Given our earlier lecture on implementing locks, any hypotheses on why the dark blue lines actually go up in these figures?
gryffolyon
@kayvonf, is the reason that as more threads are added on to more cores, essentially everything is serialized and hence the execution time shoots up in comparison to fine grained locking where the contention is relatively lower.
zhiyuany
As the increase of #processor, the cost of parts that are able to parallel decreases to some extent, while the cost of synchronization consistently increases. So we can expect that, with enough #processor, the cost of synchronization shadows the benefit from parallel execution and overall execution time begins increasing. Although we can only see this point of coarse locks in the graph above, we can expect with more #processors, fine locks and TCC will also hit this point and execution time begins increasing.
grose
@gryffolyon It's not explained what this graph is showing exactly, but I'd imagine it's just timing code wrapped around the lock and unlock primitives within the graph. If it were wrapped around every operation, I would agree with your answer and explanation. But even otherwise, I think it'd still be the same answer (as I'll explain below)
@kayvonf Is it because of the increased contention on a single locking variable? All the locks we've seen so far are implemented with atomic primitives, which cause more contention because of cache coherence, since they require one processor to go into the Exclusive state, and invalidate other caches.
zhiyuany
I'm curious about which CPU can support transactional memory up to 16 hardware threads. As far as I know, Intel CPUs with TSX have at most 4 cores with hyper-threading, which means there are only 8 hardware threads.
ankit1990
@kayvonf When we are using coarse grain lock, the operations are serialized. As the number of competing threads for the lock increase (with increasing number of processors), the cost of synchronization goes up. If the code block meant to be synchronized is extremely small (and there are a large number of concurrent operations), the effect is more pronounced.
On a side note, I am curious about the nature of coarse lock used to make this comparison. Was this a test-and-set, test-and-test-and-set or something else? I think we should see a lesser increase in runtime with some locks as compared to others.
solovoy
I think the answer by @grose is more accurate, in the sense that more cores will cause more bus traffic when invalidated cores try to reload the memory. The increasing of bus traffic will then slow down the running task, just mentioned in the Not Shown note.
yuel1
@solovoy I'm not sure I agree with that. If we do a test and test and set, the bus traffic will only be reads, as the first test does not try to do a bus upgrade.
Zarathustra
@kayvonf Probably because of all the BusRdX interconnect traffic (if not using test-and-test-and-set), otherwise because of the latency introduced by spinning on locks.
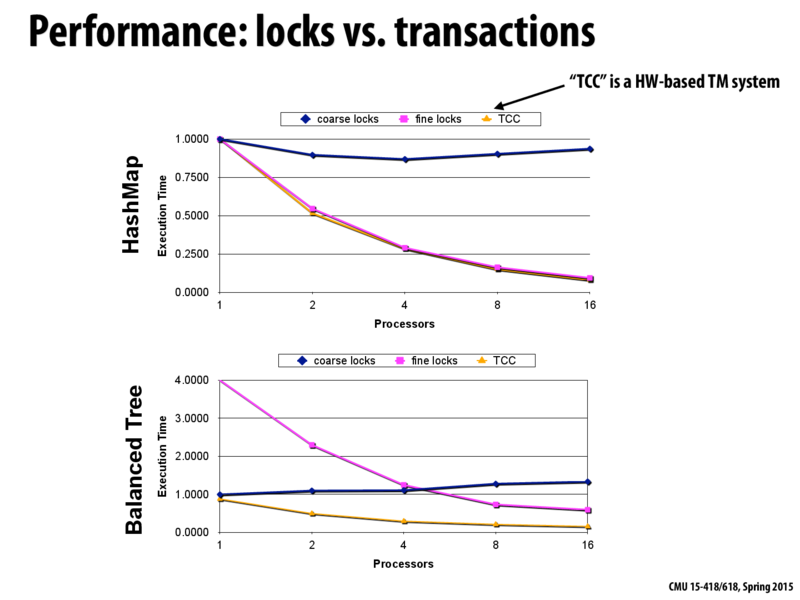
Given our earlier lecture on implementing locks, any hypotheses on why the dark blue lines actually go up in these figures?
@kayvonf, is the reason that as more threads are added on to more cores, essentially everything is serialized and hence the execution time shoots up in comparison to fine grained locking where the contention is relatively lower.
As the increase of #processor, the cost of parts that are able to parallel decreases to some extent, while the cost of synchronization consistently increases. So we can expect that, with enough #processor, the cost of synchronization shadows the benefit from parallel execution and overall execution time begins increasing. Although we can only see this point of coarse locks in the graph above, we can expect with more #processors, fine locks and TCC will also hit this point and execution time begins increasing.
@gryffolyon It's not explained what this graph is showing exactly, but I'd imagine it's just timing code wrapped around the lock and unlock primitives within the graph. If it were wrapped around every operation, I would agree with your answer and explanation. But even otherwise, I think it'd still be the same answer (as I'll explain below)
@kayvonf Is it because of the increased contention on a single locking variable? All the locks we've seen so far are implemented with atomic primitives, which cause more contention because of cache coherence, since they require one processor to go into the Exclusive state, and invalidate other caches.
I'm curious about which CPU can support transactional memory up to 16 hardware threads. As far as I know, Intel CPUs with TSX have at most 4 cores with hyper-threading, which means there are only 8 hardware threads.
@kayvonf When we are using coarse grain lock, the operations are serialized. As the number of competing threads for the lock increase (with increasing number of processors), the cost of synchronization goes up. If the code block meant to be synchronized is extremely small (and there are a large number of concurrent operations), the effect is more pronounced.
On a side note, I am curious about the nature of coarse lock used to make this comparison. Was this a test-and-set, test-and-test-and-set or something else? I think we should see a lesser increase in runtime with some locks as compared to others.
I think the answer by @grose is more accurate, in the sense that more cores will cause more bus traffic when invalidated cores try to reload the memory. The increasing of bus traffic will then slow down the running task, just mentioned in the Not Shown note.
@solovoy I'm not sure I agree with that. If we do a test and test and set, the bus traffic will only be reads, as the first test does not try to do a bus upgrade.
@kayvonf Probably because of all the BusRdX interconnect traffic (if not using test-and-test-and-set), otherwise because of the latency introduced by spinning on locks.