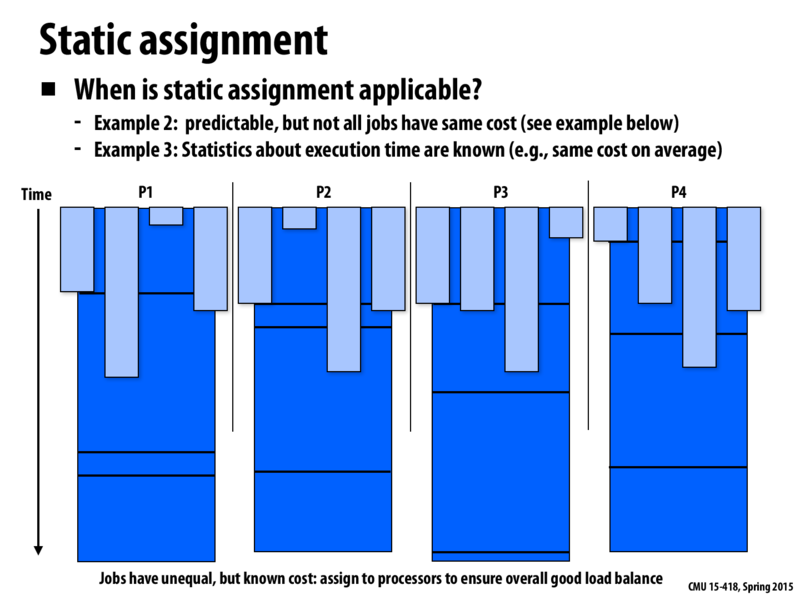
If each of these processors had a warp of four vector lanes, wouldn't this have really poor performance since the tasks are so unequal in length?
dsaksena
What Kayvon meant here was that even with unequal per instance assignment, we on average assign almost equal work.
Particularly Q4 assignment 1, the array was randomly assigned and even if we can't predict the input we can be sure due to its randomness and huge number of values it can be assigned, that the array will end up having almost equal work for all indices.
kayvonf
@ak47. Yes, it's true that if P1-P4 were not unique processors but lanes in a vector unit of a single processor, then assigning work with highly variable execution time to each lane would be a poor idea. However, in most of this lecture, we were talking about assigning work to completely independent worker units, such as separate processor cores.
Of course, if a programmer knew that the workers did not behave independently, and in practice their performance was coupled, for example by sharing an instruction stream or maybe sharing a data cache, then it might be wise for a programmer to consider these characteristics when making assignment decisions.
Sherry
Another proof of you have to understand how hardware works if you care about performance.
Corian
In open MP we had the option of using static when parallelizing for loops and specifying chunk size for number of iterations for each processor. Is the default bucket size when unspecified always 1? I tried using multiples of 2 and always noticed a drop in performance and was wondering why.
fgomezfr
@Corian From the OpenMP documentation I read, the default behavior for static without a chunk-size argument is to divide the entire range of iterations evenly into one consecutive chunk for each thread. If you specify a chunk size, it will instead divide into chunks of that size, and assign them round-robin.
So custom chunk sizes will give you very small additional overheard (basically two for loops instead of one, with some custom indexing). But more importantly, if your chunk size is very small you will encounter cache issues. With chunk size 1, if you are iterating over a contiguous array, threads will alternate elements in the array and need to share all cache lines between all processors! This wouldn't be too bad if you are only reading, but it also means you get less out of your memory transfers, since only 1 of every num_threads bytes read will actually be used. So schedule(static, 1) is quite the opposite of schedule(static) in terms of memory access patterns :)
If each of these processors had a warp of four vector lanes, wouldn't this have really poor performance since the tasks are so unequal in length?
What Kayvon meant here was that even with unequal per instance assignment, we on average assign almost equal work.
Particularly Q4 assignment 1, the array was randomly assigned and even if we can't predict the input we can be sure due to its randomness and huge number of values it can be assigned, that the array will end up having almost equal work for all indices.
@ak47. Yes, it's true that if P1-P4 were not unique processors but lanes in a vector unit of a single processor, then assigning work with highly variable execution time to each lane would be a poor idea. However, in most of this lecture, we were talking about assigning work to completely independent worker units, such as separate processor cores.
Of course, if a programmer knew that the workers did not behave independently, and in practice their performance was coupled, for example by sharing an instruction stream or maybe sharing a data cache, then it might be wise for a programmer to consider these characteristics when making assignment decisions.
Another proof of you have to understand how hardware works if you care about performance.
In open MP we had the option of using static when parallelizing for loops and specifying chunk size for number of iterations for each processor. Is the default bucket size when unspecified always 1? I tried using multiples of 2 and always noticed a drop in performance and was wondering why.
@Corian From the OpenMP documentation I read, the default behavior for static without a chunk-size argument is to divide the entire range of iterations evenly into one consecutive chunk for each thread. If you specify a chunk size, it will instead divide into chunks of that size, and assign them round-robin.
So custom chunk sizes will give you very small additional overheard (basically two for loops instead of one, with some custom indexing). But more importantly, if your chunk size is very small you will encounter cache issues. With chunk size 1, if you are iterating over a contiguous array, threads will alternate elements in the array and need to share all cache lines between all processors! This wouldn't be too bad if you are only reading, but it also means you get less out of your memory transfers, since only 1 of every num_threads bytes read will actually be used. So schedule(static, 1) is quite the opposite of schedule(static) in terms of memory access patterns :)
OpenMP Docs on MSDN scroll to the part on schedules :)