One idea is that we can use one DB for writes and all others replicas of all the data to serve the reads. In this way, we scale out parallelism on the reads. Problem: once a write occurs, the read goes out of date. Then we need to update those read replicas as quick as possible. But this process is a bit relaxed. We tolerate our data to bit a bit stale. Another idea is that instead of replicating the DB, we make our DB distributed. We partition the DB and in this way, we get higher throughput.
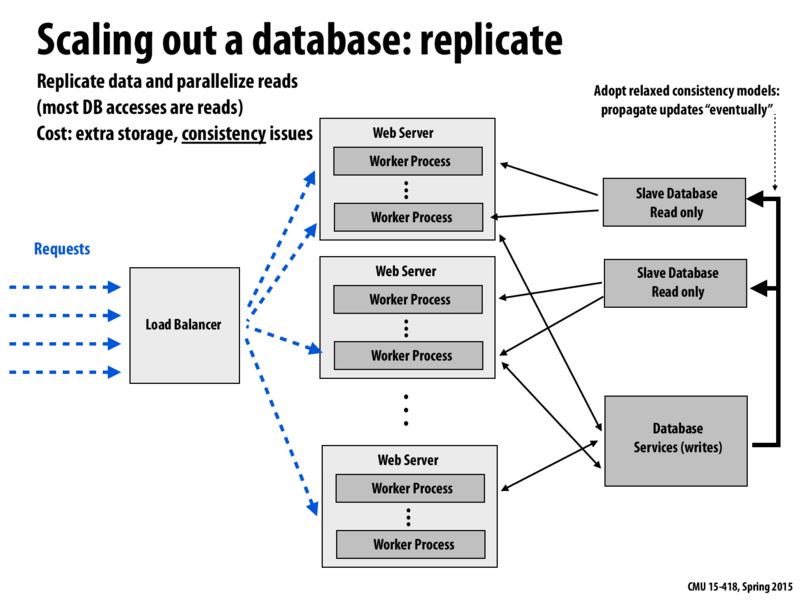
One idea is that we can use one DB for writes and all others replicas of all the data to serve the reads. In this way, we scale out parallelism on the reads. Problem: once a write occurs, the read goes out of date. Then we need to update those read replicas as quick as possible. But this process is a bit relaxed. We tolerate our data to bit a bit stale. Another idea is that instead of replicating the DB, we make our DB distributed. We partition the DB and in this way, we get higher throughput.