When you think about it, pipes provide a naturally parallel interface. It's even similar to Spark in that things further down in the pipeline will wait until more data shows up, and intermediate computation is passed along instead of being directly written to disk (I'm not quite sure how pipes are implemented though, so maybe there is an intermediate step that I'm missing that makes my analysis incorrect).
rojo
Extending @jezimmer's comment. Unix pipes are implemented using pipe and pipe2 system call whose actual prototype is:
int pipe(int pipefd[2]);
int pipe2(int pipefd[2], int flags);
Here pipefd holds the descriptor for two ends of the pipe (input - pipefd[0] and output - pipefd[1]). Data written to pipefd[1] is buffered by kernel until it is read by read end of a pipe. The communication channel provided by a pipe is a byte stream.
Pipes have a limited capacity. Hence a writing process may block until the reading process starts reading from the buffer and if a process starts reading from empty pipe then it is blocked until data is available.
Based on this understanding I am not quite sure if pipes provide a naturally parallel interface as processes are blocked on reading or writing data to pipes. Somebody can correct me if I am wrong.
jezimmer
I guess what I meant by "naturally parallel" (admittedly, I was stumbling over my words when I wrote it) was that using pipes is a very easy way to introduce parallelism. The shell execs each program in its own process. Since command line programs are generally small and composable, you can have one process working on reading the data while another process is running an awk script to compute some simple arithmetic.
kayvonf
He te te.
"We made a case for the importance of single-node enhancements
for cost and power efficiency in large-scale behavioral
data analysis. Single node performance of the BID
Data suite on several common benchmarks is faster than
generic cluster systems (Hadoop, Spark) with 50-100 nodes
and competitive with custom cluster implementations for
specific algorithms."
@jezimmer, I think pipes could be seen to implement "pipeline parallelism". One process A produces data, and once there's a good buffer, B can consume data as it's generated, in parallel.
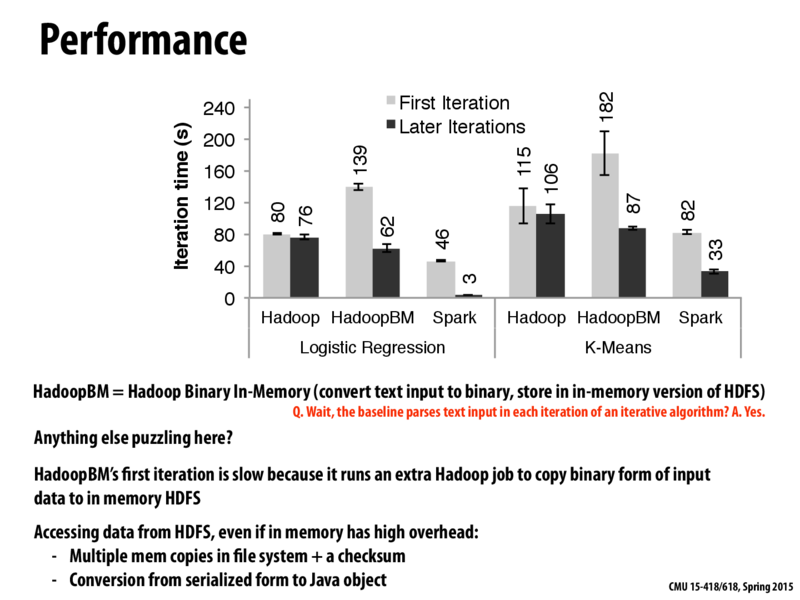
Talk of the performance of Hadoop in class today reminded me of an article I read once regarding Hadoop vs standard Unix commands and pipes:
http://aadrake.com/command-line-tools-can-be-235x-faster-than-your-hadoop-cluster.html
When you think about it, pipes provide a naturally parallel interface. It's even similar to Spark in that things further down in the pipeline will wait until more data shows up, and intermediate computation is passed along instead of being directly written to disk (I'm not quite sure how pipes are implemented though, so maybe there is an intermediate step that I'm missing that makes my analysis incorrect).
Extending @jezimmer's comment. Unix pipes are implemented using pipe and pipe2 system call whose actual prototype is:
int pipe(int pipefd[2]);
int pipe2(int pipefd[2], int flags);
Here pipefd holds the descriptor for two ends of the pipe (input - pipefd[0] and output - pipefd[1]). Data written to pipefd[1] is buffered by kernel until it is read by read end of a pipe. The communication channel provided by a pipe is a byte stream.
Pipes have a limited capacity. Hence a writing process may block until the reading process starts reading from the buffer and if a process starts reading from empty pipe then it is blocked until data is available.
Based on this understanding I am not quite sure if pipes provide a naturally parallel interface as processes are blocked on reading or writing data to pipes. Somebody can correct me if I am wrong.
I guess what I meant by "naturally parallel" (admittedly, I was stumbling over my words when I wrote it) was that using pipes is a very easy way to introduce parallelism. The shell
execs each program in its own process. Since command line programs are generally small and composable, you can have one process working on reading the data while another process is running an awk script to compute some simple arithmetic.He te te.
"We made a case for the importance of single-node enhancements for cost and power efficiency in large-scale behavioral data analysis. Single node performance of the BID Data suite on several common benchmarks is faster than generic cluster systems (Hadoop, Spark) with 50-100 nodes and competitive with custom cluster implementations for specific algorithms."
http://eecs.berkeley.edu/~hzhao/papers/BD.pdf
Haha, the war between generic systems and specialized systems has began.
There is also a MapReduce 2.0 called YARN. http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html I feel like a comparison that includes YARN might also be useful. Maybe YARN is capable of achieving results better than SPARK.
@jezimmer, I think pipes could be seen to implement "pipeline parallelism". One process A produces data, and once there's a good buffer, B can consume data as it's generated, in parallel.