So a warp is all the threads that work within a block? Why was it necessary to describe work with threads that do it rather than the blocks that house it?
ESINNG
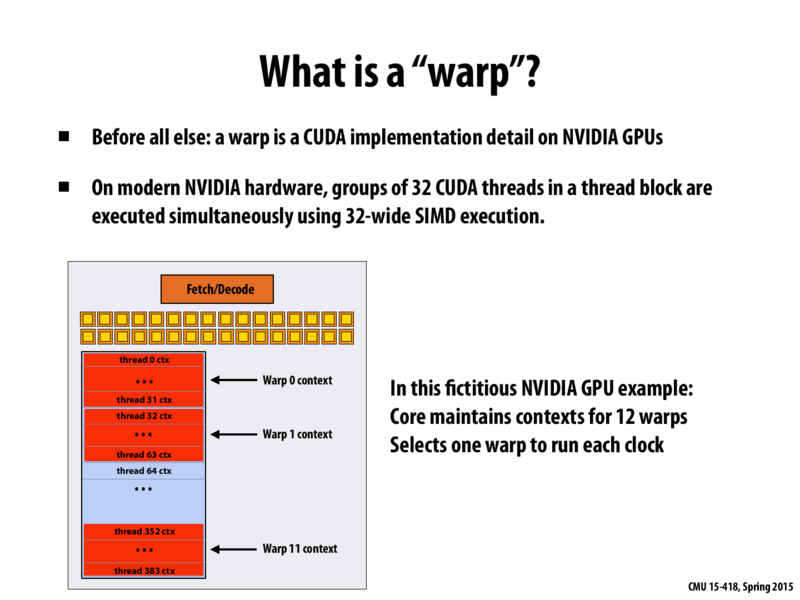
@Berry, I think warp is not all the threads but just, on this case, 32 threads in the block. The threads in a warp can run simultaneously using 32-bit wide SIMD execution. So they are not the same thing.
But I don't know whether my explanation is right. Can anyone give me some comments?
Berry
@ESINNG Ah, that would just make too much sense. Thanks!
VP7
@ESINNG. You are right. But if I say a warp is analogous a threads of execution in case of hardware supported multithread, will it be incorrect?
kayvonf
@VP7, ESINNG: You are correct. Yes, I think it's very fair for a programmer to think of an NVIDIA warp being very similar hardware construct as an x86 execution context (x86 hardware thread). Both correspond to a single instruction steam work of control that's executed in SIMD fashion over a set of SIMD ALUs. With respect to latency hiding, GPU cores schedule warps, they don't schedule individual CUDA threads.
At this point it would be good to go back and look at the discussion of explicit SIMD instructions vs. implicit SIMD execution from slides 34-35 of lecture 2. GPUs use the implicit approach. Just like I illustrated early on slide 46, the GPU receives a command that indicates "run this kernel program N times". (more precisely, that command states run B blocks of this kernel program with T threads per block). If you look at the assembly, the kernel program itself is scalar. There are no vector instructions in it!)
However, given this input, the GPU knows that each CUDA thread it must execute is running the same scalar (non-vector) program, and thus it groups all the threads into warps and shares an instruction stream across the warp. A future NVIDIA GPU could choose to have a different warp size without requiring any recompile of the CUDA programs we've written in this lecture.
Contrast this to how we've expressed programs that use SIMD processing capabilities of CPUs. ISPC generated a program binary with explicit vector instructions in it (SSE instructions, AVX instructions, etc.). Depending on the instructions used, the program explicitly said use 4-wide or 8-wide SIMD processing here. If Intel released a new chip with 16 wide vector instructions (and they have, see AVX512 these programs would need to get recompiled to use the new instructions. Equivalently, if you had written a program using vector intrinsics, you'd have to rewrite the program with new intrinsics to utilize the new SIMD capabilities of the processor.
Of course, if you're not a compiler implementor (or a assembly/intrinsics programmer) and instead use a higher level SPMD programming language like CUDA or ISPC, you need not think about whether the hardware implements SIMD processing using the implicit or explicit approach. Your compiler will translate your SPMD program into whatever input form the target hardware expects.
So while understanding these differences and understanding how programs map to modern hardware is very important and a core concept of this course, hopefully for most of your work you'll be able to use toolchains that abstract these implementation details from application programmers.
kayvonf
Question: AMD GPUs have a similar concept to a warp. What do they call it?
VP7
Wavefront?
kayvonf
@VP7 Yup! And how big is a wavefront? (That might require some digging.)
BTW, here's a nicely detailed article on the architecture of the integrated "Gen 8" GPU in modern Intel CPUs:
Every discussion that I can find claims that the size of a wavefront is 64 threads, double the size of a warp.
VP7
@JuneBot: Looks like 64 is not a number that fits well into the entire range of AMD GPUs.
Open CL programming Guide saysThe size of wavefronts can differ on different GPU compute devices. For example, some of the low-end and older GPUs, such as the AMD Radeon HD54XX series graphics cards, have a wavefront size of 32 work-items. Higher-end and newer AMD GPUs have a wavefront size of 64 work-items.
Also the Appendix D of the guide defines wavefront size as
*(the number of stream cores / by the number of compute units ) X 4
But as a matter of fact the number 64 is good for all GCN hardware.
So a warp is all the threads that work within a block? Why was it necessary to describe work with threads that do it rather than the blocks that house it?
@Berry, I think warp is not all the threads but just, on this case, 32 threads in the block. The threads in a warp can run simultaneously using 32-bit wide SIMD execution. So they are not the same thing. But I don't know whether my explanation is right. Can anyone give me some comments?
@ESINNG Ah, that would just make too much sense. Thanks!
@ESINNG. You are right. But if I say a warp is analogous a threads of execution in case of hardware supported multithread, will it be incorrect?
@VP7, ESINNG: You are correct. Yes, I think it's very fair for a programmer to think of an NVIDIA warp being very similar hardware construct as an x86 execution context (x86 hardware thread). Both correspond to a single instruction steam work of control that's executed in SIMD fashion over a set of SIMD ALUs. With respect to latency hiding, GPU cores schedule warps, they don't schedule individual CUDA threads.
At this point it would be good to go back and look at the discussion of explicit SIMD instructions vs. implicit SIMD execution from slides 34-35 of lecture 2. GPUs use the implicit approach. Just like I illustrated early on slide 46, the GPU receives a command that indicates "run this kernel program N times". (more precisely, that command states run B blocks of this kernel program with T threads per block). If you look at the assembly, the kernel program itself is scalar. There are no vector instructions in it!)
However, given this input, the GPU knows that each CUDA thread it must execute is running the same scalar (non-vector) program, and thus it groups all the threads into warps and shares an instruction stream across the warp. A future NVIDIA GPU could choose to have a different warp size without requiring any recompile of the CUDA programs we've written in this lecture.
Contrast this to how we've expressed programs that use SIMD processing capabilities of CPUs. ISPC generated a program binary with explicit vector instructions in it (SSE instructions, AVX instructions, etc.). Depending on the instructions used, the program explicitly said use 4-wide or 8-wide SIMD processing here. If Intel released a new chip with 16 wide vector instructions (and they have, see AVX512 these programs would need to get recompiled to use the new instructions. Equivalently, if you had written a program using vector intrinsics, you'd have to rewrite the program with new intrinsics to utilize the new SIMD capabilities of the processor.
Of course, if you're not a compiler implementor (or a assembly/intrinsics programmer) and instead use a higher level SPMD programming language like CUDA or ISPC, you need not think about whether the hardware implements SIMD processing using the implicit or explicit approach. Your compiler will translate your SPMD program into whatever input form the target hardware expects.
So while understanding these differences and understanding how programs map to modern hardware is very important and a core concept of this course, hopefully for most of your work you'll be able to use toolchains that abstract these implementation details from application programmers.
Question: AMD GPUs have a similar concept to a warp. What do they call it?
Wavefront?
@VP7 Yup! And how big is a wavefront? (That might require some digging.)
BTW, here's a nicely detailed article on the architecture of the integrated "Gen 8" GPU in modern Intel CPUs:
The Compute Architecture of Intel Processor Graphics Gen 8
Every discussion that I can find claims that the size of a wavefront is 64 threads, double the size of a warp.
@JuneBot: Looks like 64 is not a number that fits well into the entire range of AMD GPUs.
Open CL programming Guide says The size of wavefronts can differ on different GPU compute devices. For example, some of the low-end and older GPUs, such as the AMD Radeon HD54XX series graphics cards, have a wavefront size of 32 work-items. Higher-end and newer AMD GPUs have a wavefront size of 64 work-items.
Also the Appendix D of the guide defines wavefront size as
*(the number of stream cores / by the number of compute units ) X 4
But as a matter of fact the number 64 is good for all GCN hardware.