A comment in an earlier lecture (about using python with MPI) got me thinking. We mentioned today in lecture that, for simplicity's sake, programs using ISPC would best be compiled and run on the same machine (to avoid illegal instruction issues, if the wrong target is chosen).
In the case of a language with bytecode, such as java, it seems possible for the JIT to have an opportunity to jump in and vectorize some operations appropriately, if the bytecode generator left behind hints of 'forall' in the bytecode. Having the JVM doing the 'hard stuff', choosing the right instructions for the current machine, could allow code to be portable to an extent as well as vectorized.
Is this an area of research, or is there no audience interested in both bytecode and high performance? Are there other technical barriers?
kayvonf
Absolutely there is. In fact all GPU code that you look at is bytecode (PTX) that is JIT'ted at runtime for the specific GPU platform in question. The PTX-to-machine-code transformation is a lot simpler than the types of operates you're describing above, but it's the same idea.
apoms
Why has static ILP not taken hold in a GPU context? Since the companies that produces GPUs have total vertical control over their stack (hardware, runtime, compiler, language), and even have JIT'ed code at runtime, it seems like an ideal environment for implementing something like VLIW.
Both CUDA and ISPC have similar processing element abstractions: warps for CUDA and gangs for ISPC. One of the unique side effects of these abstractions is that due to their implementation they afford much lower synchronization costs within a gang or warp. This has led to algorithms which are very fast under these models but completely infeasible in others (pthreads, for example, could not implement prefix scan the same way IPSC or CUDA does). In fact, if one implemented the same algorithm using pthreads it would be incorrect due to non-deterministic behavior (pthreads don't operate in lock step like gangs and warps do). Although they are technically exposing the same parallelism, the implementation drastically alters how one writes code for it. How can we write abstractions that make it easy for the programmer to use but also lift the details of the hardware up so that the programmer can adequately reason and state the sorts of information that can allow the compiler to make better decisions?
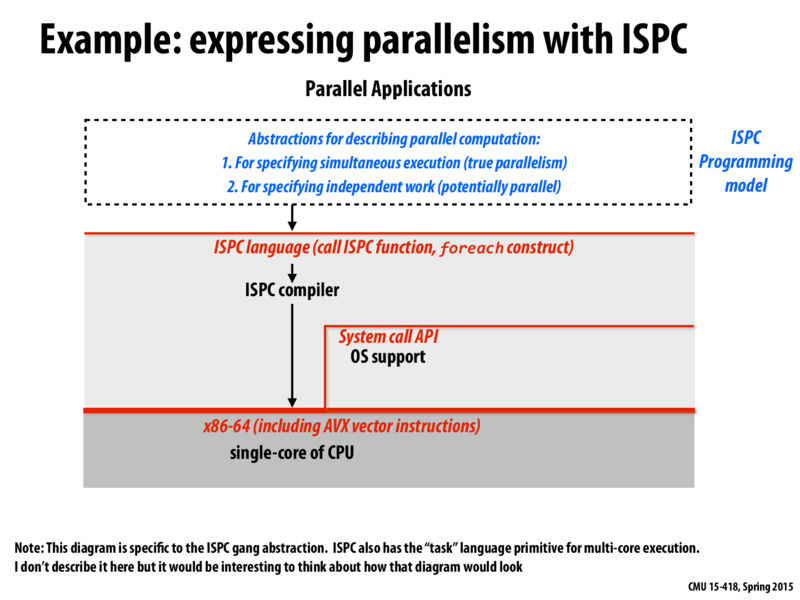
A comment in an earlier lecture (about using python with MPI) got me thinking. We mentioned today in lecture that, for simplicity's sake, programs using ISPC would best be compiled and run on the same machine (to avoid illegal instruction issues, if the wrong target is chosen).
In the case of a language with bytecode, such as java, it seems possible for the JIT to have an opportunity to jump in and vectorize some operations appropriately, if the bytecode generator left behind hints of 'forall' in the bytecode. Having the JVM doing the 'hard stuff', choosing the right instructions for the current machine, could allow code to be portable to an extent as well as vectorized.
Is this an area of research, or is there no audience interested in both bytecode and high performance? Are there other technical barriers?
Absolutely there is. In fact all GPU code that you look at is bytecode (PTX) that is JIT'ted at runtime for the specific GPU platform in question. The PTX-to-machine-code transformation is a lot simpler than the types of operates you're describing above, but it's the same idea.
Why has static ILP not taken hold in a GPU context? Since the companies that produces GPUs have total vertical control over their stack (hardware, runtime, compiler, language), and even have JIT'ed code at runtime, it seems like an ideal environment for implementing something like VLIW.
Both CUDA and ISPC have similar processing element abstractions: warps for CUDA and gangs for ISPC. One of the unique side effects of these abstractions is that due to their implementation they afford much lower synchronization costs within a gang or warp. This has led to algorithms which are very fast under these models but completely infeasible in others (pthreads, for example, could not implement prefix scan the same way IPSC or CUDA does). In fact, if one implemented the same algorithm using pthreads it would be incorrect due to non-deterministic behavior (pthreads don't operate in lock step like gangs and warps do). Although they are technically exposing the same parallelism, the implementation drastically alters how one writes code for it. How can we write abstractions that make it easy for the programmer to use but also lift the details of the hardware up so that the programmer can adequately reason and state the sorts of information that can allow the compiler to make better decisions?