Question: It's reasonable to think about CUDA as an abstract machine with a big task queue. From the perspective of the host-side CUDA API, would it be reasonable to think about a single kernel launch as a task? By default are these "tasks" all dependent or treated as independent?
aznshodan
From what I know, task is work done by the CPU (or the GPU in this case). Since the host is launching a single kernel, meaning relying GPU to do the computation, the host side won't treat the kernel launch as a task;instead the GPU will treat it as a task and distribute it to its worker threads.
I think CUDA treats all of its tasks as independent since we, as programmers, are responsible for launching kernels. By launching kernels, we agree to do that particular computation in parallel because it has no data dependency. If it has data dependency, we as programmers should be responsible and make sure that data are accessed safely using __syncthreads().
parallelfifths
I agree with @aznshodan and would add that CUDA is essentially a data-parallel programming model that expects that a stream of data can go through a flow of kernels that have no dependency structure. CUDA added a __syncthreads() barrier to give the programmer the flexibility to do minor synchronizations (something that is not inherently part of the data-parallel model), but if we rely heavily on synchronizations to take care of dependencies, we lose the data-parallel model benefit of knowing the input/output form of the data for all our kernels.
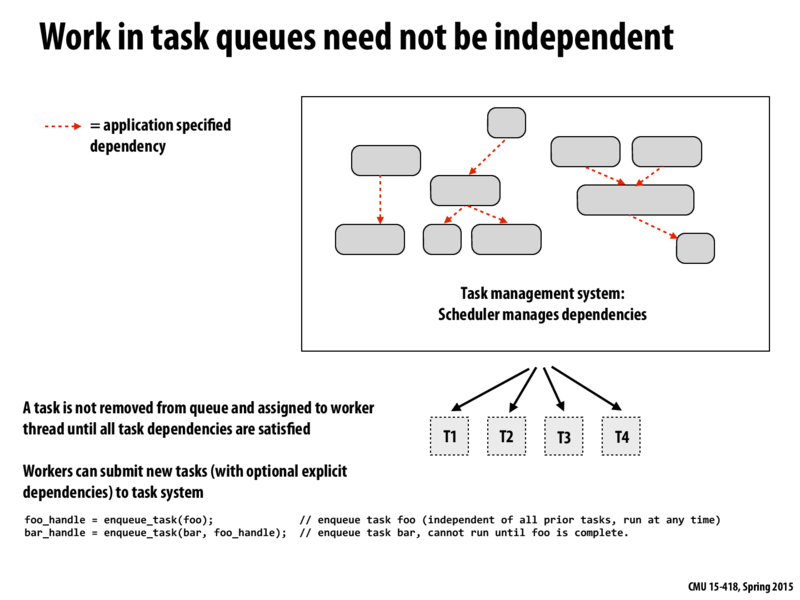
Question: It's reasonable to think about CUDA as an abstract machine with a big task queue. From the perspective of the host-side CUDA API, would it be reasonable to think about a single kernel launch as a task? By default are these "tasks" all dependent or treated as independent?
From what I know, task is work done by the CPU (or the GPU in this case). Since the host is launching a single kernel, meaning relying GPU to do the computation, the host side won't treat the kernel launch as a task;instead the GPU will treat it as a task and distribute it to its worker threads.
I think CUDA treats all of its tasks as independent since we, as programmers, are responsible for launching kernels. By launching kernels, we agree to do that particular computation in parallel because it has no data dependency. If it has data dependency, we as programmers should be responsible and make sure that data are accessed safely using
__syncthreads().I agree with @aznshodan and would add that CUDA is essentially a data-parallel programming model that expects that a stream of data can go through a flow of kernels that have no dependency structure. CUDA added a __syncthreads() barrier to give the programmer the flexibility to do minor synchronizations (something that is not inherently part of the data-parallel model), but if we rely heavily on synchronizations to take care of dependencies, we lose the data-parallel model benefit of knowing the input/output form of the data for all our kernels.