For the above approach, how to choose an appropriate N? If the N is small, the reduction of contention is also small thus we cannot get a obvious speedup. But if we choose a very big N, we may run out of memory or we only get very limited memory left after we store N grids of lists, which will reduce the parallelism.
kayvonf
@cgjdemo. Larger N also increases the extra work that must be done to combine the results. In practice, empirical testing is probably the most honest answer for how to choose N.
kayvonf
Question: How is this solution strategy similar to the idea employed when optimizing the barrier synchronization in the shared-address space grid solver example?
cacay
@kayvonf In barrier sync, we duplicated the shared variable diff to allow some flexibility with synchronization. Here, the entire grid is the shared variable. We do not have explicit barriers across threads but locks that guard a single value.
kayvonf
@cacay: but there's a strong unifying idea in both this example solution strategy and the barrier removal from the example here. Anyone care to point out what I'm thinking of?
cgjdemo
@kayvonf I think the unifying idea for both cases is that there is no dependencies among different work decompositions therefore we get better parallelism.
In the barrier synchronization example, one thread does not need to wait until all other threads finish checking convergence. In the above example, each partial grid is independent of other partial grids.
BigFish
@kayvonf, I think the unifying idea is to let each thread working on its own part without communicating with other threads by storing their result on local variables and merge the result at last.
kayvonf
@BigFish. I agree! Both examples use duplication of data to remove a dependency on the shared data.
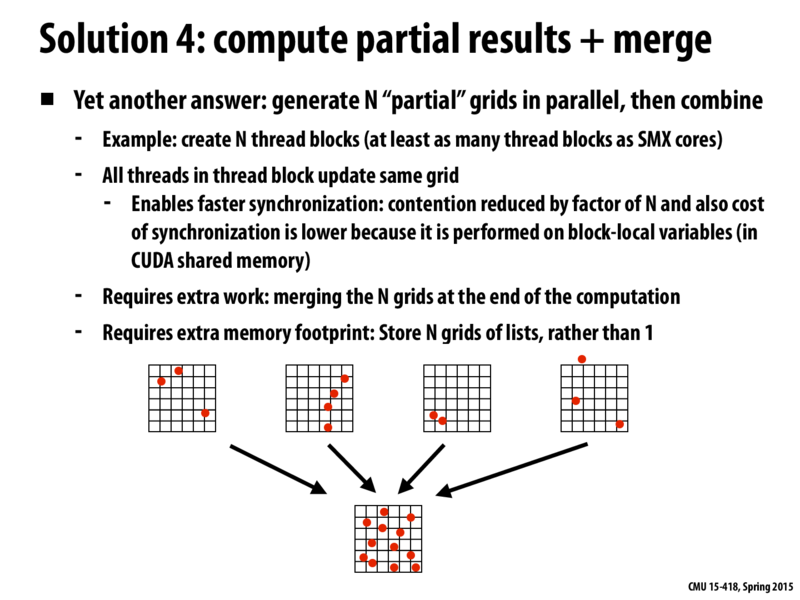
For the above approach, how to choose an appropriate N? If the N is small, the reduction of contention is also small thus we cannot get a obvious speedup. But if we choose a very big N, we may run out of memory or we only get very limited memory left after we store N grids of lists, which will reduce the parallelism.
@cgjdemo. Larger
Nalso increases the extra work that must be done to combine the results. In practice, empirical testing is probably the most honest answer for how to chooseN.Question: How is this solution strategy similar to the idea employed when optimizing the barrier synchronization in the shared-address space grid solver example?
@kayvonf In barrier sync, we duplicated the shared variable
diffto allow some flexibility with synchronization. Here, the entire grid is the shared variable. We do not have explicit barriers across threads but locks that guard a single value.@cacay: but there's a strong unifying idea in both this example solution strategy and the barrier removal from the example here. Anyone care to point out what I'm thinking of?
@kayvonf I think the unifying idea for both cases is that there is no dependencies among different work decompositions therefore we get better parallelism. In the barrier synchronization example, one thread does not need to wait until all other threads finish checking convergence. In the above example, each partial grid is independent of other partial grids.
@kayvonf, I think the unifying idea is to let each thread working on its own part without communicating with other threads by storing their result on local variables and merge the result at last.
@BigFish. I agree! Both examples use duplication of data to remove a dependency on the shared data.