For 2D array layout, each processor may load data not needed when processing boundary points because a cache line may correspond to multiple consecutive points. However, in 4D array layout, the problem is solved by better spatial locality.
grarawr
Is this the general case for grid layouts? Are there cases where maybe the 2D array layout has more benefits compared to the 4D because of the algorithm?
MaxFlowMinCut
@grarawr I think it depends on the size and associativity of the cache, and the way data is being accessed. If an entire row fits in a cache line and the algorithm is iterating over each row then the 2D array layout might be faster than the block layout.
lol
Check out Z-morton ordering. It maps higher dimensional data to one dimension while preserving locality.
efficiens
@grarawr if you have a very big cache line then the 1st approach (2D row-major layout) may be better in some situations.
fleventyfive
I think the discussion so far on this slide shows how important it is to build hardware-aware code (here, hardware=cache hierarchy). So, even if we have a 2D row-major array layout, and we can create grids that align with cache lines, the "layout" of the array can no longer be a problem.
cmusam
@efficiens Agreed. The critical working sets are different for different algorithms. To improve spatial locality, we should think about how the data is traversed when reordering out data.
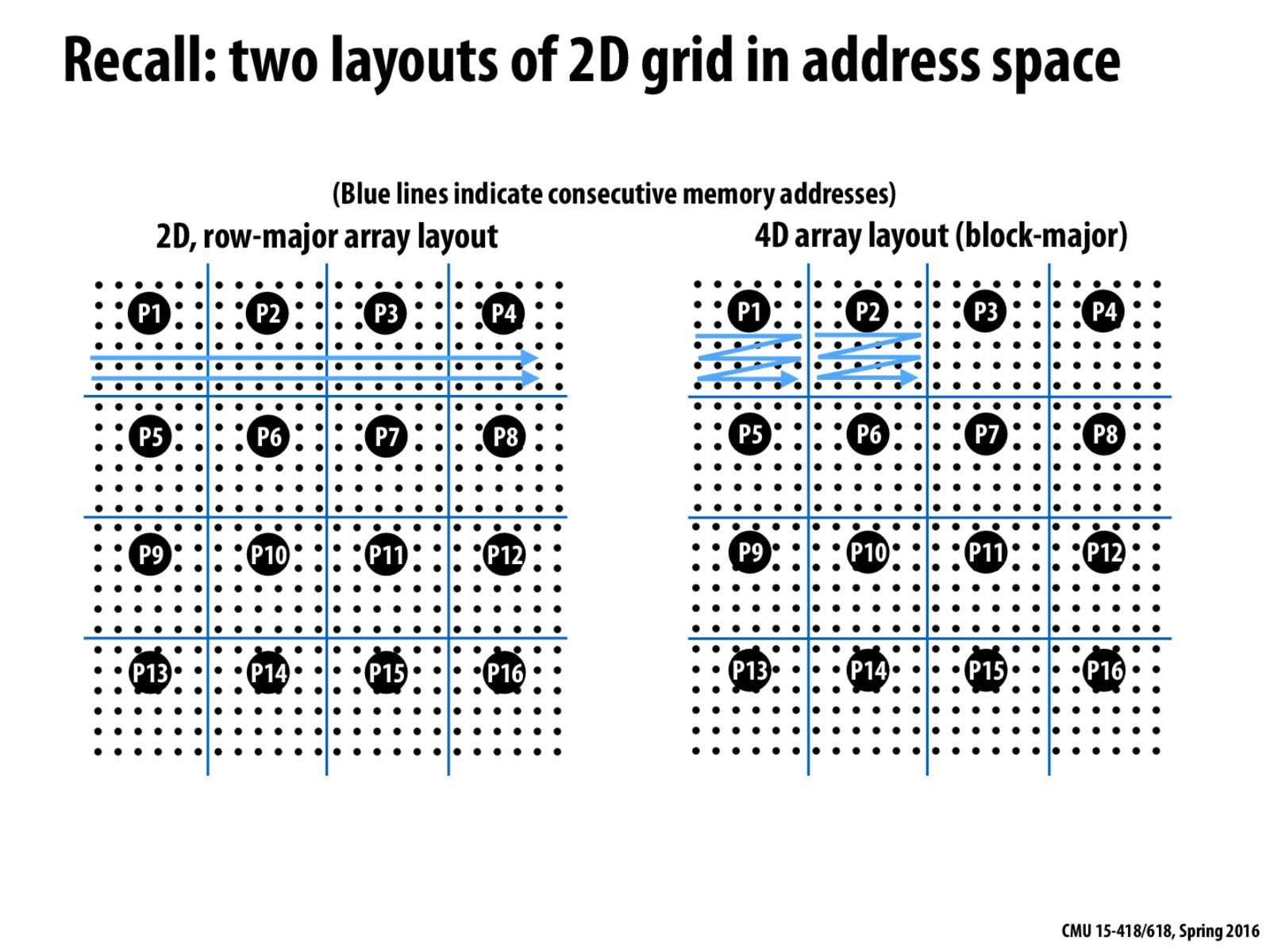
For 2D array layout, each processor may load data not needed when processing boundary points because a cache line may correspond to multiple consecutive points. However, in 4D array layout, the problem is solved by better spatial locality.
Is this the general case for grid layouts? Are there cases where maybe the 2D array layout has more benefits compared to the 4D because of the algorithm?
@grarawr I think it depends on the size and associativity of the cache, and the way data is being accessed. If an entire row fits in a cache line and the algorithm is iterating over each row then the 2D array layout might be faster than the block layout.
Check out Z-morton ordering. It maps higher dimensional data to one dimension while preserving locality.
@grarawr if you have a very big cache line then the 1st approach (2D row-major layout) may be better in some situations.
I think the discussion so far on this slide shows how important it is to build hardware-aware code (here, hardware=cache hierarchy). So, even if we have a 2D row-major array layout, and we can create grids that align with cache lines, the "layout" of the array can no longer be a problem.
@efficiens Agreed. The critical working sets are different for different algorithms. To improve spatial locality, we should think about how the data is traversed when reordering out data.