I was wondering what could be other ways to implement "program instances" in this context, apart from SIMD? Maybe SIMD is the implementation which makes most sense, but what could be some other ways?
cube
@ChandlerBing I think it was mentioned in lecture that ISPC defines a gang to run only on one core (mixing abstraction and implementation a little bit), so you'd likely need other ways to have parallelism in that core if you wanted it to run as fast.
kayvonf
For those that asked in class, the specific guarantees on the relative progress of ISPC program instances in a gang is given here.
To attempt a quick answer here to ChandlerBing, we talked in class about hyper-threading where two threads run on one core in parallel, divying up the resources there.
Berry
Just to be clear this gang is running on one core in the same thread as the function that spawned them and the purpose of this gang is to utilize the SIMD vector lanes on that one core? Then the launch keyword in ISCP tells how many gangs we want to spawn across multiple cores, or do these multiple gangs still run on the same core but hide memory latency?
kayvonf
@berry. Excellent post.
Each ISPC task is performed by a single gang of program instances. As you said, the gang is implemented by vector instructions in a single thread, whose state is captured by one execution context of the processor.
If multiple gangs are running at the same time, they are running within different threads. And, of course, a thread needs an execution context to run on a processor.
Said less precisely: yes, different tasks run on different cores.
subliminal
I had a question regarding incompatible gang sizes and SIMD vector-widths. Consider a case where we have 4-wide SIMD instructions supported, but a 8-wide gang size is specified while compiling. We said that the compiler would create two 4-wide SIMD instructions to simulate the 8-wide gang. How would these 2 instructions differ from those created for the same 8 pieces of data by a program compiled for a 4-wide gang? Specifically, for assignment 1 (now that that's over), I saw that the sqrt program gave me worse performance with 8-wide gangs as compared to 4-wide gangs, with both being compiled to sse4 instructions, and the input being one 2.998 and seven 1's. Ideally shouldn't they both be the same? Or does the bad 2.998 mess up the second instruction for the 8-wide gang somehow?
kayvonf
@subliminal. That is an excellent (and certainly true) observation. I think you (or someone else) has the knowledge to answer this question now: "Or does the bad 2.998 mess up the second instruction for the 8-wide gang somehow?"
"mess up" is not very precise. Specifically, what is going to happen in the case you describe, and why would it cause an overall slowdown relative to the non-vectorized sequential version of the code that will only perform exactly the work that is necessary?
landuo
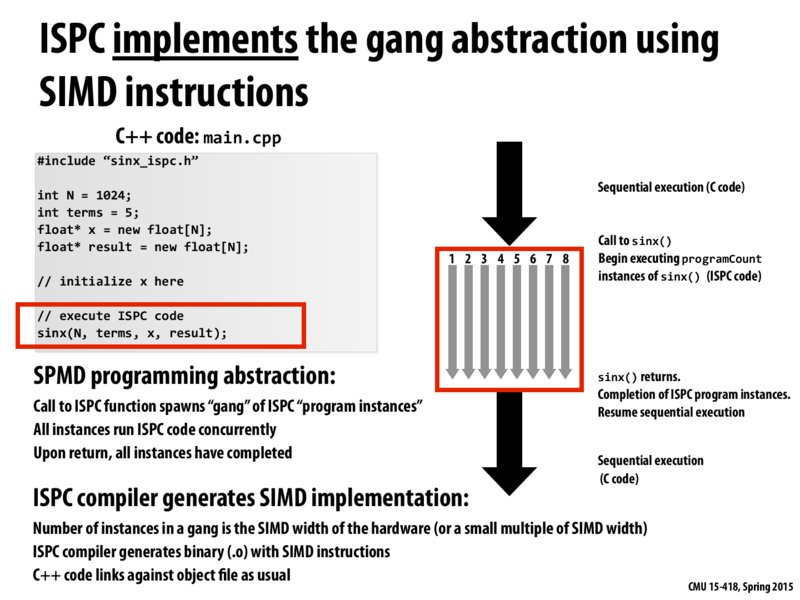
I think this slide is saying that ispc program compile into SIMD instructions like sse or avx based on compiler option (as in assignment 1).So is there any difference between using an ispc program and a sse/avx program? Also, what is the difference between ispc with tasks and sse/avx with OpenMP or Pthreads?
subliminal
@kayvonf, sorry for continuing this so late - what I couldn't understand was the overall slowdown relative to the 4 - wide gang. Divergence causes both the 8-wide and 4-wide gangs to be slower than the non-vectorized sequential version, but I can't understand why they aren't both equally slower, when compiled to 4-wide SIMD.
kayvonf
@subliminal: [Note to everyone, we're talking about assignment 1 here] Consider the case of eight consecutive elements being: 1 1 1 1 1 1 1 2.99.
Let's assume that computing the sqrt(1) takes 1 iteration, and sqrt(2.99) takes 20 iterations.
On a sequential machine, the run time would be 1+1+1+1+1+1+1+20=27.
With a 4-wide gang implemented with 4-wide vectorization, the first 4 elements (1,1,1,1) would trigger one iteration (no divergence). The second four elements (1,1,1,2.99) would trigger 20 iterations so total run time is 21 iterations. (Or course, this is a theoretical argument -- the vectorized version of the code incurs some overhead of extra instructions in it to set/manipulate masks, etc. and so that's why you see a bit of slowdown in practice)
Now, with a 8-wide gang implemented with 4-wide vectorization, each operation in the ISPC program is implemented across the whole gang via two 4-wide vector instructions. That is, running the first iteration for all instances in the gang now takes twice as long. We know the 8-wide gang runs in lockstep, and one of the instances needs 20 iterations, so that means that all eight instances run through those 20 iterations. That means the total cost in run time is 2 * 20 = 40.
This is significantly slower than the 4-wide gang program.
skywalker
@subliminal: How did you run it for 4-wide and 8-wide gangs?? compiler flags...?
@kayvonf:
I have a few statements from my understanding right now - can you let me know if I'm right / correct me otherwise? Ok here goes:
Consider the case that we have 2 cores, each with 2 execution contexts.
In the absence of tasks, our code only creates a single gang even though there are 2 execution contexts available.
A gang of ISPC instances uses a single execution context on a single core only.
Say we have 64 Tasks. Here, we can run only upto 4 tasks at one time. And once any one of them finishes executing, another takes its place. basically they are dynamically scheduled by ISPC.
subliminal
@kayvonf: Thanks! I wasn't sure about how the 8-wide gang would run in lockstep when hardware just gives us a 4-wide SIMD ALU. I'm assuming there'd be an implementation specific barrier at which one set of 4 would be swapped out for the other set of 4 (maintained in a separate context), and this would happen over the 40 iterations.
I'll take a stab at answering your questions, until Kayvon replies:
From the ISPC guide: The gang of program instances starts executing in the same hardware thread and context as the application code that called the ispc function; no thread creation or context switching is done under the covers by ispc.
Since 2 execution contexts would imply 2 hardware threads per core, I guess this would confirm your first 2 points.
For your third point, I was of the opinion that ISPC used the implementation specified tasksys.cpp file to map tasks to thread abstractions (so either the default OS-based implementation or one you specify). The actual scheduling would be done by a combination of the OS and hardware, depending on the system. But the dynamic scheduling method you mentioned would be the way things are done, according to me. Kayvon can probably confirm if this is correct.
kayvonf
@skywalker:
Correct. That's exactly what your program does. A single thread mapped to one hardware thread enters an ISPC function which triggers execution of one gang of program instances. The implementation of running all instances is that the hardware thread starts executing vector instructions.
Correct. (see above)
Yes, the implementation in common/taskSys.cpp will create a pool of four worker threads (which the OS maps to all four execution contexts across the machine). These threads are the "workers" that cooperatively process all the "work" (the set of 64 tasks) by grabbing the next task from the task queue.
I was wondering what could be other ways to implement "program instances" in this context, apart from SIMD? Maybe SIMD is the implementation which makes most sense, but what could be some other ways?
@ChandlerBing I think it was mentioned in lecture that ISPC defines a gang to run only on one core (mixing abstraction and implementation a little bit), so you'd likely need other ways to have parallelism in that core if you wanted it to run as fast.
For those that asked in class, the specific guarantees on the relative progress of ISPC program instances in a gang is given here.
https://ispc.github.io/ispc.html#gang-convergence-guarantees
To attempt a quick answer here to ChandlerBing, we talked in class about hyper-threading where two threads run on one core in parallel, divying up the resources there.
Just to be clear this gang is running on one core in the same thread as the function that spawned them and the purpose of this gang is to utilize the SIMD vector lanes on that one core? Then the launch keyword in ISCP tells how many gangs we want to spawn across multiple cores, or do these multiple gangs still run on the same core but hide memory latency?
@berry. Excellent post.
Each ISPC task is performed by a single gang of program instances. As you said, the gang is implemented by vector instructions in a single thread, whose state is captured by one execution context of the processor.
If multiple gangs are running at the same time, they are running within different threads. And, of course, a thread needs an execution context to run on a processor.
Said less precisely: yes, different tasks run on different cores.
I had a question regarding incompatible gang sizes and SIMD vector-widths. Consider a case where we have 4-wide SIMD instructions supported, but a 8-wide gang size is specified while compiling. We said that the compiler would create two 4-wide SIMD instructions to simulate the 8-wide gang. How would these 2 instructions differ from those created for the same 8 pieces of data by a program compiled for a 4-wide gang? Specifically, for assignment 1 (now that that's over), I saw that the sqrt program gave me worse performance with 8-wide gangs as compared to 4-wide gangs, with both being compiled to sse4 instructions, and the input being one 2.998 and seven 1's. Ideally shouldn't they both be the same? Or does the bad 2.998 mess up the second instruction for the 8-wide gang somehow?
@subliminal. That is an excellent (and certainly true) observation. I think you (or someone else) has the knowledge to answer this question now: "Or does the bad 2.998 mess up the second instruction for the 8-wide gang somehow?"
"mess up" is not very precise. Specifically, what is going to happen in the case you describe, and why would it cause an overall slowdown relative to the non-vectorized sequential version of the code that will only perform exactly the work that is necessary?
I think this slide is saying that ispc program compile into SIMD instructions like sse or avx based on compiler option (as in assignment 1).So is there any difference between using an ispc program and a sse/avx program? Also, what is the difference between ispc with tasks and sse/avx with OpenMP or Pthreads?
@kayvonf, sorry for continuing this so late - what I couldn't understand was the overall slowdown relative to the 4 - wide gang. Divergence causes both the 8-wide and 4-wide gangs to be slower than the non-vectorized sequential version, but I can't understand why they aren't both equally slower, when compiled to 4-wide SIMD.
@subliminal: [Note to everyone, we're talking about assignment 1 here] Consider the case of eight consecutive elements being: 1 1 1 1 1 1 1 2.99.
Let's assume that computing the sqrt(1) takes 1 iteration, and sqrt(2.99) takes 20 iterations.
On a sequential machine, the run time would be 1+1+1+1+1+1+1+20=27.
With a 4-wide gang implemented with 4-wide vectorization, the first 4 elements (1,1,1,1) would trigger one iteration (no divergence). The second four elements (1,1,1,2.99) would trigger 20 iterations so total run time is 21 iterations. (Or course, this is a theoretical argument -- the vectorized version of the code incurs some overhead of extra instructions in it to set/manipulate masks, etc. and so that's why you see a bit of slowdown in practice)
Now, with a 8-wide gang implemented with 4-wide vectorization, each operation in the ISPC program is implemented across the whole gang via two 4-wide vector instructions. That is, running the first iteration for all instances in the gang now takes twice as long. We know the 8-wide gang runs in lockstep, and one of the instances needs 20 iterations, so that means that all eight instances run through those 20 iterations. That means the total cost in run time is 2 * 20 = 40.
This is significantly slower than the 4-wide gang program.
@subliminal: How did you run it for 4-wide and 8-wide gangs?? compiler flags...?
@kayvonf:
I have a few statements from my understanding right now - can you let me know if I'm right / correct me otherwise? Ok here goes:
Consider the case that we have 2 cores, each with 2 execution contexts.
@kayvonf: Thanks! I wasn't sure about how the 8-wide gang would run in lockstep when hardware just gives us a 4-wide SIMD ALU. I'm assuming there'd be an implementation specific barrier at which one set of 4 would be swapped out for the other set of 4 (maintained in a separate context), and this would happen over the 40 iterations.
@skywalker. Yes, you can modify the compiler flags. Here's the reference: ISPC: Selecting the compilation target.
I'll take a stab at answering your questions, until Kayvon replies:
From the ISPC guide: The gang of program instances starts executing in the same hardware thread and context as the application code that called the ispc function; no thread creation or context switching is done under the covers by ispc.
Since 2 execution contexts would imply 2 hardware threads per core, I guess this would confirm your first 2 points.
For your third point, I was of the opinion that ISPC used the implementation specified tasksys.cpp file to map tasks to thread abstractions (so either the default OS-based implementation or one you specify). The actual scheduling would be done by a combination of the OS and hardware, depending on the system. But the dynamic scheduling method you mentioned would be the way things are done, according to me. Kayvon can probably confirm if this is correct.
@skywalker:
common/taskSys.cppwill create a pool of four worker threads (which the OS maps to all four execution contexts across the machine). These threads are the "workers" that cooperatively process all the "work" (the set of 64 tasks) by grabbing the next task from the task queue.