First off, why 61 processors? It's neither a power of 2 nor a composite number.
Secondly, compared with Nvidia GPUs that are capable of doing parallel computation which are the benefits of each approach?
kurtmueller42
For your second question, these CPU cores which can handle different types of computation than the cores in a GPU. I don't know too much on this topic (yet :P) but I believe that GPU cores tend to be best at handling non-branching code on shared memory (e.g. you have a big array and you tell your GPU to parallelize doubling each element of the array), which needs to be written in a specific GPU language like CUDA. Someone please correct me if I have these details wrong.
On the other hand, a CPU core can just do arbitrary computation but a CPU has significantly less parallelism than the GPU (even with 61 cores).
I think also since there's all sorts arbitrary computation going on, there would be significantly more effort involved in communicating between the cores.
arjunh
@kurtmueller42 Good answer, we'll be looking at the precise differences between CPU's and GPU's in a few lectures. These differences mostly have to do with:
the compute-models. A CPU is built to execute just a few instructions on a small data-set at a time, while GPU's execute many threads organized in blocks, where threads in each block execute SIMD-style (single-instruction, multiple data; basically, the same instruction is executed across multiple data elements in parallel).
hardware sophistication: a CPU has far more complex hardware, including a sophisticated branch predictor and large caches, while GPU's can't have such resources (mostly owing to the number of execution contexts that are needed to perform the computation on such a large data-set).
overall core 'strength': CPU's generally have larger and faster individual cores than GPU's and can thus perform more complex operations faster, while a GPU's cores are built to perform many simple operations very quickly.
In other words, there is still very much a place for CPU's in today's world, even in the face of the awesome compute-power that GPU's provide. You're not going to see a GPU replacing a CPU's for the purposes of performing all the roles of an OS; that would be an extremely wasteful use of a GPU's resources!
We'll talk more about how CPU's and GPU's can be mixed together to form high-performance chips when we look at heterogenous computing.
mkellogg
In my understanding, threads are grouped into blocks in CUDA, and the GPU groups threads in a block into warps. A single warp can execute only one path of execution (branching path) and only from one block, but it can do so on several threads at a time (32). Threads in a warp that aren't on the active execution path are inactive until the other threads wait for them or finish. Threads in the same block share fast memory. For these reasons blocks should be made such that the path of execution of each thread should be as close as possible to the other threads in the block. Also, the kernels (programs to be run on GPU by CUDA) should be written with minimal branching.
@yuel1 for your first question I googled around but couldn't find anything. Based on the picture, it seems to be 3 rows of 16 cores and then the top row they needed extra room for ((something)) so they could only fit 14 cores.
I'm not sure why it is 61 when I count 62, but I would guess one of the cores is dedicated to something particular process (e.g. coordinating the other cores maybe?) so it doesn't count.
ChandlerBing
I wanted to share an experience about this platform in the context of some concepts from Lecture 3. I worked on the Intel Xeon Phi platform during my undergrad thesis at ETH Zurich.
The Xeon Phi is a shared memory platform with 8GB RAM shared between all the cores, which can be upto 61 in number. The application at hand was implemented as a Kahn Process Network (KPN) - a particular kind of distributed model of computation - which parallelizes the application into processes. The processes then run on different cores of the Xeon Phi in parallel. The shared memory allows to do away the data copying involved in KPNs to a great extent, and was shown to achieve significant performance improvements. Such optimizations cannot be carried out on all multi-core platforms - the Intel’s SCC (Single-Chip Cloud Computer) which uses message passing buffers for communication between its cores is one such example.
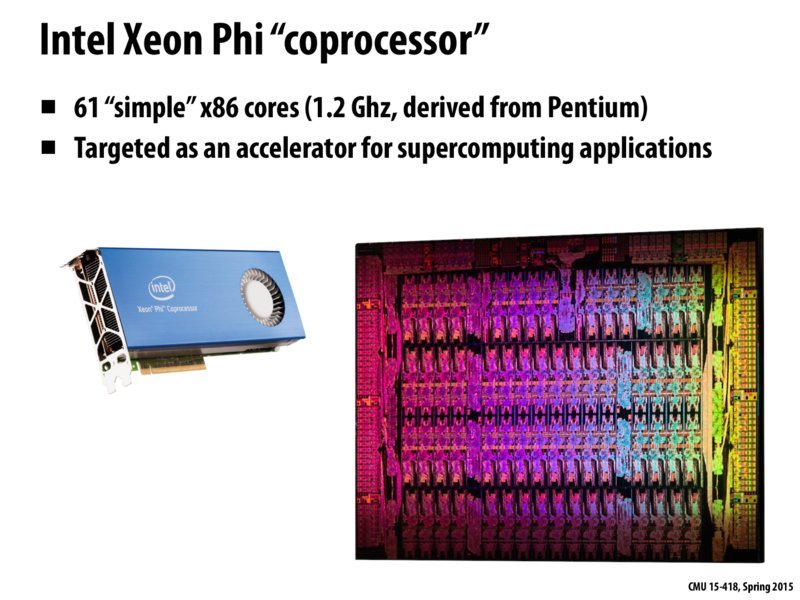
I have two questions regarding this slide.
First off, why 61 processors? It's neither a power of 2 nor a composite number.
Secondly, compared with Nvidia GPUs that are capable of doing parallel computation which are the benefits of each approach?
For your second question, these CPU cores which can handle different types of computation than the cores in a GPU. I don't know too much on this topic (yet :P) but I believe that GPU cores tend to be best at handling non-branching code on shared memory (e.g. you have a big array and you tell your GPU to parallelize doubling each element of the array), which needs to be written in a specific GPU language like CUDA. Someone please correct me if I have these details wrong.
On the other hand, a CPU core can just do arbitrary computation but a CPU has significantly less parallelism than the GPU (even with 61 cores).
I think also since there's all sorts arbitrary computation going on, there would be significantly more effort involved in communicating between the cores.
@kurtmueller42 Good answer, we'll be looking at the precise differences between CPU's and GPU's in a few lectures. These differences mostly have to do with:
In other words, there is still very much a place for CPU's in today's world, even in the face of the awesome compute-power that GPU's provide. You're not going to see a GPU replacing a CPU's for the purposes of performing all the roles of an OS; that would be an extremely wasteful use of a GPU's resources!
We'll talk more about how CPU's and GPU's can be mixed together to form high-performance chips when we look at heterogenous computing.
In my understanding, threads are grouped into blocks in CUDA, and the GPU groups threads in a block into warps. A single warp can execute only one path of execution (branching path) and only from one block, but it can do so on several threads at a time (32). Threads in a warp that aren't on the active execution path are inactive until the other threads wait for them or finish. Threads in the same block share fast memory. For these reasons blocks should be made such that the path of execution of each thread should be as close as possible to the other threads in the block. Also, the kernels (programs to be run on GPU by CUDA) should be written with minimal branching.
More on this can be found here: http://stackoverflow.com/questions/10460742/how-do-cuda-blocks-warps-threads-map-onto-cuda-cores
And here you can find a high-level description of the architecture: https://www.pgroup.com/lit/articles/insider/v2n1a5.htm
@yuel1 for your first question I googled around but couldn't find anything. Based on the picture, it seems to be 3 rows of 16 cores and then the top row they needed extra room for ((something)) so they could only fit 14 cores.
I'm not sure why it is 61 when I count 62, but I would guess one of the cores is dedicated to something particular process (e.g. coordinating the other cores maybe?) so it doesn't count.
I wanted to share an experience about this platform in the context of some concepts from Lecture 3. I worked on the Intel Xeon Phi platform during my undergrad thesis at ETH Zurich.
The Xeon Phi is a shared memory platform with 8GB RAM shared between all the cores, which can be upto 61 in number. The application at hand was implemented as a Kahn Process Network (KPN) - a particular kind of distributed model of computation - which parallelizes the application into processes. The processes then run on different cores of the Xeon Phi in parallel. The shared memory allows to do away the data copying involved in KPNs to a great extent, and was shown to achieve significant performance improvements. Such optimizations cannot be carried out on all multi-core platforms - the Intel’s SCC (Single-Chip Cloud Computer) which uses message passing buffers for communication between its cores is one such example.