In my own words: The GPU scheduler now has a set of work, and it begins assigning it to processing resources. Each piece of work specifies how much space it uses in terms of execution contexts and "shared memory"
Hmm, if pieces of work are non-homogenous (say you have 2 kernel launches right after another), it might be possible to end up with a suboptimal configuration. For example, say on a core we have 6 units execution context, and 6 units "shared memory" and we have 2 cores. Job type A uses 2 execution context and 1 shared memory unit. Job type B uses 1 execution context and 2 shared memory units. If we allocate it as
Core 1: AABB
Core 2: AABB
We'll be efficiently using all resources available. But, if we tried say, putting all the same type on one core, we could only fit:
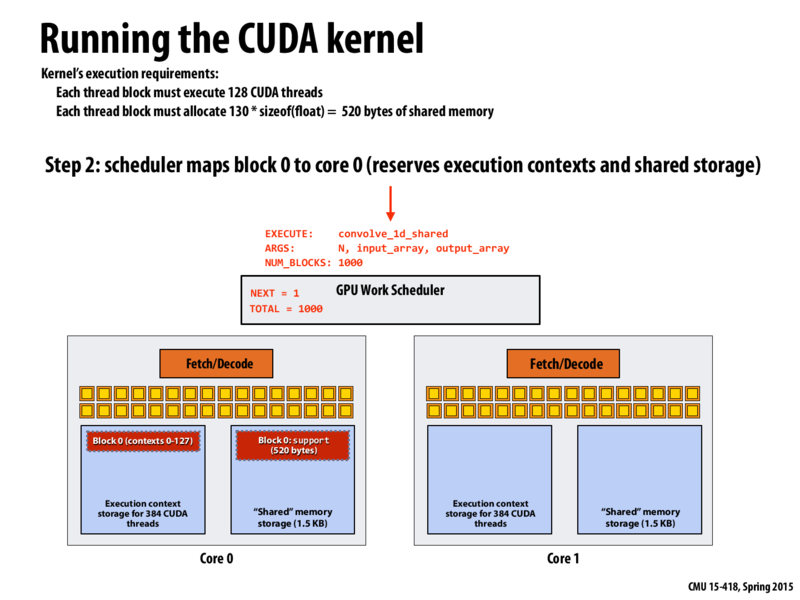
In my own words: The GPU scheduler now has a set of work, and it begins assigning it to processing resources. Each piece of work specifies how much space it uses in terms of execution contexts and "shared memory"
Hmm, if pieces of work are non-homogenous (say you have 2 kernel launches right after another), it might be possible to end up with a suboptimal configuration. For example, say on a core we have 6 units execution context, and 6 units "shared memory" and we have 2 cores. Job type A uses 2 execution context and 1 shared memory unit. Job type B uses 1 execution context and 2 shared memory units. If we allocate it as
Core 1: AABB Core 2: AABB
We'll be efficiently using all resources available. But, if we tried say, putting all the same type on one core, we could only fit:
Core 1: AAA Core 2: BBB