The answer to this question can probably be arbitrarily long, but...
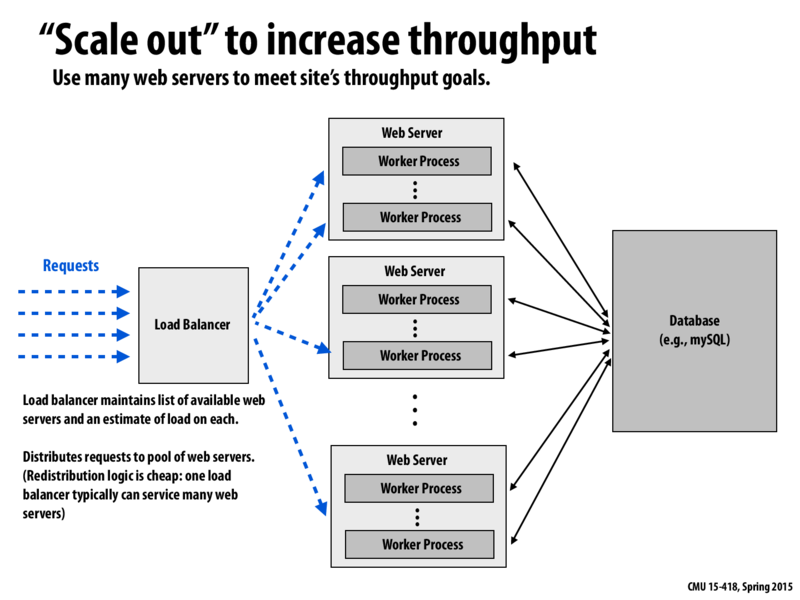
I notice that in this diagram there's only one "database" node. I assume that's a simplification? What are some ways to deal with high demand on the database by workers? We talked about caching later in the lecture, but I assume there's also some aspect of replication...In which case, how would the workers know which replica is the best to communicate with?
jazzbass
@sgbowen You can do sharding. The most simple idea is to split a table into multiple machines, for example instead of having a huge user table, create K tables, one per machine. To know in which database a user is stored, take the id mod(K).
This has several advantages:
Higher availability: If one machine fails, the other machines are still working.
Faster writes: You are parallelizing writes to the DB now (which is usually the bottleneck). Instead of having one huge master, each of the shards do writes in parallel, increasing throughput.
Faster response time: Less data, easier to find what you're looking for.
This idea can be further extended to store different tables in different machines (or columns of a table in different machines).
Another idea is to have read replicas. Writes are bad because they lock tables or several rows of a table. Therefore, when a write is being done, no reads can occur on that row(s). Also this avoid having a bunch of overhead only on the master. Read replicas simply read the DB log of the master node(s) and incorporate those changes gradually into their DBs. You can have a load balancer in front of these read replicas and let the load balancer choose on which replica should you do the read. Notice that we might have consistency problems with read replicas: writes may not show immediately on the replicas.
These ideas are nice but they make your system much more complicated (machine failures, consistency, etc). The general advice is to not to apply them until it is absolutely necessary, but the system should be designed so that it is easy to incorporate these ideas eventually.
Yup, In practice, caching is also heavily used here (Redis vs Memcached). Since MySQL doesn't exactly scale well, companies will try to cache ~90% of the data.
The answer to this question can probably be arbitrarily long, but...
I notice that in this diagram there's only one "database" node. I assume that's a simplification? What are some ways to deal with high demand on the database by workers? We talked about caching later in the lecture, but I assume there's also some aspect of replication...In which case, how would the workers know which replica is the best to communicate with?
@sgbowen You can do sharding. The most simple idea is to split a table into multiple machines, for example instead of having a huge user table, create K tables, one per machine. To know in which database a user is stored, take the id mod(K).
This has several advantages:
Higher availability: If one machine fails, the other machines are still working.
Faster writes: You are parallelizing writes to the DB now (which is usually the bottleneck). Instead of having one huge master, each of the shards do writes in parallel, increasing throughput.
Faster response time: Less data, easier to find what you're looking for.
This idea can be further extended to store different tables in different machines (or columns of a table in different machines).
Another idea is to have read replicas. Writes are bad because they lock tables or several rows of a table. Therefore, when a write is being done, no reads can occur on that row(s). Also this avoid having a bunch of overhead only on the master. Read replicas simply read the DB log of the master node(s) and incorporate those changes gradually into their DBs. You can have a load balancer in front of these read replicas and let the load balancer choose on which replica should you do the read. Notice that we might have consistency problems with read replicas: writes may not show immediately on the replicas.
These ideas are nice but they make your system much more complicated (machine failures, consistency, etc). The general advice is to not to apply them until it is absolutely necessary, but the system should be designed so that it is easy to incorporate these ideas eventually.
Nice answer @jazzbass. Also see slide 17.
Yup, In practice, caching is also heavily used here (Redis vs Memcached). Since MySQL doesn't exactly scale well, companies will try to cache ~90% of the data.