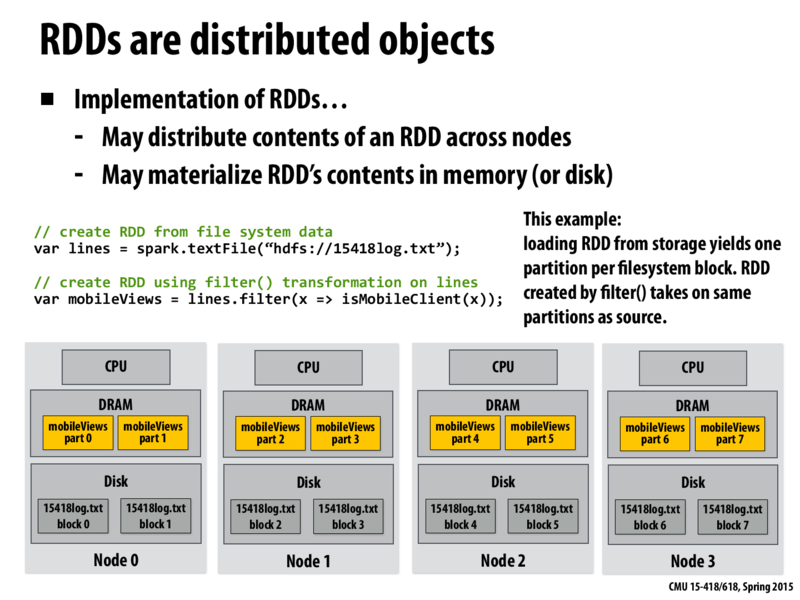
Question: Notice that I used the word "may" twice on this slide. Why didn't I say an RDD "is distributed" or "is materialized"?
Another question: what does materialized mean?
landuo
I think materialized means keeping a snapshot or caching transformation result of RDD. However, according to Zaharia et al., RDD does not always need to be materialized because it has sufficient information of how to compute partitions from data set in stable storage.
The word "may" is used because this is another good example of abstraction vs. implementation.
While we know the Spark implementation of the RDD is based on the Spark distributed system, not making this part of the specification allows the tool creators to be more flexible in how they implement this abstraction. These 'limitations' (though not nearly as extreme as Liszt or Halide) allow the tool creators to optimize the implementation to the platforms that they choose to target.
regi
While sometimes it may be convenient to materialize or store an intermediate value of an RDD, it is not always practical (e.g. for extremely large datasets). Similarly, there is a tradeoff for distributing contents. It may be simpler to keep all of a small RDD on a single node to avoid communication overhead.
haodongl
@regi agreed. Whether the content should be distributed/materialized depends on practical situations, and this allows platform specific optimization.
Question: Notice that I used the word "may" twice on this slide. Why didn't I say an RDD "is distributed" or "is materialized"?
Another question: what does materialized mean?
I think materialized means keeping a snapshot or caching transformation result of RDD. However, according to Zaharia et al., RDD does not always need to be materialized because it has sufficient information of how to compute partitions from data set in stable storage.
https://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf
The word "may" is used because this is another good example of abstraction vs. implementation.
While we know the Spark implementation of the RDD is based on the Spark distributed system, not making this part of the specification allows the tool creators to be more flexible in how they implement this abstraction. These 'limitations' (though not nearly as extreme as Liszt or Halide) allow the tool creators to optimize the implementation to the platforms that they choose to target.
While sometimes it may be convenient to materialize or store an intermediate value of an RDD, it is not always practical (e.g. for extremely large datasets). Similarly, there is a tradeoff for distributing contents. It may be simpler to keep all of a small RDD on a single node to avoid communication overhead.
@regi agreed. Whether the content should be distributed/materialized depends on practical situations, and this allows platform specific optimization.