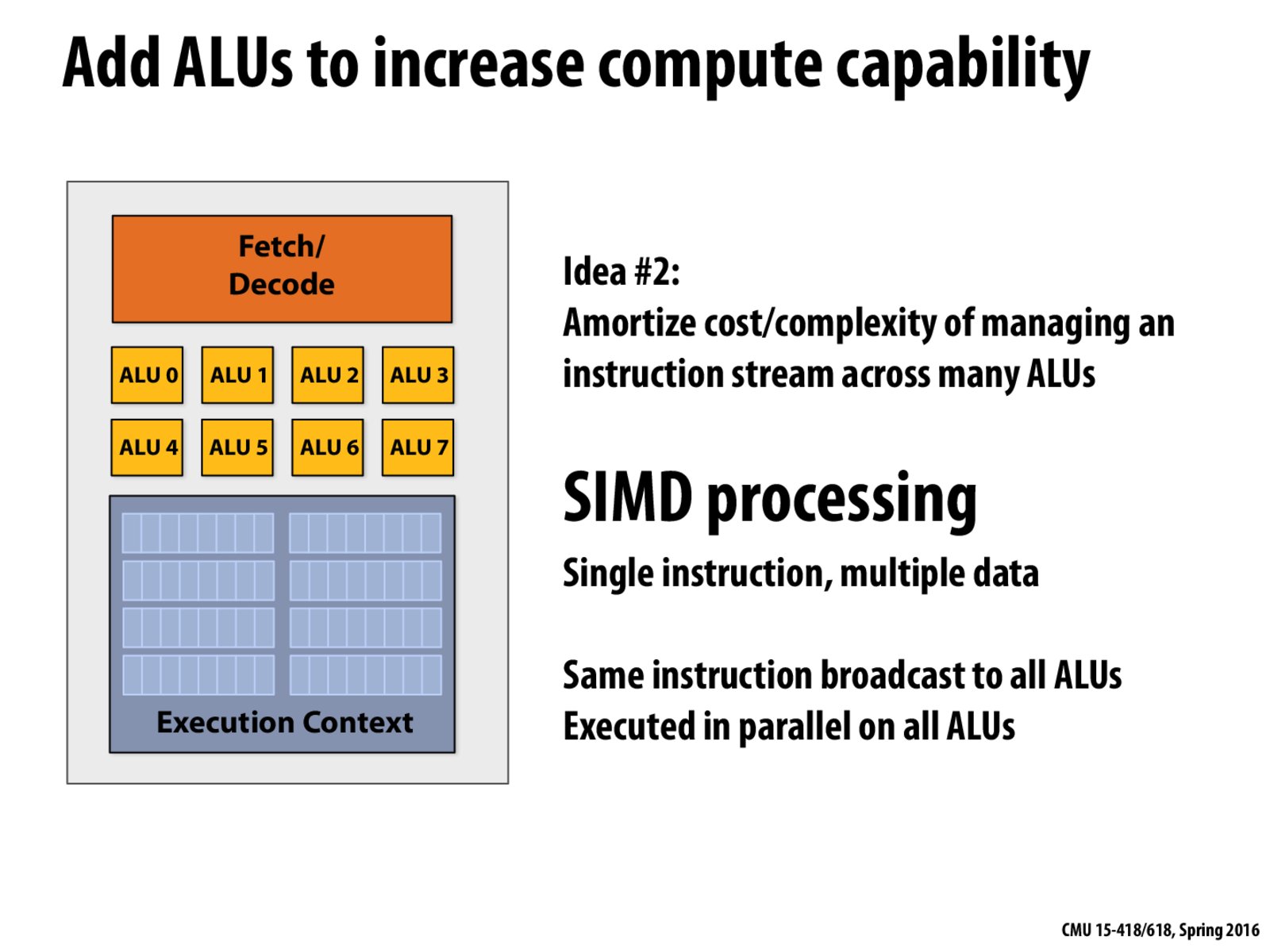
Does the data each ALU is operating on need to be adjacent in system memory? Or can each ALU operate on completely separate chunks?
TanXiaoFengSheng
@wcrougha From intel manual, the operands lie in some specialized registers for the SIMD instructions. So I guess they need to be contiguous. At least I guess they can't be any arbitrary chunks, otherwise the machine code would be tediously long.
gnunicorn
Initially I didn't understand how the context for each ALU could be made to differ, since every instruction runs on all the ALUs. (I.e., how do you 'seed' each context with the appropriate data inputs.) Is this accomplished with a masking technique similar to the mask for conditional execution described in slide 34?
RX
@gnunicorn
I don't think it uses masking technique, otherwise there is no parallelism at all. In my understanding, suppose the register is a wide register. Every time I issue a SIMD instruction, it will actually copy the input data from memory to this wide register. In CPU, the ALU will operate on different part of the wide register. Maybe this image help explain.
gnunicorn
@RX ahh I understand now, thank you for that explanation!
althalus
If there are multiple ALUs, is it possible to have either superscalar execution (since now we can have more arithmetic operations) or fewer SIMD instructions which use more ALUs?
rds
@athalus for Superscalar execution, you also need multiple Fetch/Decode Units because all ALUs are not necessarily executing the same instruction.
skylake
Initially through the lecture, I thought the design would be like a piece of the processor which would forward the "fetched instruction" to be executed to each of the ALUs. Thus I imagined a design wherein each thread would run on each of these ALUs (executing the common forwarded instruction), updating their respective execution states in parallel.
What would be demerit of such a processor design i.e. A number of threads running on each individual ALU units, all executing the same fetched instruction in synchronized fashion?
narainsk
I'm curious as to how vector operations deal with overflow. If I have two int vectors a,b and compute c = a*b, how does the processor ensure that no element of c overflows into other elements during the multiply?
thomasts
@narainsk I looked at some of the vector instructions, and it seems like many of the instructions avoid the problem by only dealing with smaller integers. For instance, the AVX2 instruction "__mm256_mul_epi32" only multiplies the low 32-bit integers from every 64 bits in the vector, and then stores the 64-bit results. I'm not sure if this is what all the integer-multiplication instructions do, however.
(Of course, floating-point operations don't have the same issues with overflow.)
xiaoguaz
Here I am curious about "Shared Ctx Data", why does this core need that? Does it provided the function described in lecture 2, slide 34 ?
Besides, if we want to make use of this kind of function, do we need special coding like ISPC? Can normal programs take advantage of SIMD?
Richard
So it seems that SIMD doesn't mean that an ALU can execute vector arithmetics, but means that there are several ALUs. So for AVX 512bit-width instructions, only CPUs with 512/32=16 ALUs can perform addition of 16 floating point elements using SIMD?
smoothcriminal
Does the number of ALU's always match the number of execution contexts/is it required so that we can run a thread on each ALU/execution context? Can we have more ALU's than execution contexts so that a thread can use multiple ALU units for ILP?
karima
@smoothcriminal
The execution context is no more than the set of registers used to store the state of a given thread of instructions. This includes the input/output values of all arithmetic operations currently in progress. Here, each ALU is allocated a subset of the registers available on an entire chip for its personal use.
Having more ALUs than registers is likely to hurt the ability of a processor to exploit ILP since x86 assembly instructions take two operands: a destination and a source, where at least one of the two must be a registerwiki.
Let me provide you with some concrete examples of how having fewer registers than ALUs inhibits a processor's ability to exploit ILP:
Say you have just one register per two ALUs. If you have two instructions that should be able to run in parallel (because each instruction's source operand does not depend on the other instruction's destination operand), unless both of them have destination operands that are memory locations and not registers, they cannot both execute at the same time because they would be writing the results of their computations out to the same register destination.
Furthermore, if each instruction has different source values, these cannot both be stored in the one register they share. So again, one instruction must wait until the other is done where it wouldn't have had to if we just had one more register.
An intuitive way to think about it is, if you have many workers each trying to do independent tasks, and they all require some desk space to do their work, having a smaller desk is going to inhibit their ability to all get their work done at the same time.
Typically the number of registers per ALU will be a constant factor greater than 1 for these reasons as well as the latency hiding reasons discussed in class.
smoothcriminal
@karima
But in this slide, it looks like there are 2 fetch/decode units used to determine which instructions can be run parallel, and there are 2 execution units so that we can run those instructions in parallel. In that example there is still only one execution context. This is why I assumed that it was ok to have more ALU's than register contexts so that we can implement ILP.
karima
@smoothcriminal
I can see how that slide might be confusing since it shows all registers lumped into one execution context. The previous slides from that lecture with just one ALU also show the same execution context image but don't get caught up on this (it's just a drawing!). The execution context gets bigger (has more registers) as you increase the number of ALUs.
Kayvon mentioned this in class. He said you can either consider it as one larger execution context given that we now have two execution units instead of 1 OR two separate execution contexts now, one for each execution unit. Either way, you now have twice as many registers on the same chip. consider it at one large execution context with wider registers inside.
kayvonf
Definitely consider it one execution context with 8x wider registers (e.g, 8x32=256 bits instead of 32 bits). I'll update the diagram to make this super clear when I get the chance.
karima
@smoothcriminal @kayvonf
Right sorry for the confusion/misquote. Part of my last comment was incorrect. You can think of the blue box as one larger execution context due to each register now being 8 times as wide.
In summary:
One thread of control gets one execution context.
Since the core on this slide as well as on this slide is not a multithreading capable core, we just have 1 execution context. There are 8 mini "Ctx" here on this slide because vector instructions use registers that are 8 times as wide as the registers used for scalar instructions.
The point I was trying to make is that the number of registers in a given execution context typically increases as we increase the number of ALUs on a chip. The number of execution contexts does not increase if we're not adding the capability to support multiple threads of control on one chip. But the number of registers is likely to increase to allow a chip to process independent instructions in parallel either on a superscalar chip or a SIMD capable chip.
So to answer your questions:
Does the number of ALU's always match the number of execution contexts/is it required so that we can run a thread on each ALU/execution context?
No, we can have more ALU's than execution contexts. On a superscalar processor, different instructions from the same thread of control can run on different ALUs, but they use the same execution context.
Can we have more ALU's than execution contexts so that a thread can use multiple ALU units for ILP
Yes, the number of ALU's can be more than the number of execution contexts as seen on this slide where we have one thread of control executing SIMD instructions. Each SIMD instruction uses multiple ALUs simultaneously (in this case, 8) to execute. We still have one execution context because the SIMD instructions are coming from one thread of instructions.
If we're talking about a superscalar processor with 2 ALUs and one execution context, then all instructions being run on the two ALUs come from the same thread of instructions but we can execute two different instructions from the same thread at the same time if there is ILP.
kayvonf
Refresh the page to see updated diagrams that make it clear there's only one execution context here.
Does the data each ALU is operating on need to be adjacent in system memory? Or can each ALU operate on completely separate chunks?
@wcrougha From intel manual, the operands lie in some specialized registers for the SIMD instructions. So I guess they need to be contiguous. At least I guess they can't be any arbitrary chunks, otherwise the machine code would be tediously long.
Initially I didn't understand how the context for each ALU could be made to differ, since every instruction runs on all the ALUs. (I.e., how do you 'seed' each context with the appropriate data inputs.) Is this accomplished with a masking technique similar to the mask for conditional execution described in slide 34?
@gnunicorn
I don't think it uses masking technique, otherwise there is no parallelism at all. In my understanding, suppose the register is a wide register. Every time I issue a SIMD instruction, it will actually copy the input data from memory to this wide register. In CPU, the ALU will operate on different part of the wide register. Maybe this image help explain.
@RX ahh I understand now, thank you for that explanation!
If there are multiple ALUs, is it possible to have either superscalar execution (since now we can have more arithmetic operations) or fewer SIMD instructions which use more ALUs?
@athalus for Superscalar execution, you also need multiple Fetch/Decode Units because all ALUs are not necessarily executing the same instruction.
Initially through the lecture, I thought the design would be like a piece of the processor which would forward the "fetched instruction" to be executed to each of the ALUs. Thus I imagined a design wherein each thread would run on each of these ALUs (executing the common forwarded instruction), updating their respective execution states in parallel.
What would be demerit of such a processor design i.e. A number of threads running on each individual ALU units, all executing the same fetched instruction in synchronized fashion?
I'm curious as to how vector operations deal with overflow. If I have two int vectors a,b and compute c = a*b, how does the processor ensure that no element of c overflows into other elements during the multiply?
@narainsk I looked at some of the vector instructions, and it seems like many of the instructions avoid the problem by only dealing with smaller integers. For instance, the AVX2 instruction "__mm256_mul_epi32" only multiplies the low 32-bit integers from every 64 bits in the vector, and then stores the 64-bit results. I'm not sure if this is what all the integer-multiplication instructions do, however.
(Of course, floating-point operations don't have the same issues with overflow.)
Here I am curious about "Shared Ctx Data", why does this core need that? Does it provided the function described in lecture 2, slide 34 ? Besides, if we want to make use of this kind of function, do we need special coding like ISPC? Can normal programs take advantage of SIMD?
So it seems that SIMD doesn't mean that an ALU can execute vector arithmetics, but means that there are several ALUs. So for AVX 512bit-width instructions, only CPUs with 512/32=16 ALUs can perform addition of 16 floating point elements using SIMD?
Does the number of ALU's always match the number of execution contexts/is it required so that we can run a thread on each ALU/execution context? Can we have more ALU's than execution contexts so that a thread can use multiple ALU units for ILP?
@smoothcriminal
The execution context is no more than the set of registers used to store the state of a given thread of instructions. This includes the input/output values of all arithmetic operations currently in progress. Here, each ALU is allocated a subset of the registers available on an entire chip for its personal use.
Having more ALUs than registers is likely to hurt the ability of a processor to exploit ILP since x86 assembly instructions take two operands: a destination and a source, where at least one of the two must be a register wiki.
Let me provide you with some concrete examples of how having fewer registers than ALUs inhibits a processor's ability to exploit ILP:
Say you have just one register per two ALUs. If you have two instructions that should be able to run in parallel (because each instruction's source operand does not depend on the other instruction's destination operand), unless both of them have destination operands that are memory locations and not registers, they cannot both execute at the same time because they would be writing the results of their computations out to the same register destination.
Furthermore, if each instruction has different source values, these cannot both be stored in the one register they share. So again, one instruction must wait until the other is done where it wouldn't have had to if we just had one more register.
An intuitive way to think about it is, if you have many workers each trying to do independent tasks, and they all require some desk space to do their work, having a smaller desk is going to inhibit their ability to all get their work done at the same time.
Typically the number of registers per ALU will be a constant factor greater than 1 for these reasons as well as the latency hiding reasons discussed in class.
@karima
But in this slide, it looks like there are 2 fetch/decode units used to determine which instructions can be run parallel, and there are 2 execution units so that we can run those instructions in parallel. In that example there is still only one execution context. This is why I assumed that it was ok to have more ALU's than register contexts so that we can implement ILP.
@smoothcriminal
I can see how that slide might be confusing since it shows all registers lumped into one execution context. The previous slides from that lecture with just one ALU also show the same execution context image but don't get caught up on this (it's just a drawing!). The execution context gets bigger (has more registers) as you increase the number of ALUs.
Kayvon mentioned this in class. He said you can
either consider it as one larger execution context given that we now have two execution units instead of 1OR two separate execution contexts now, one for each execution unit. Either way, you now have twice as many registers on the same chip.consider it at one large execution context with wider registers inside.Definitely consider it one execution context with 8x wider registers (e.g, 8x32=256 bits instead of 32 bits). I'll update the diagram to make this super clear when I get the chance.
@smoothcriminal @kayvonf
Right sorry for the confusion/misquote. Part of my last comment was incorrect. You can think of the blue box as one larger execution context due to each register now being 8 times as wide.
In summary:
One thread of control gets one execution context.
Since the core on this slide as well as on this slide is not a multithreading capable core, we just have 1 execution context. There are 8 mini "Ctx" here on this slide because vector instructions use registers that are 8 times as wide as the registers used for scalar instructions.
The point I was trying to make is that the number of registers in a given execution context typically increases as we increase the number of ALUs on a chip. The number of execution contexts does not increase if we're not adding the capability to support multiple threads of control on one chip. But the number of registers is likely to increase to allow a chip to process independent instructions in parallel either on a superscalar chip or a SIMD capable chip.
So to answer your questions:
Does the number of ALU's always match the number of execution contexts/is it required so that we can run a thread on each ALU/execution context?
No, we can have more ALU's than execution contexts. On a superscalar processor, different instructions from the same thread of control can run on different ALUs, but they use the same execution context.
Can we have more ALU's than execution contexts so that a thread can use multiple ALU units for ILP Yes, the number of ALU's can be more than the number of execution contexts as seen on this slide where we have one thread of control executing SIMD instructions. Each SIMD instruction uses multiple ALUs simultaneously (in this case, 8) to execute. We still have one execution context because the SIMD instructions are coming from one thread of instructions.
If we're talking about a superscalar processor with 2 ALUs and one execution context, then all instructions being run on the two ALUs come from the same thread of instructions but we can execute two different instructions from the same thread at the same time if there is ILP.
Refresh the page to see updated diagrams that make it clear there's only one execution context here.