a barrier can it still continue to do other work unrelated to the task at hand and then come back as soon as some flag is raised that that tells it everyone else is done?
It seems that spawning a bunch of pthreads and waiting for them to terminate (i.e. by spinning in a while loop and joining them) is sort of like a special case of a barrier. Are language/library supported barriers just an abstraction of this or do their implementations' have performance advantages? For instance, instead of the main thread constantly polling the spawned threads to see if they're done (or have reached the barrier point), perhaps the threads could signal the barrier that they've finished.
@Berry This depends on the compiler's ability to identify what operations after the barrier are independent of the memory operations performed before the barrier. For a multi-core implementation where threads can be executing different parts of the code at different times, you can sometimes achieve this effect yourself with asynchronous programming. For vectorized implementations where all 'threads' move in lockstep, it's not really possible. In a CUDA kernel, for instance, a barrier will block execution of the current warp until all previously-issued memory operations have returned (this warp-only barrier is often inserted automatically for GPU's that use asynchronous DMA's), but will also suspend the warp until all other warps running threads in the same block have reached the same point.
What the compiler will try to do is identify instructions issued after the barrier, which do not depend on memory written to before the barrier. When it sees this, it can simply lift the instruction up before the barrier; in other words, the compiler will try to make sure that threads don't start waiting until they have nothing left to do safely. This is also a cause of headaches when the compiler makes a mistake :)