So, I think I have an idea of what a "kernel" is with regard to CUDA programming, but could someone elaborate? It seems to be just the portion of the computation that's heavily parallelizable, but I'm not quite sure if that's right. Is there some sort of history to this terminology, or is it just a convention?
rbcarlso
A kernel is a function that is called from the CPU and is run on the GPU by some number of threads divided into blocks. If that's not a satisfying answer, you might find more in the NVIDIA documentation: here. It defines kernels on page 9.
subliminal
I had a question regarding the correlation of number of warps to block size. Since a warp is the unit of execution on (Nvidia) GPUs, and a warp is defined to have 32 CUDA threads, if a provisioned block cannot be decomposed exactly into an integral number of warps, are the number of warps just rounded up? Is this something that should be kept in mind while defining block sizes? (I apologize if this was discussed in class, can't recall if it was!)
kayvonf
@subliminal. Correct. It will be rounded up, and the remaining threads in the last warp will be always "masked out". That is, the last warp is divergent for the duration of its execution.
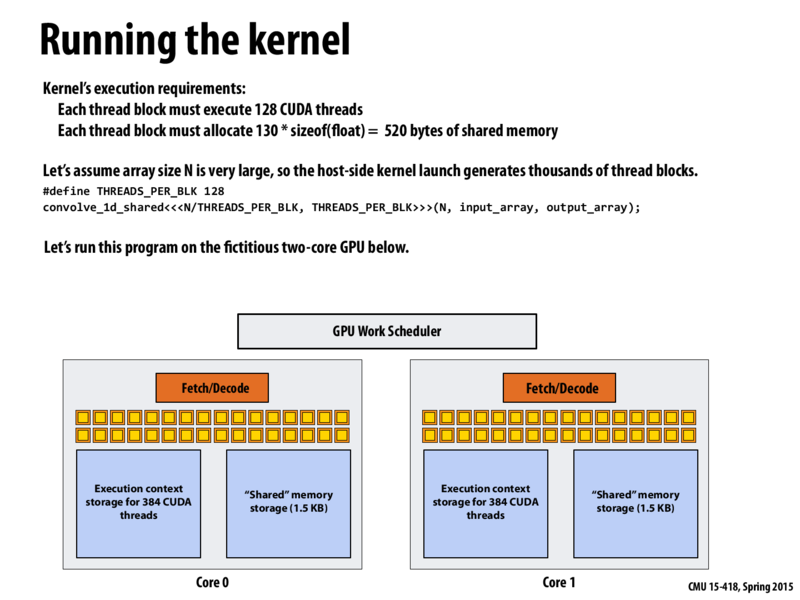
So, I think I have an idea of what a "kernel" is with regard to CUDA programming, but could someone elaborate? It seems to be just the portion of the computation that's heavily parallelizable, but I'm not quite sure if that's right. Is there some sort of history to this terminology, or is it just a convention?
A kernel is a function that is called from the CPU and is run on the GPU by some number of threads divided into blocks. If that's not a satisfying answer, you might find more in the NVIDIA documentation: here. It defines kernels on page 9.
I had a question regarding the correlation of number of warps to block size. Since a warp is the unit of execution on (Nvidia) GPUs, and a warp is defined to have 32 CUDA threads, if a provisioned block cannot be decomposed exactly into an integral number of warps, are the number of warps just rounded up? Is this something that should be kept in mind while defining block sizes? (I apologize if this was discussed in class, can't recall if it was!)
@subliminal. Correct. It will be rounded up, and the remaining threads in the last warp will be always "masked out". That is, the last warp is divergent for the duration of its execution.
Okay, thanks Kayvon!